回顧資料架構技術發展,大數據以及機器學習(ML)的發展是兩個重要的轉捩點,前者是驅動資料倉儲(Data Warehouse)走向資料湖(Data Lake)的關鍵,隨著大量半結構化和非結構化資料的分析需求不斷增長,企業需要尋求新架構來加以因應,包含MapReduce、Hadoop、NoSQL都是盛極一時的技術寵兒。不過,資料湖雖能廣納百川,將所有的資料以原始的型態存放,以方便後續分析與使用。但若沒有經過適當的管理,想要在充滿雜亂且重複的資料中,萃取出資料的價值與洞察,也會變得複雜與困難,尤其是機器學習、人工智慧等新型應用時更是如此,故而催生出資料湖倉(Data Lakehouse)新架構。
資料一致性與品質是資料湖的缺限
HPE慧與科技技術規劃處副總經理范欽輝指出,資料倉儲的優點是能夠快速地擷取資料、分析,並迅速取得結果。由於預先定義了資料結構以及結構描述,因而能對SQL做最佳化,優化查詢速度。但也因為需要高速查詢以提供即時的商業情報,基礎架構所需耗費的成本並不低,一旦資料量越大,支付的成本代價就會越高昂。
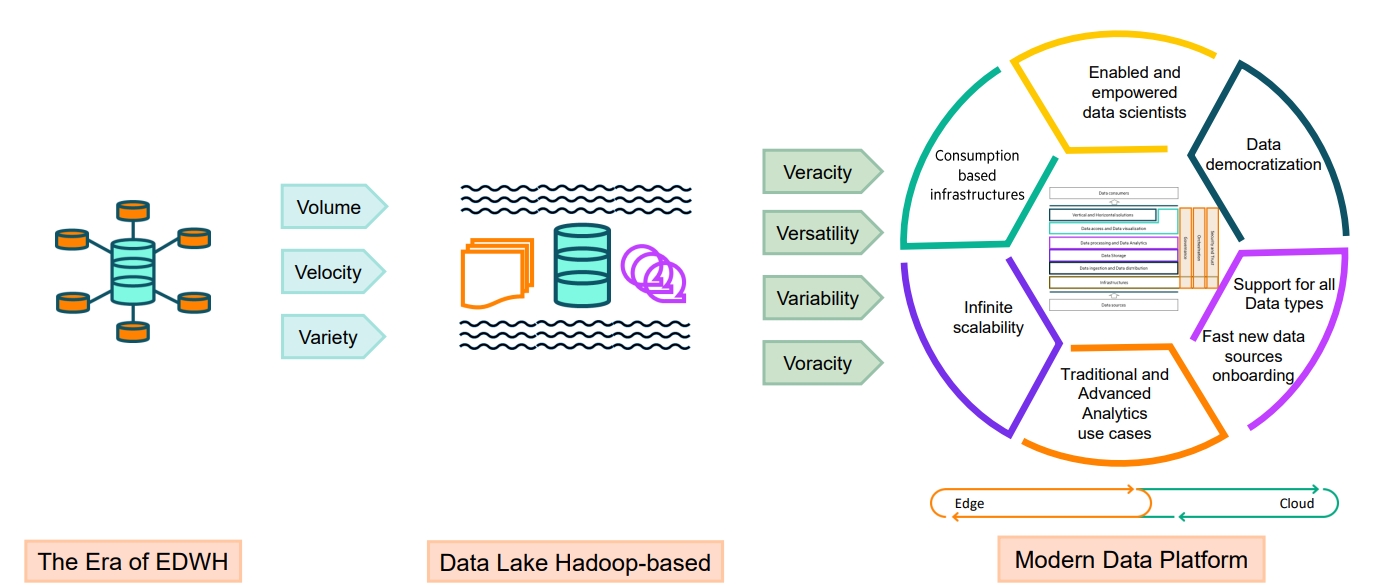 資料平台現代化的旅程。(資料來源: HPE)
資料平台現代化的旅程。(資料來源: HPE)
而資料湖的特色即是允許儲存大量原始、非結構化數據,使用時只要到資料湖中擷取就好,非常適合大數據分析、機器學習以及AI運用。然而,資料的品質與一致性一直是資料湖的硬傷,「資料湖在架構設計上原本就不想處理資料的一致性問題,」他以轉帳匯款為例進行說明,當民眾在轉帳匯款時,在自己的帳戶先扣一筆,轉帳成功後,對方的帳戶也會加上一筆,如果轉帳失敗,那麼就要把這筆款項從對方帳戶扣掉,這就是資料的一致性。資料倉儲可以很輕鬆地就做到資料一致性,但是資料湖是並沒有這個概念,扣款還是扣款,添加還是添加,至於轉帳沒有成功則是後面再來處理的事情。
資料架構各有千秋 視應用判定處理
為了克服資料倉儲與資料湖既有架構的侷限,資料湖倉將資料湖的靈活性與資料倉儲的結構化功能結合,為儲存和分析各種結構化和非結構化資料提供統一的平台。其能解決Data Lake資料準確性的問題,簡單地說,就是能滿足ACID,即不可分割性(Atomicity)、一致性(Consistency)、隔離性(Isolation)以及耐久性(Durability),來保證交易正確可靠。而在資料倉儲缺乏的可延展性與資料多樣性方面,資料湖倉採用了雲原生架構,因而具備橫向擴展的能力,同時也採用開放標準,以便讓更多不同的應用服務來存取。
「台灣企業對Data Lakehouse較感興趣的時間點,大概就是近半年左右。雖然,不少人認為Data Lakehouse補足了資料倉儲以及資料湖的不足之處,屆時只需要保留資料倉儲一套即可,但實務上很難完全取代。」范欽輝認為,這三種資料架構都各自有其存在的必要性,只是企業看重的地方不一樣。舉例而言,資料倉儲對某些企業的重要性非常高,特別是採用了特定技術,必須產出成千上萬個報告的企業而言更是如此,除非是支付不起資料倉儲的授權費,否則多數企業會抱持著寧可不冒險的心態。
 HPE慧與科技技術規劃處副總經理范欽輝(右)認為,未來,資料的使用與資料的存放會逐漸脫離開來,資料倉儲與資料湖倉可以在資料的使用層面施力,而資料的儲存還是會以物件儲存為主流。左為HPE慧與科技雲端商業服務部業務開發經理吳思為。
HPE慧與科技技術規劃處副總經理范欽輝(右)認為,未來,資料的使用與資料的存放會逐漸脫離開來,資料倉儲與資料湖倉可以在資料的使用層面施力,而資料的儲存還是會以物件儲存為主流。左為HPE慧與科技雲端商業服務部業務開發經理吳思為。
同樣地,資料的多樣性是資料湖無法被取代的優勢,倘若企業內部有許多語音檔,並不必然需要透過資料湖倉,因為在資料湖倉的應用中,許多都是資料表(Table)的應用,在此情況下,資料湖或許會更適合。
他提到,企業環境中往往充滿了複雜的資料源與資料流,企業內部資料可能來於機器設備、交易系統或外部資料,這些資料透過不同的方法進到系統裡面,最終進入到企業資料架構。有些不需要預處理、清理和轉換的資料就可以存放到資料倉儲,有些則會先進入到資料湖,經擷取、轉換和載入(ETL)後再提供給資料倉儲,「因此,最為可能的應用場景是,依據不同的資料流,而給予不一樣的處理方式。而未來,資料的使用與資料的存放會逐漸脫離開來,資料倉儲與資料湖倉可以在資料的使用層面施力,而資料的儲存還是會以物件儲存為主流。」
細說資料湖倉三大精神
為了讓資料湖倉在成本以及可擴展性之間取得平衡,HPE以Ezmeral Data Fabric來協助企業建構現代化的資料架構,其包含了開放、可橫向擴展以及統一資料平台等三個精神,其中開放指的是可存放多樣的資料來源,而統一資料平台則是能以單一平台來儲存與管理所有的資料。」
HPE慧與科技雲端商業服務部業務開發經理吳思為補充,像是近期相當熱門的ChatGPT其實也是驅動資料湖倉的發展因素之一,當要進行大型語言模型訓練時,會使用到大量的語料,例如Word檔、PDF或是純文字檔等等,此外還有很多存在表格裡面的結構化資料,這時必須要有資料湖倉這樣的統一平台來因應資料擷取的需求,單一資料湖或是資料倉儲並無法做到。
「另外,開放也很重要,」他繼續說明,大型語言模型在預處理的過程中,技術上是需要把資料進行向量轉換,一些新科技套件或是軟體,若要能夠很有效率地與原有的資料平台進行介接,其實是需要一個相對開放、雲原生的架構才能夠支持這樣的應用,換句話說,資料湖倉因為夠開放,才能與許多新的開源碼套件或工具進行介接,以支援新的AI應用。
HPE Ezmeral Data Fabric是統一的資料湖倉,其能打破資料孤島並管理所有不同資料來源與格式的資料。過往企業面對各種不同型態的資料時,須建立各種不同的儲存池,以便讓資料在不同的系統內流動,但這種方式反而會對基礎架構造成負擔,而HPE Ezmeral Data Fabric的儲存層因為透過API支援了各種不同的通訊協定,如S3、HDFS、REST,甚至是NFS,因此無須移動資料,便可以為應用程式提供文件檔案、映像檔、視訊、物件、表格和串流等資料。
而且還能在混合雲環境自動進行熱、溫、冷資料分層,設定最佳化效能、容量或儲存成本的策略,為不同資料提供最佳的資料管理。此外,也支援各種運算工具與框架,如Hadoop、Spark、TensorFlow和Caffe。
范欽輝解釋,為何在資料湖倉的架構中非常強調雲原生,目的就是為了鬆散耦合(Loosely-coupled),舉例來說,HPE Ezmeral Data Fabric也支援Iceberg及Delta Lake,過往在企業架構中一定會先決定要採用Iceberg還是Delta Lake,但是現在企業的想法已經與以往不同,他們會認為,為什麼非得要從中做選擇,乾脆兩個都擁有,讓資料科學家自己決定,「這就是開放架構的好處,因為Iceberg、Delta Lake與底層的儲存架構基本上是脫勾的,因此從Iceberg轉換到Delta Lake並不會有太多的障礙,甚至未來如果有新的技術或工具時,也可以直接運用底層架構。」