多代理式AI系統在解釋性、可靠性和信賴度方面帶來新挑戰。在檢視代理式AI系統的思維鏈(CoT)推理時發現,儘管這些系統生成的結果看似具說服力且邏輯清晰,並能解釋其如何得出結論,然而在推理過程仍可能存在錯誤且具誤導性。
英特爾實驗室近期研究發現,多代理式AI系統在解釋性、可靠性和信賴度方面帶來新挑戰。研究團隊在檢視代理式AI系統的思維鏈(Chain-of-Thought,CoT)推理時發現,儘管這些系統生成的結果看似具說服力且邏輯清晰,並能解釋其如何得出結論,然而在推理過程仍可能存在錯誤且具誤導性。這項《未經思考的想法:透過代理式流程重新審視大型語言模型中思維鏈推理的解釋價值》(Thoughts without Thinking: Reconsidering the Explanatory Value of Chain-of-Thought Reasoning in LLMs through Agentic Pipelines)研究,發表於日本ACM CHI 2025 Human-Centered Explainable AI工作坊。研究深入探討了代理式流程中的推理,並發現某些意圖培養信任的策略,例如CoT推理,反而可能適得其反,阻礙信任建立。
目前最領先的AI系統不再侷限於大型語言模型(LLM),而是往多重代理式AI系統發展。這些系統由多個獨立的LLM組成,其中每個LLM都被設計成一個代理(Agent),並透過專門的元提示(Meta Prompts)和行為指令進行運作。這些代理會被串聯成一道流程,前一個代理的輸出會成為下一個代理的輸入。每個LLM代理都扮演著專業角色:有些負責感知輸入、有些是規劃者、有些則負責檢查檢索增強生成(RAG)文件,甚至還有專門負責安全檢查的代理。每個代理所產生的查詢、資料、輸入及輸出,都會依序經過這些流程。
由於流程中的每個代理鮮少受到人類監督,因此信任和透明度的問題變得更加迫切。儘管這些代理流程有望產生更全面、徹底且有根據的輸出,但也同時帶來新挑戰。
思維鏈不等於可解釋性
CoT推理被譽為一種為生成式AI系統帶來可解釋性和透明度的新方法。它的核心概念是要求LLM寫下其推理過程或得出答案的步驟,這就像要求學生在思考問題時,將其推理過程大聲說出來,以便得出答案。
理論上,這種透明度有助於使用者信任系統的輸出結果,因為他們可以看到並驗證系統得出結論的步驟。然而,在實際的代理流程(即多個LLM接收、推理並生成內容的過程)中,CoT仍須改進,才能真正實現其承諾的「萬靈丹」效果。
英特爾實驗室正在開發MARIE系統,該系統是應用於支援半導體製造技術人員手動操作的任務指導系統。在此領域中,英特爾已對代理架構進行測試,並透過實驗評估CoT在實際場景中的運作情況。同時也整理了來自晶圓廠中實際技術人員訪談所收集到的問題,其中包括:
‧任務導向問題:例如這一步我應該使用什麼工具?
‧組織∕社交問題:例如我應該聯繫誰尋求IT協助?
我們將這些問題視為一種「參與式基準」,用來評估CoT推理能否為技術人員提供更有用的答案,或者更清楚地解釋系統是如何得出其輸出結果。在實驗中,使用了Assembly 101這個以任務為基礎的資料集,它以動手操作實體玩具的建構過程模擬晶圓廠數據,以此測試CoT在支援晶圓廠技術人員方面的表現(圖1)。
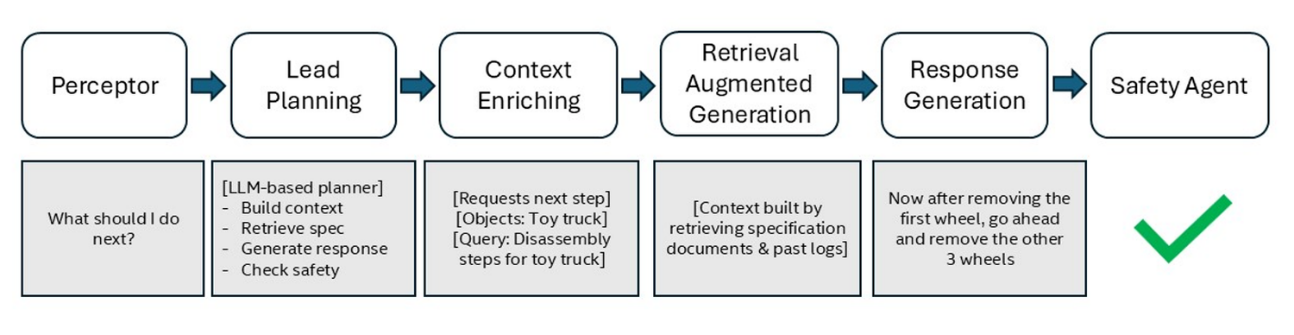 圖1 根據使用者輸入的查詢類型,代理流程範例會有所不同。一旦問題被接收,主要規劃器會生成一個包含一系列代理呼叫的計畫,流程中每個代理的輸出結果都將顯示於此。
圖1 根據使用者輸入的查詢類型,代理流程範例會有所不同。一旦問題被接收,主要規劃器會生成一個包含一系列代理呼叫的計畫,流程中每個代理的輸出結果都將顯示於此。
令人驚訝的結果:無需解釋的解釋
在許多情況下,即使CoT給出的解釋看似合理,實際上卻可能是錯誤或誤導。我們將這種情境稱為「缺乏解釋性的解釋」。舉例來說,某個系統在描述玩具垃圾車的零件時,使用了諸如「離合器」和「變速箱」這類通常與實際全尺寸車輛相關的術語。由於該系統完全忽略玩具和玩耍的背景資訊,這種誤解導致它錯誤地重新定義了範圍、細節和任務。系統的CoT推理似乎為了填滿其上下文視窗(Context Window)而被迫持續生成文本,這反而鼓勵它產生原本可能不會出現的多餘、不正確且具誤導性的資訊。
另一種假設認為,LLM容易陷入「思維定勢」(Einstellung Paradigm)的困境。這代表LLM可能過度專注於熟悉或常見的方法,反而導致偏離正確的策略。例如「大多數汽車發不動是因為電池沒電。因此,如果汽車無法發動,換顆電池就行了。」這種推理方式,卻在透過代理流程執行參與式基準測試時一再出現。
CoT的不足之處,嚴重影響了人機協作中信任關係的建立。一般使用者無論是出於單純的好奇心,或是因為AI系統輸出出現幻覺或錯誤,都不可避免地會去探究AI系統是如何得出結論。如果他們發現CoT提供的理由具有誤導性或不正確,不僅會損害他們對AI的信任,而且這種信心也將難以恢復。
代理流程:權力須謹慎監督
多代理流程(Multi-agent Pipeline)是一種精密的架構,將感知(Perception)、規劃(Planning)以及行動(Action)代理組合成一個LLM團隊。這個系統能夠處理各種任務並利用外部資源,例如解讀多模態和視覺輸入、檢查相關文件,甚至能夠透過指定的代理檢查回應的安全性。CoT推理可闡明這些代理,並促使每個代理解釋它對這條推理鏈中的下一個代理「說了什麼」。
這項設置應能提高透明度:每個代理的輸出結果都會公開展示,揭示整個系統所產生輸出的關鍵資訊。然而,在實際操作中,代理之間的交接就像是傳聲筒遊戲。任何誤解、錯誤和不理解都會在系統中層層傳遞,並在最終輸出時被放大。由於推理鏈中的每個環節都依賴於LLM生成的輸出結果,因此當錯誤以令人驚訝且難以察覺的方式浮現並累積時,CoT的原理可能會變得特別混亂。
思維的假象:CoT從三個方面阻礙解釋性
除了針對「代理流程」回答來自參與式基準資料集的問題表現進行定量分析外,英特爾也針對有問題的輸出結果進行了定性內容分析,並同時採用「大型語言模型評判法」(LLM-as-a-Judge)。在這次的分析中,一個主題浮現而出,那就是CoT製造了一種深思熟慮的假象。即使輸出結果完全錯誤,模型冗長的解釋仍可能因為聽起來言之有理,而說服他人相信答案是準確的。
在一個案例中,系統錯誤地聲稱無法以多種語言回應。然而,測試提示卻顯示它可以做到。CoT不僅堅持這項錯誤的主張,甚至進一步為其立場辯護,這說明了系統的CoT可能阻礙解釋性的三種方式:
1. 系統將不實資訊視為事實,導致誤導性的解釋產生。
2. 系統根據可讀取文件中較為容易理解的內容,犯了以偏概全的邏輯錯誤,進而導致解釋不完整。
3. 使用者需要瀏覽CoT素材中額外的文本並進行分析,才能找到準確或有用的資訊。
這種看似合理的CoT解釋性,或者可以稱之為「思維錯覺」,對於建立信任而言是危險的。它可能會加劇人們對LLM持續存在信任問題。一個聽起來既令人信服又聰明的系統,一旦犯錯,不僅可能損害使用者對該系統本身的信任,還會動搖他們對如何有效使用該系統的信心。其中一個引人注目的發現,根據來自於量化分析並經由質化分析驗證的結果,非non-CoT模型的表現優於具備推理能力的模型。例如,來自DeepSeek這類強調CoT生成的模型,其回應在準確性、實用性或全面性方面,通常不如那些較為簡單的LLM(圖2)。
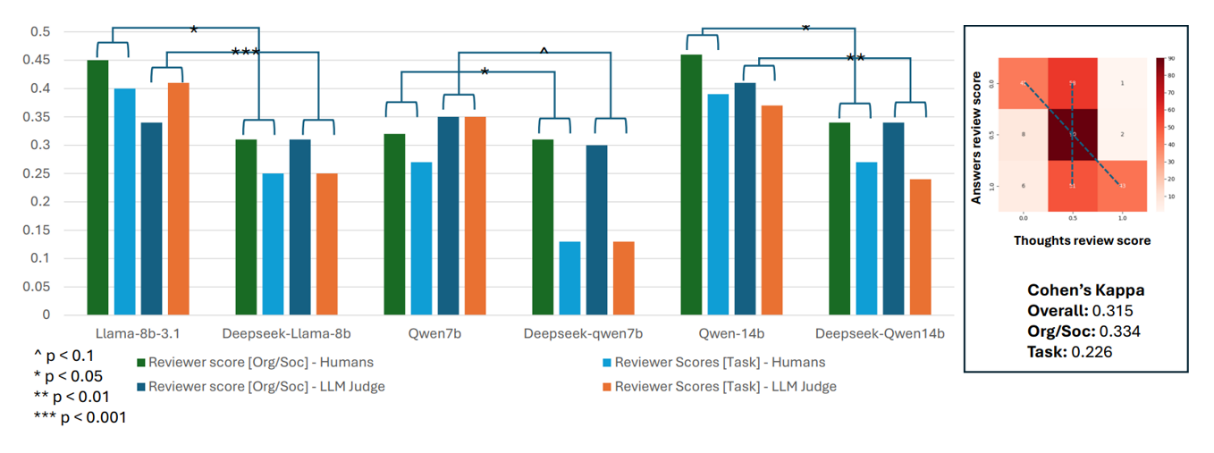 圖2 呈現人類評審與大型語言模型即評審(LLM-as-a-Judge)針對任務與組織社會(Org-Soc)相關問題的回答評分。非推理模型的評分表現優於具備推理能力的模型(如DeepSeek)。此外,思維評分與回答評分之間的相關性較弱。
圖2 呈現人類評審與大型語言模型即評審(LLM-as-a-Judge)針對任務與組織社會(Org-Soc)相關問題的回答評分。非推理模型的評分表現優於具備推理能力的模型(如DeepSeek)。此外,思維評分與回答評分之間的相關性較弱。
以人為本的信任
這項研究揭示了仔細審視解釋性的重要性,並深入思考在實際任務中,人們如何定義值得信賴、可靠和透明。透過建立參與式基準測試資料集,並同時使用人類專家和LLM作為判斷者,這對於研究結果相當重要,也揭示了評估代理輸出的複雜性。我們需要多元的評估者,包括真實人類、領域專家,以及能夠反映實際使用情況的上下文感知基準。
<本文作者:Elizabeth Anne Watkins 英特爾實驗室智能系統研究部門(Intel Labs Intelligent Systems Research)的研究科學家,主要負責AI的社會科學研究,同時也是英特爾負責任AI諮詢委員會(Intel's Responsible AI Advisory Council)的成員,她主要運用社會科學方法推動策略與執行,以提升人機協作中的人類潛力。>