本文將透過實際案例,探討英特爾客戶評估基於LLM的聊天引擎,並將之部署於客戶服務產品的過程,此案例是於2024年2月至4月間,在美國奧勒岡州由英特爾管理的VMware實驗室中進行測試。
在上一篇網管人雜誌225期「微調讓LLM更領域專精‧企業生成式AI駕馭有道」的文章中,說明了部署「大型語言模型(Large Language Model,LLM)」可能面臨的典型挑戰,並深入理解微調(Fine Tuning)在改善特定客戶使用案例部署時的關鍵作用。
接下來,本文將透過實際案例,探討英特爾客戶評估基於LLM的聊天引擎,並將之部署於客戶服務產品的過程。
Twixor是一家專注於運用商業領域自動化技術改善顧客體驗(Customer Experience)的公司,Twixor的平台結合了對話式人工智慧(Conversational AI)和智慧流程自動化(Intelligent Process Automation)兩項關鍵技術,協助企業達成:
‧透過聊天對話自動執行顧客旅程
‧為客戶服務提供即時互動訊息(Actionable Instant Messaging)等功能
‧利用AI和真人客服提升支援效率
Twixor的客戶橫跨銀行、保險、醫療保健、物流和商務領域,他們的企業級客戶服務(Customer Service,簡稱CX)自動化平台產品包括:
‧Twixor Actionable Instant Messaging(AIM)平台提供對話式AI進行客戶互動,以及Twixor CX Automation平台提供全方位客戶體驗管理。
‧Twixor Developer平台協助客戶建立客製化對話解決方案
其中,組成Twixor CX Automation平台的兩大主要功能元件分別為:
‧Twixor Actionable Instant Messaging(AIM):該產品為低程式碼、無程式碼(Low-code/No-code)的CX自動化平台,利用對話式AI和智慧流程自動化,企業可透過訊息傳遞管道自動執行任務並滿足客戶需求。它提供意圖辨識、多語言支援和豐富互動內容等功能。
‧Twixor CX Automation平台:該平台透過AI、自然語言處理(Natural Language Processing,NLP)與資料分析,提供個人化支援和行銷活動管理等功能幫助企業與顧客建立關係。此外,也提供全通路聊天解決方案、智慧流程自動化和低程式碼∕無程式碼開發平台等功能。
Twixor致力於將以AI為基礎的聊天機器人嵌入至客戶體驗平台,因此需要強大的AI聊天引擎。有鑑於LLM在聊天方面展現的潛力,Twixor希望利用開源LLM強化其聊天功能。
Twixor面臨的LLM挑戰
運作LLM的成本相當高昂,尤其是針對高流量的應用程式。此外,擴充以LLM為基礎的聊天應用程式則是另一挑戰。隨著使用者需求增加,運作LLM所需的基礎設施和資源變得難以管理,必須在效能和成本效益之間取得平衡。
Twixor利用一些技巧打造更小、更高效率的模型,並實施快取(Caching)策略解決問題。Twixor從Hugging FaceAI社群既有的開源LLM開始,作為聊天應用程式的起點。若想有效地在聊天應用程式運用LLM,須謹慎考量成本管理,同時確保可擴充性。由於聊天是一種互動應用程式,回應時間和延遲是重要的特性,需要妥善因應。
Twixor CX應用程式可以在資料中心和邊緣運作,因此需要一種普遍且對客戶而言具備成本效益的硬體平台。他們原先預期可能需要使用GPU才能滿足應用程式的延遲需求,但如此一來將面臨高昂成本,且與部分邊緣使用案例不相容的問題。
Twixor的LLM之旅
Twixor踏入LLM和生成式AI的旅程,始於使用開源LLM建立高效率問答系統的目標。相關關鍵應用技術如表1所示。
Hugging Face
Hugging Face提供支援文字生成、評估和客製化的各種模型、工具和框架,為開源LLM生態系帶來許多貢獻。Hugging Face的開源LLM生態系具備全套模型、工具和框架,讓人們更容易取得先進AI功能,促進模型評估和客製化,鼓勵社群協作和創新。
Haystack LLM框架
Twixor選擇Haystack框架作為基礎,此開源Python框架專為以LLM驅動的自定義應用程式設計,提供了透過LLM和Transformer模型開發先進NLP系統所需的完整工具和元件。由Deepset開發的Haystack,使開發人員能夠更容易以NLP試驗最新模型,並於開發過程提供靈活性和易用性。
Intel Extension for Transformers(ITREX)
Intel Extension for Transformers(簡稱ITREX)協助最佳化及加速基於Transformer模型的工具套件,此套件在第4代Intel Xeon可擴充處理器(代號Sapphire Rapids)上運作特別有效。ITREX奠基於Intel Neural Compressor(簡稱INC)生態系,並與Hugging Face的Transformer和Optimum整合,在模型壓縮和最佳化方面提供無縫的使用者體驗。ITREX的主要功能包括支援各種基於Transformer的模型,例如Stable Diffusion、GPT-J-6B、GPT-NEOX、BLOOM-176B、T5和Flan-T5。另外,它也提供用於文字分類和情感分析等任務的端對端工作流程。
此工具套件支援包括Intel Data Center GPU Max Series(代號為Ponte Vecchio或PVC)和Intel Arc A-Series(Intel Arc)的Intel GPU上進行INT4精度推論,它還提供由Intel Gaudi 2、Intel CPU和GPU支援的可客製化聊天機器人框架,使用者可以透過外掛(Plugin)打造自己的聊天機器人。英特爾致力於經營開源生態系,尤其是AI領域,並持續與Hugging Face合作開發ITREX。
整體而言,ITREX是由英特爾推出的創新工具套件,提供一系列功能和最佳化方案,以強化英特爾硬體上以Transformer為基礎的模型效能,並關注AI技術的可取得性和普遍性。
Intel Extensions for PyTorch(IPEX)
Intel Extensions for PyTorch是專為英特爾硬體打造的效能最佳化套件(Package),可協助擴充PyTorch的功能。英特爾的硬體特性使效能達成最佳化,例如Intel Advanced Vector Extensions 512(Intel AVX-512)、Vector Neural Network Instructions(VNNI)以及Intel CPU上的Intel Advanced Matrix Extensions(Intel AMX)。
IPEX使PyTorch在Intel CPU和GPU上的效能達成最佳化,透過PyTorch XPU裝置在英特爾獨立GPU上輕鬆實現GPU加速。它也包含針對CPU和GPU的最佳化,如易於使用的Python API、應用於卷積神經網路(Convolutional Neural Networks, CNN)的Channels Last記憶體格式、支援BFloat16和Float16資料類型的Auto Mixed Precision(AMP)以及繪圖最佳化等功能。對於CPU而言,該擴充(Extension)會根據檢測到的指令集架構(ISA)自動將運算子分派至最佳化的底層核心。
IPEX支援LLM,並在生成式AI應用中越來越受歡迎。從版本2.1.0開始,即針對部分LLM導入最佳化。INT8 Quantization是此擴充提供的另一項功能,它提供內建的量化方法,為流行的深度學習模型提供良好的統計準確性,特別是在NLP和推薦系統。IPEX是開源的,並已經在GitHub上發布,使用者可在其中找到原始程式碼以及開發指南。
進行測試
Twixor在尋找適合其客戶聊天服務需求的最佳LLM時,評估了許多開源LLM。在評估過程中,Twixor向英特爾尋求協助;他們起初認為CPU無法執行LLM聊天功能以滿足他們對延遲的需求,因此傾向於使用NVIDIA GPU,在英特爾AI客戶工程團隊參與協助之後,針對模型的文字生成品質進行初步評估及比較,最終英特爾團隊推薦了經英特爾最佳化的NeuralChat 7B模型(圖1)。
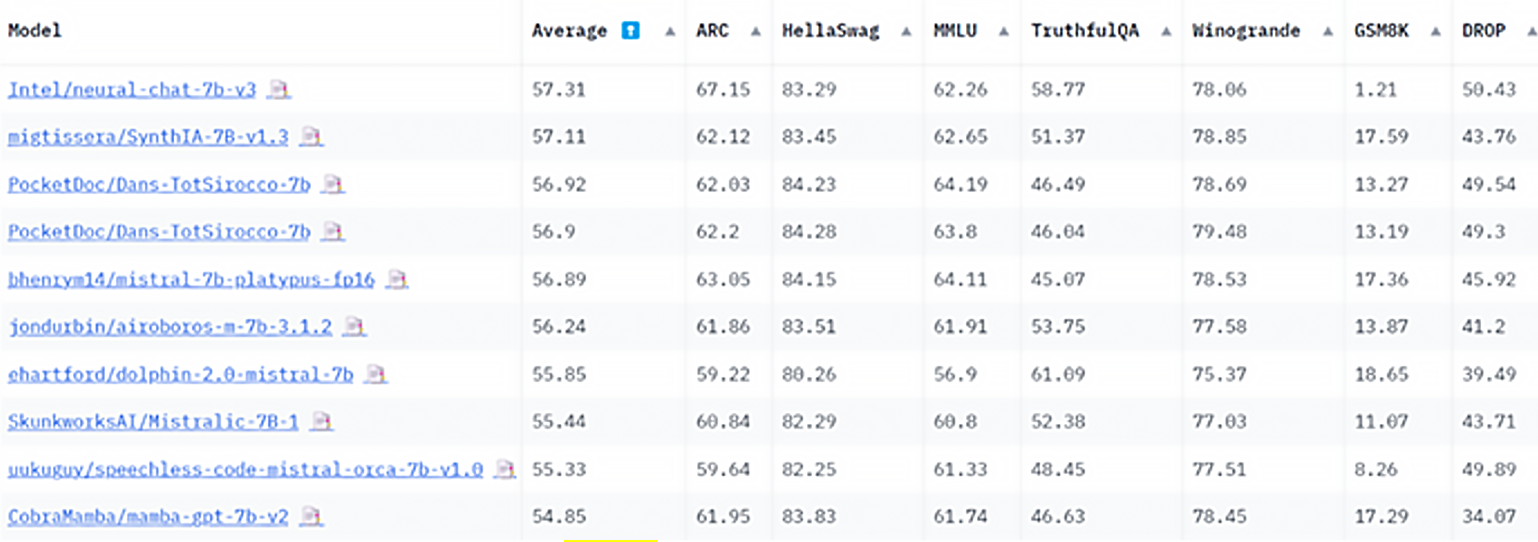 圖1 NeuralChat-7b-v3在7B規模的LLM排行榜上排名第一。(2023年11月13日)
圖1 NeuralChat-7b-v3在7B規模的LLM排行榜上排名第一。(2023年11月13日)
Twixor轉向採用NeuralChat-7B模型,以及另一個經過英特爾微調、基於Mistral AI的模型Neural-Chat-v3-1——這是來自開源資料集Open-Orca/SlimOrca中的mistralai/Mistral-7B-v0.1,在Intel Gaudi 2處理器上經過微調的70億參數LLM。該模型使用Direct Performance Optimization(DPO)方法與Intel/orca_dpo_pairs資料集保持一致。欲了解更多資訊,請參考Medium文章《The Practice of Supervised Fine-tuning and Direct Preference Optimization on Intel Gaudi2》。
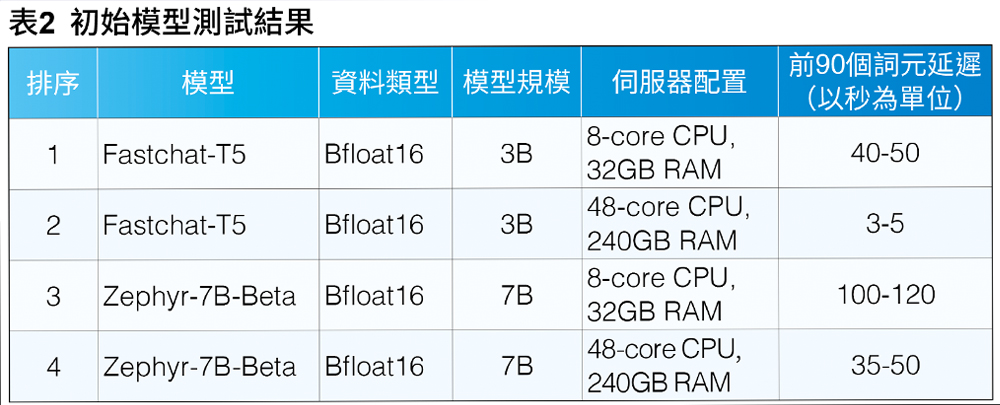
最初的模型測試,是在雲端虛擬機器實例(VM Instance)上完成,包含8個通用CPU核心和32GB RAM。他們向英特爾提出,Twixor的聊天功能需要一個高效能平台。英特爾團隊向Twixor解釋第4代Intel Xeon可擴充處理器,以及英特爾AMX對於LLM使用案例的好處,並建議他們評估使用此平台。
在英特爾提供基於第4代Intel Xeon可擴充處理器的48核心CPU機器進行測試後,Twixor成功實現聊天應用程式前90個詞元(Tokens)的延遲低於6秒。
模型測試是在配備第4代Intel Xeon可擴充處理器的本地VMware vSphere虛擬機器上執行。虛擬機管理程式(Hypervisor)的詳細資訊是VMware ESXi 8.0.1 21495797,於QuantaGrid D54Q-2U伺服器上運作,該伺服器配備2顆Intel Xeon Platinum 8480處理器,每顆處理器擁有56核心支援超執行緒技術,共配備512GB的RAM。
初始測試結果如表2所示。48核心伺服器的延遲表現,處於Twixor為Bfloat16格式FastChat-T5模型所設定的服務等級協議(SLA)範圍內。根據上述結果,該公司決定接下來的測試僅以使用第4代Intel Xeon可擴充處理器的虛擬機配置進行。
英特爾說服Twixor以配備Intel AMX之第4代Intel Xeon可擴充處理器的不同組合,來評估經英特爾微調的Neuralchat-7B模型。
測試結果
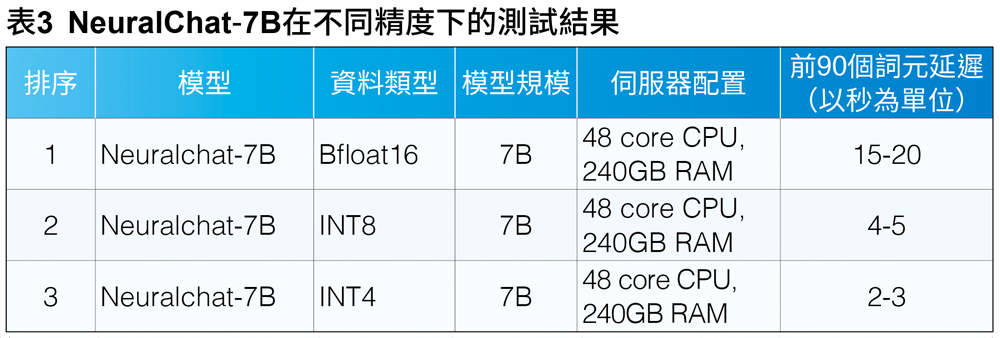
在最佳化過程中,Twixor使用較低精度的資料類型,如INT4和INT8,大幅降低了推論延遲,在延遲降低方面實現了4倍的改善。因為較低精度對聊天準確性不會造成影響,Twixor選擇INT4作為最終基準測試的資料類型。表3顯示了針對INT4資料類型最佳化後的效能提升。
測試機器的規模大小
在證明NeuralChat-7B於INT4精度的效能與準確性表現良好後,團隊修改了VM大小,以觀察是否能進一步縮小48個vCPU的配置,以降低產品規格。以下是用於測試的VM配置:
‧第4代Intel Xeon可擴充處理器:48核心;240GB RAM
‧第4代Intel Xeon可擴充處理器:24核心;128GB RAM
‧第4代Intel Xeon可擴充處理器:12核心;64GB RAM
這類聊天應用程式的推論過程受限於CPU,因此這些機器只要配備超過特定容量記憶體,就不會對結果造成影響。此測試的用意在於,比對每種配置下前90個詞元的聊天延遲。
NeralChat-7B於第4代Intel Xeon可擴充處理器上的測試
共有配置1至配置3,測試結果如下:
配置1:於第4代Intel Xeon可擴充處理器上運作:48核心、240GB RAM
使用48核心的配置,測試前90個詞元的推論延遲,顯示多次運作的平均延遲為2.738秒,完全在可接受的範圍內(圖2)。
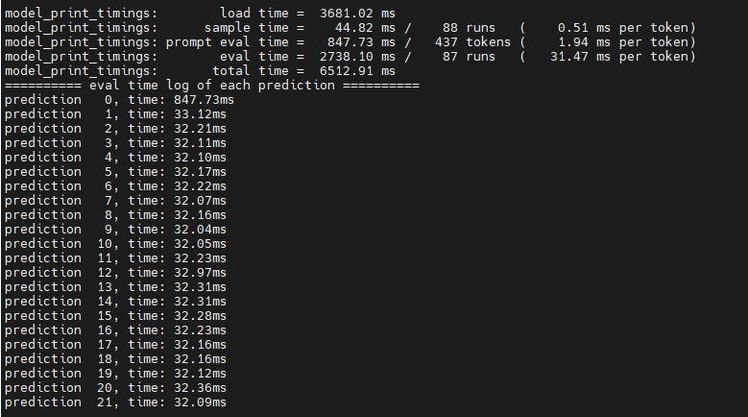 圖2 48核心虛擬機器的延遲測量。
圖2 48核心虛擬機器的延遲測量。
配置2:於第4代Intel Xeon可擴充處理器上運作:24核心、128GB RAM
使用24核心的配置,測試前90個詞元的推論延遲,顯示多次運作的平均延遲為3.528秒,也完全在可接受的範圍內(圖3)。
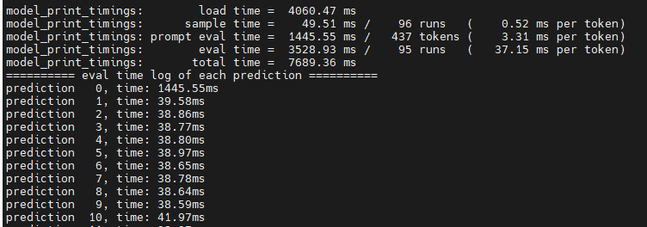 圖3 24核心虛擬機器的延遲測量。
圖3 24核心虛擬機器的延遲測量。
配置3:於第4代Intel Xeon可擴充處理器上運行:12核心、64GB RAM
使用12核心的配置,測試前90個詞元的推論延遲,顯示多次運作的平均延遲為5.210秒,此結果處於可接受範圍的上限,如圖4所示。
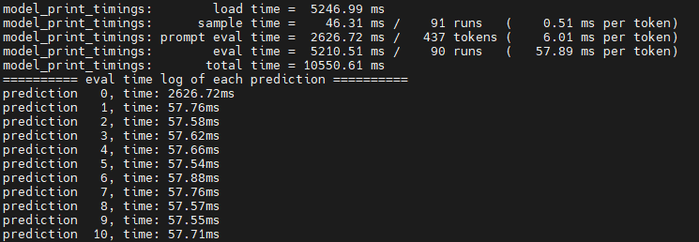 圖4 12核心虛擬機器的延遲測量。
圖4 12核心虛擬機器的延遲測量。
測試結果顯示,有兩種經過測試的配置能為聊天的前90個詞元提供約3秒之可接受延遲,如表4所示。


結語
Twixor與英特爾間的合作,成功地將LLM部署於聊天應用程式,不僅符合甚至超越Twixor對效能的要求,也證明將第4代Intel Xeon可擴充處理器與英特爾AMX結合使用,是具備成本效益且功能強大的GPU替代方案,能夠提供低延遲、高準確度的聊天機器人互動。
該解決方案的價值主張在於可提供企業級的客戶服務自動化,同時降低基礎設施成本、提升可擴充性。運用最佳化的硬體和軟體,Twixor能夠強化其客戶服務產品,為企業提供市場競爭優勢。此外,這項研究也證明了利用CPU處理要求嚴苛之AI工作負載的潛力,並為更多企業採用AI技術,也不必負擔與GPU相關的高昂成本鋪路。
<本文作者:王宗業,美商英特爾公司網路暨邊緣運算事業群平台研發協理,負責Intel Edge AI平台生態系統的推廣,帶領過智慧零售、智慧製造、智慧交通與智慧醫療等專案的開發。在20多年的軟硬體開發、推廣、客戶支援經驗中,含括嵌入式系統、智慧型手機、物聯網、Linux及開源軟體、AI硬體加速器在影像與自然語言處理等領域,並擔任過台灣人工智慧學校經理人班、技術領袖班與Edge AI專班的講師,以及大專院校的深度學習課程業師。>