隨著半導體科技的進步,大型叢集運算系統也應運而生。國家高速網路與計算中心(簡稱國網中心)在2006年便開始規劃建置的新一代高速計算平台,並於2007年9月1日正式上線供國網中心計算用戶使用。
訊息交換網路子系統風險評估
以下分成乙太網路單點失效風險評估、高速InfiniBand網路單點失效風險評估兩部分來加以說明。
乙太網路單點失效風險評估
訊息交換網路子系統包含2台乙太網路交換器,提供IBM Cluster 1350系統內TCP/IP網路通道(含管理及儲存GPFS檔案傳輸)。其內部元件故障可能會造成整個系統無法正常運作,因此單點失效風險高。為避免乙太網路導致整體系統在運作時Job及資源管理面臨單點失效風險,原始設計採高可用性軟體系統及硬體備援元件,備援機制規劃如下:
‧ 每台提供360組GbE及8組10GbE連接埠。
‧ 管理/資源/儲存節點分別以1GbE埠連接到乙太網路交換器。
‧ 每台交換器準備四組電源供應器(N+N Redundancy)及2片RPM(Routing Module),以提供最高標準的乙太網路交換器運作保護。
‧ 乙太網路交換器包含LineCard熱抽換、電源保護、路由交換模組等保護機制。
‧ 2台核心乙太網路交換器以10Gb/s 光纖線雙迴路連接,可避免單一SPOF造成系統停止運作風險。
高速InfiniBand網路單點失效風險評估
高速InfiniBand網路設計採用二層式Fat-tree Topology架構規劃,第一層以2台Voltaire R9288高速網路核心交換器作為資料封包交換骨幹中心,其上每台R9288再分別以6條高速網路Cable串接到第二層Voltaire 9024M-D Edge網路交換器,每組計算機櫃內36台計算節點再連接至其內3台Edge網路交換器內,單一機櫃計算節點InfiniBand網路交換器線路連接狀況如右上圖所示。由網路架構規劃看來,單一元件故障導致整個系統無法正常運作的可能性很低,因此單點失效風險低。
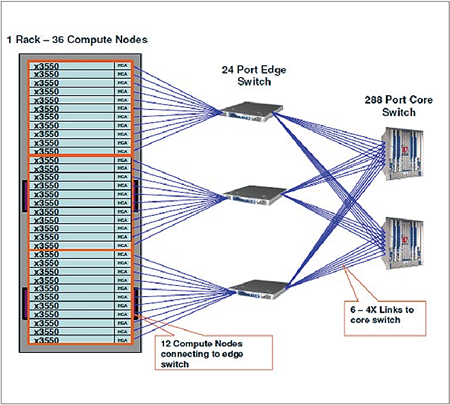 |
| ▲高速InfiniBand網路架構。 |
儲存子系統單點失效風險評估
儲存系統內資料傳輸可用性與完整性,對整體叢集運算系統運作具有非常重要關鍵角色,廠商在系統設計階段時已經把單點失效風險考慮在內,儲存節點與儲存子系統間連線均規劃成雙連接線路,並提供8台高穩定的IBM System x3650作為儲存節點,以確保儲存系統運作時的高可用性及完整性,其系統架構如下:
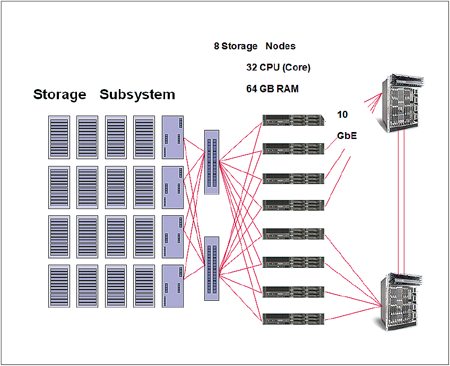 |
| ▲儲存子系統架構。 |
IBM Cluster 1350自動監控機制簡介
整體系統架構是以高可用性、高安全性與高效能性三大目標進行規劃,當各子系統零件發生故障時仍可讓系統持續運作,服務不致於立即中斷。不過,這些備援機制只是增加管理者因應的時間,倘若無法隨時掌握這些訊息並及時處理的話,屆時造成的災害及損失往往是難以想像的。以下為目前IBM Cluster 1350維運管理上使用的監控機制。
CSM(Cluster Systems Management)監控機制
CSM(Cluster Systems Management)監控機制的運作方式為,當任何節點發生網路斷線、「/tmp」使用超過90%、paging space free < 10%等狀況時,IBM RSCT(Reliable Scalable Cluster Technology)便主動發信通知系統一線、二線人員及廠商系統工程師。一線人員先初步檢查,如屬系統資源耗盡導致節點斷線,則重新開機;如為硬體異常造成當機,則通知廠商處理。
說明
IBM RSCT提供了一套完整的叢集資源監控機制,IBM CSM則利用此機制定義了很多用於資源監控的Condition、Response和Association。
如果系統在某一時刻某個條件(Condition)滿足,則與這個條件關聯的預先定義的回應(Response)就會被觸發。使用lscondresp可查看目前預設條件及其對應之回應,lscondition、lsrespone指令則可查詢條件及回應的內容。
如欲新增監視條件或回應時,則使用mkcondition或mkresponse,而mkcondresp可建立一個條件與一個或多個回應的關連。以下為irism1上lscondresp、lscondition、lsrespone的執行結果。
表1為IBM Cluster 1350開放使用至99年10月31止,所有節點因硬體零件故障導致斷線事件的統計,其中管理節點有1件,排程節點則有3件,平均每9天就會發生1件。