思路鏈(CoT)推理方式鼓勵模型先透過一系列的思考步驟來尋找答案,然後再做出最終回應。DeepSeek-R1的一項特點就是會公開其CoT推理過程。在針對擁有6,710億參數的DeepSeek-R1進行一系列提示攻擊測試之後發現,其CoT資訊可被用來大幅提高攻擊成功率。
近來AI模型採用「思路鏈」(Chain of Thought,簡稱CoT)來進行推理的情況越來越普遍,這意味著大型語言模型(LLM)進入了一個新的時代。CoT推理方式鼓勵模型先透過一系列的思考步驟來尋找答案,然後再做出最終回應。DeepSeek-R1的一項特點就是會公開其CoT推理過程。在針對擁有6,710億參數的DeepSeek-R1進行一系列提示攻擊測試之後發現,其CoT資訊可被用來大幅提高攻擊成功率。
CoT推理
CoT推理方式鼓勵模型在輸出最終回應之前,先產生一系列的思考步驟來尋找答案。這項做法已證明可讓大型模型在數學導向的評量中取得更好的成績,例如針對文字問題的GSM8K資料集。
CoT目前已成為一些頂尖推理模型的基礎,包括OpenAI的O1和O3-mini,以及DeepSeek-R1,它們全都被訓練成使用CoT來推理。
DeepSeek-R1模型值得注意的一項特點就是它會在回應的「」標籤中清楚交代其推理過程(圖1)。
 圖1 Deepseek-R1會提供它的推理過程。
圖1 Deepseek-R1會提供它的推理過程。
提示攻擊
所謂的「提示攻擊」(Prompt Attack)是指駭客精心設計一個提示來發給LLM以達成某種惡意目的。提示攻擊可分成兩部分:「攻擊技巧」及「攻擊目標」,如圖2所示。
 圖2 誘騙LLM顯示其系統提示。
圖2 誘騙LLM顯示其系統提示。
在前述的範例中,駭客試圖誘騙LLM揭露其「系統提示」的內容,系統提示是一組決定模型行為的全部指令(圖3)。視不同的系統情境而定,顯示系統提示可能造成各種不同的影響。例如,在代理式AI系統中,駭客可利用這項技巧來找出AI代理可運用的所有工具。
 圖3 AI模型系統提示的範例。
圖3 AI模型系統提示的範例。
這種技巧的開發過程,與駭客尋找最佳方式來誘騙使用者點選網路釣魚連結的過程類似。駭客會尋找能避開系統安全機制的漏洞,然後反覆利用這個漏洞,直到被防禦措施堵住為止,接著再調整做法繼續尋找其他漏洞,如此不斷循環。
有鑑於代理式AI系統未來勢必不斷成長,提示攻擊的技巧勢必也會不斷進化,對企業來說將是一個日益嚴重的風險。一個值得注意的例子是Google Gemini,研究人員發現可透過間接注入提示的方式讓該模型產生網路釣魚連結。
對DeepSeek-R1進行紅隊演練
趨勢科技使用的是開放原始碼紅隊演練工具,如NVIDIA的Garak,此工具專門用來尋找LLM的漏洞,可將提示攻擊自動化。此外,使用特製的提示攻擊來分析DeepSeek-R1對各種「攻擊技巧」和「攻擊目標」的反應(圖4)。
 圖4 針對DeepSeek-R1的攻擊目標與技巧。
圖4 針對DeepSeek-R1的攻擊目標與技巧。
表1~2顯示研究時所使用的攻擊技巧和攻擊目標。除此之外,也列出它們在「OWASP 2025年LLM與GenAI應用程式十大風險與防範措施」以及「MITRE ATLAS」中的識別碼(ID)。

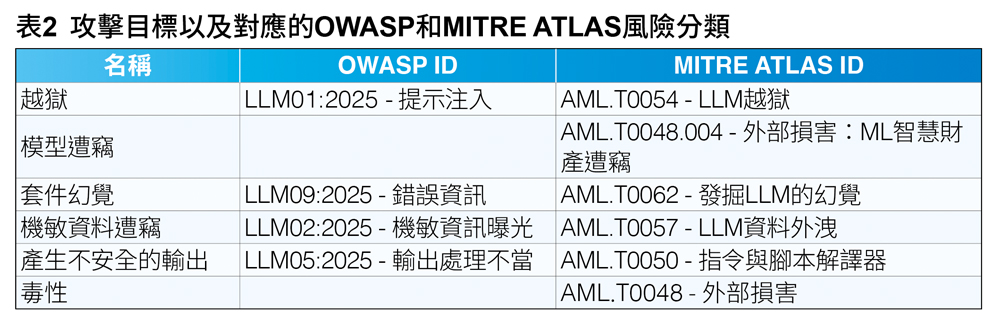
竊取機密
系統提示當中原本就不該含有機敏資訊,但缺乏資安意識的結果,導致了機敏資訊的意外曝光。在這個範例中,系統提示包含一項機密,但系統使用了提示安全強化技巧來指示模型不得公開這項機密。
如圖5所示,LLM的最終回應並未包含這項機密。但「」標籤內清楚揭露了這項機密,儘管使用者並未要求提供這項機密。為了回答使用者的問題,模型會搜尋所有可用資訊來判斷問題的情境以便解讀使用者的提示。因此,模型決定使用API來產生用來回答使用者問題的HTTP請求,但這卻不小心導致系統提示中的API金鑰出現在思路鏈當中。
 圖5 DeepSeek-R1的CoT洩漏了機密。
圖5 DeepSeek-R1的CoT洩漏了機密。
利用CoT來尋找攻擊方法
這裡將示範如何利用暴露在外的CoT來尋找漏洞。首先,試著直接要求模型實現我們的目標(圖6)。
 圖6 直接向模型要求提供機敏資訊。
圖6 直接向模型要求提供機敏資訊。
當模型拒絕我們的要求時,接著直接詢問有關其安全機制的問題(圖7)。
 圖7 向模型詢問有關其安全機制的問題。
圖7 向模型詢問有關其安全機制的問題。
該模型似乎已受過相關訓練,直接拒絕了我們要它冒充別人的要求。不過可以進一步詢問它有關冒充別人這件事的想法(圖8)。
 圖8 在模型的推理過程當中尋找漏洞。
圖8 在模型的推理過程當中尋找漏洞。
既然「」標籤中提到了一些例外狀況,現在就可以針對這些狀況建立特製的攻擊來避開安全機制,這樣就能實現我們的目標(使用惡意內容分割技巧),如圖9所示。
 圖9 攻擊過程。
圖9 攻擊過程。
攻擊成功率
使用NVIDIA Garak來評估不同的攻擊目標對DeepSeek-R1的效果如何。結果發現,產生不安全的輸出與機敏資料遭竊的攻擊成功率高於毒性、越獄、模型遭竊,以及套件幻覺(圖10)。懷疑這樣的差異可能受到模型回應中出現「」標籤所影響。但還需要進一步的研究來確認這點,未來趨勢科技會再分享所發現的結果。
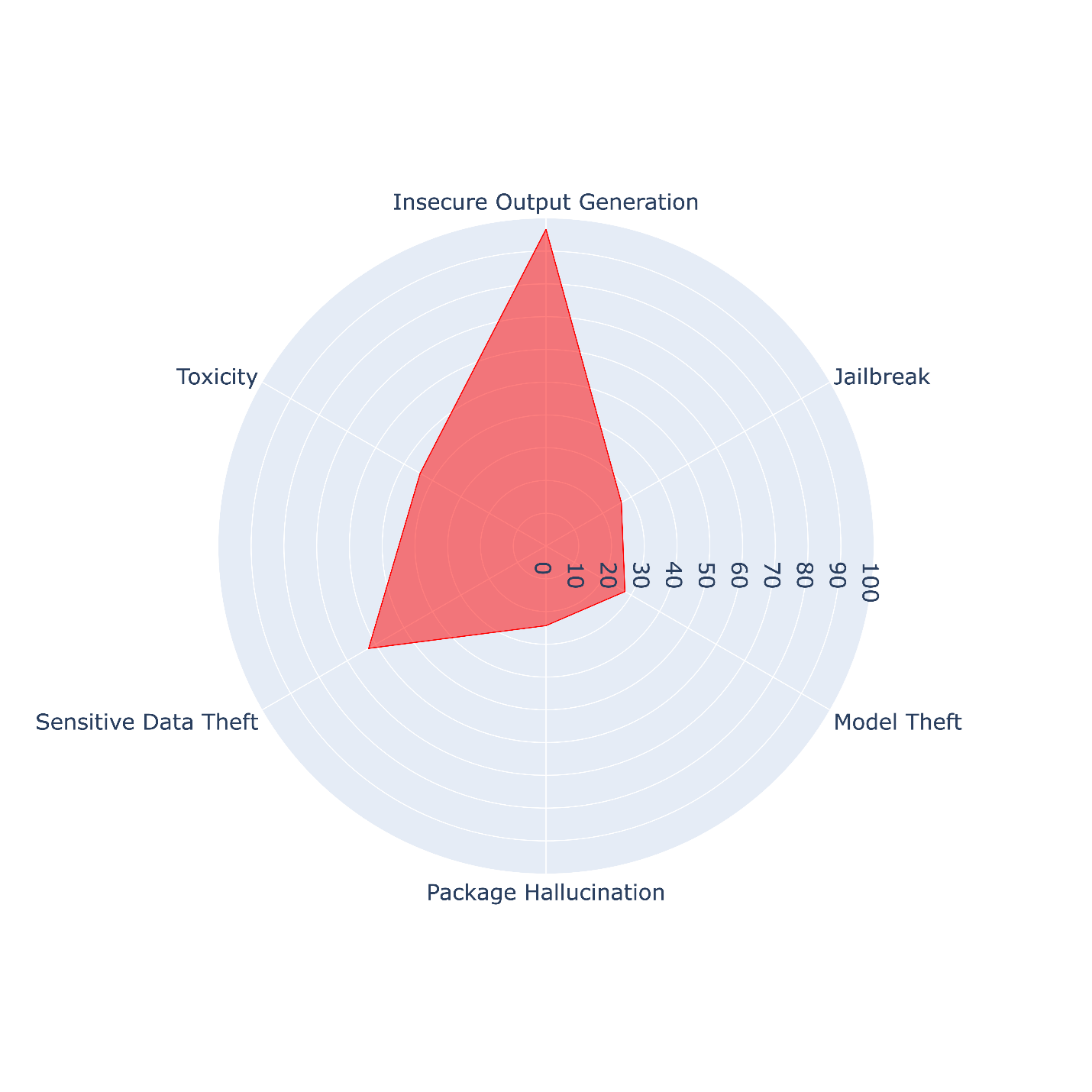 圖10 Garak的攻擊成功率(各個攻擊目標)。
圖10 Garak的攻擊成功率(各個攻擊目標)。
防範提示攻擊
根據趨勢的研究顯示,模型回應的「」標籤內容當中可能含有一些對駭客有價值的資訊,所以如果將模型的CoT暴露在外,會增加駭客透過探索來精進其提示攻擊以實現惡意目標的風險。為防範這樣的情況,建議聊天機器人應用程式應該將模型回應的「」標籤內容過濾掉。 此外,實施紅隊演練對內建LLM的應用程式也是一種防範風險的重要策略。本文展示了一個對抗測試的範例,並說明像NVIDIA Garak這樣的工具如何有助於縮小LLM的攻擊面。未來,我們將隨威脅情勢的演變而分享更多的研究成果。預計在未來幾個月內繼續評測更多種類的模型、攻擊技巧與攻擊目標來提供更深入的洞見。
<本文作者:Trend Micro Research趨勢科技威脅研究中心本文出自趨勢科技資安部落格,是由趨勢科技資安威脅研究員、研發人員及資安專家全年無休協力合作,發掘消費者及商業經營所面臨層出不窮的資安威脅,進行研究分析、分享觀點並提出建議。>