NSX-T的基礎災備策略分成自動化回復與手動回復兩種,這裡將介紹前者的應用方式。本文將先介紹NSX-T Data Center的回復過程,然後說明在主中心失效時,NSX-T如何自行在災備中心做到自動回復,以及在NSX各層構件的架構與切換流程。
目前NSX-T Data Center的運作方式仍著重在單一資料中心之內的網路虛擬化與微分段方案,但是在將企業的核心業務轉移到NSX-T運作環境時,勢必須要討論以下的問題:如果主資料中心出現狀況,該如何在災備中心內回復業務?NSX-T所建置出來的邏輯交換器、T0/T1路由器、微分段策略、負載平衡器、NAT等等,能否無縫或是在短時間內就能夠重建在災備中心內,用戶可再透過SRM等方案來遷移底層的虛機呢?
對應一個能夠在重要生產環境提供服務的方案,答案當然必須是可以的。接下來兩篇文章會簡要地與大家討論NSX-T的基礎災備策略,包含自動化回復以及手動回復的架構和條件。而同樣的方案,大家也可擴充為Active-Active雙中心的配置方式。
但開始前需要先與大家說明,在這兩篇文章內說明的災備策略討論,均可使用在NSX-T Data Center 2.5/3.X版本,但後續VMware對應NSX-T有新架構叫做NSX Federation,可以在多個Site、不同的NSX叢集間,進行NSX網路與安全配置的同步。但由於目前NSX Federation仍在Technical Preview階段,要實際運用到生產環境時程應該在2021年初至年中。待後續技術成熟後,會再與大家就Federation的架構做進一步介紹。
NSX-T Data Center回復過程說明
在討論不同NSX-T災備機制時,需要就下列幾個面向來討論NSX-T Data Center的回復過程:
‧控制層的NSX Management Cluster之還原。所有NSX內的配置都是儲存於NSX Management Cluster之中。所有管理者與雲平台的控制指令,都是連往控制層進行要求。主中心失效時,控制層的Management Cluster必須能在災備中心內重新運作。
‧運算層的NSX Edge(VM or Bare-Metal)的切換。NSX Edge上有提供實體接取以及具備不同上層網路功能的Tier-0/Tier-1路由器,提供與實體網路間的介接,以及上層的NAT、南北向防火牆、負載平衡器等服務。這些路由器及上層的服務,必須要由主中心切換至災備中心。
‧運算層的vSphere Cluster。這裡是真實放置虛機或是容器的資源池。這些vSphere Cluster上有安裝NSX-T的元件,提供虛機∕容器間的網路連線、微分段防護等功能。
在圖1中是後續相關討論的說明,虛線左側為主中心,NSX-T的Management Cluster均位於主中心運作,右側則為災備中心。乘載網路實體接取與上層服務功能的NSX-T Edge(VM or Bare-Metal)需要在兩個中心均有配置。同樣地,實際乘載虛機的vSphere資源也必須在兩側均有配置。兩個中心各自有本身的vCenter,也都有SRM的構件配置。
在圖1內,正常狀況時所有運算虛機都是在主中心運作,網路進出南北向也均在主中心。但在災備演練或實際要進行切換時,透過SRM可將運算虛機的備份機器於災備中心啟用。這裡的備援與網路相關切換機制,企業可以依據實際需求與環境條件選擇採用自動化機制,不需要管理者參與,但利用手動切換災備回復的機制,當然也會與大家說明。
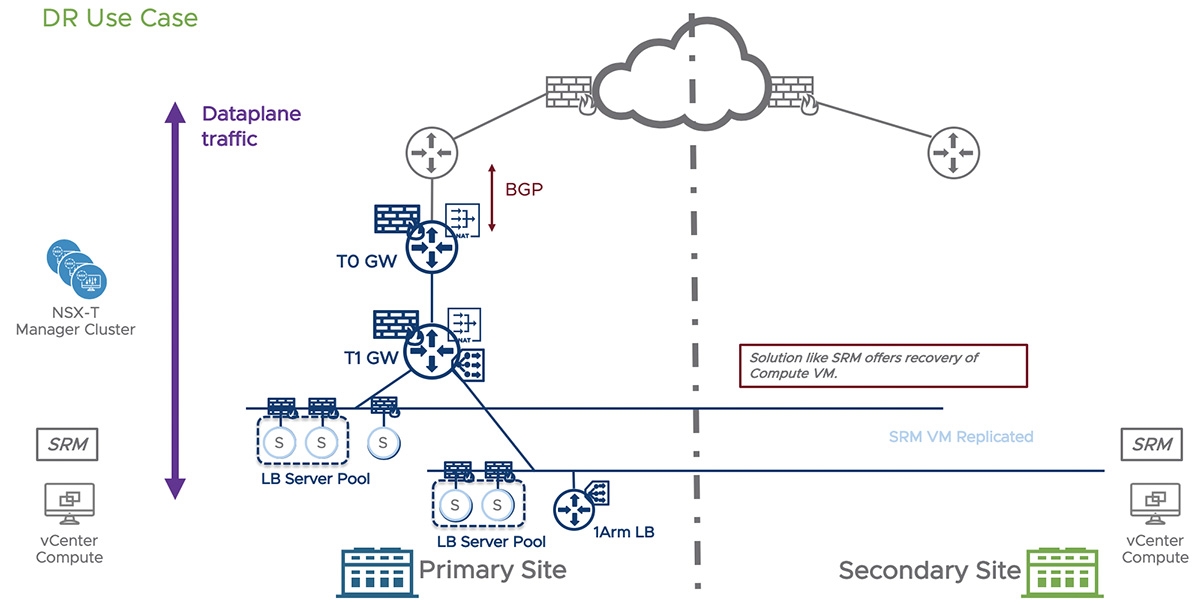 圖1 虛線左側為主中心,右側是災備中心。
圖1 虛線左側為主中心,右側是災備中心。
那這裡先針對NSX-T Data Center在兩個中心的自動化災備回復機制做介紹。
NSX-T Data Center自動化災備回復機制
倘若希望主中心失效的時候,NSX-T可以自行在災備中心做到自動回復,在NSX各層構件的架構與切換流程,說明如下:
‧控制層的NSX Management Cluster內的各台Manager VM,必須位在一個跨雙中心的vSphere Stretch Cluster上,且NSX-T的管理網段(連接Managers、Edge、vSphere的管理網段)必須要跨雙中心L2連接。
‧當主中心完全失效時,原本主中心這邊位於vSphere Stretch Cluster內的x86伺服器失聯,同時代表各台Manager VM也停止服務。此時,Stretch Cluster會將三台Manager VM在災備中心以vSphere HA機制自動重新開啟,並重新組成NSX Management Cluster。在災備中心的Edge/vSphere可繼續與NSX Management Cluster維持通訊。
‧各個NSX Edge Cluster在規劃時,需要在主中心及備援中心均具備Edge VM/Bare-Metal Edge的資源。各台Tier-0/Tier-1路由器在建立時,必須採用Active-Standby架構。透過Edge內Active-Standby的Preemptive選擇機制,Active T0配置於主中心的Edge資源,而Standby T0位於備援中心。此時,所有的T0/T1南北向實體連接與上層網路服務,均是透過主中心的Edge資源來提供。
‧當主中心完全失效時,各台T0/T1路由器上的Active構件均失效。此時災備中心的Standby構件接手,因此原有與上層實體網路接取以及網路服務透過NSX內HA切換機制,可持續維持服務。
‧在此架構內,T0路由器與上層實體網路的BGP連線需要同時與主中心和災備中心的路由器建立Neighbor關係。此時在主中心失效時,災備中心的T0仍可透過此處的實體路由器維持對外連通。
‧於災備中心在運算層的vSphere資源池,本來的網路配置仍可運作,且在NSX Management Cluster回復後可恢復與控制層通訊。當主中心失效時,用戶僅須啟用SRM機制,將原本主中心的虛機在災備中心的資源池重新部署,且網路配置完全不需改變。
NSX-T於災備中心自動回復的配置機制示意,如圖2所示。
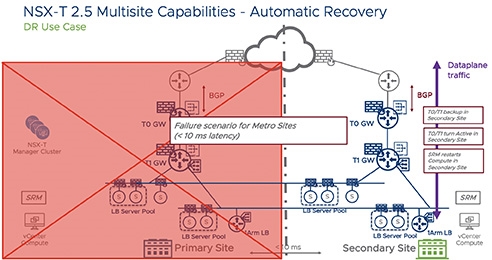 圖2 NSX-T於災備中心自動回復的配置機制。
圖2 NSX-T於災備中心自動回復的配置機制。
上述機制的好處是當主中心失效,災備中心可在短時間且管理人員無須手動介入下,透過NSX-T的配置與運作環境即可自動在災備端恢復。
當然,要達成上述的機制,除了前述的配置要求之外,底層的環境需要滿足下列條件:
‧管理資源池(vSphere Management Cluster)必須配置為Stretch Cluster。這代表兩地間的網路延遲必須要低於10毫秒(ms)、有可直接L2打通的底層網路、管理資源池中的外接或內接儲存可支援Stretch Cluster,應該有獨立的儲存線路(一般來說至少5Gbps頻寬,或是vSAN Stretch Cluster架構需求10Gbps頻寬)來運作Stretch Cluster上的資料同步
‧如果是對外服務,此對外服務的Public IP必須可由企業或同一家電信服務商在災備時進行切換。
‧支援兩中心運算資源連接的實體線路建議支援大於1Gbps的頻寬,以及必須配置至少1700的IP MTU。
‧SRM在進行虛機資料抄寫時也會使用到網路頻寬,同樣需要考量。
前端的機制當然架構上很理想,但極有可能會有下列的問題讓客戶不易實作,因此無法取得自動切換的好處:
‧企業在兩座資料中心間的延遲時間會超過10ms。
‧因為成本與實際環境的限制,無法提供足夠頻寬,無法建立兩中心間的Stretch Cluster。
‧在此架構內,T0路由器與實體網路間的接取僅能採用Active-Standby架構,無法同時使用多台Edge提供多條線路整合出的高頻寬線路。一個方式是改為採用Bare-Metal Edge,單台Edge可以提供30Gbps以上的頻寬。但如果南北向頻寬就是需要多台Edge,以Active-Active方式提供,此時這種自動化機制就無法運作了。
此時有另一個機制可以考慮,也就是接下來所要討論的手動回復機制,在下期文章再繼續與大家進行討論。
<本文作者:饒康立,VMware資深技術顧問,主要負責VMware NSX產品線,持有VCIX-NV、VCAP-DTD、CCIE、CISSP等證照,目前致力於網路虛擬化、軟體定義網路暨分散式安全防護技術方案的介紹與推廣。>