延續上期所介紹的NSX Advanced Load Balancer,此次將介紹NSX Advanced Load Balancer如何透過原生派送機制、搭配網路路由/SDN的機制、DNS派送機制等三種方式來提供Active/Active架構。然後,將以實例來說明如何進行Scale-Out/Scale-In作業。
前篇投稿內說明了NSX Advanced Load Balancer的系統架構,並且討論NSX ALB可以利用Active/Active機制,讓一個需要大量負載平衡效能的服務,可以平行在多台服務引擎上執行。但要怎麼做到呢?這就是在本篇希望與大家說明的重點。
NSX Advanced Load Balancer目前可以透過三種方式來提供Active/Active架構,以下分成三大單元來分別說明:
原生派送機制
在原生派送機制內,一個服務會選定一台服務引擎作為Primary SE。所有這個服務的入口(Virtual IP,VIP)都是在這台Primary SE上,如圖1所示。
 圖1 原生派送機制。
圖1 原生派送機制。
當Primary SE(Dispatcher)收到用戶連線要求時,可以選擇自己處理(自行進行負載平衡),也可以把這個要求轉交給另外的服務引擎,由其他服務引擎進行負載平衡。由於服務引擎在進行負載平衡轉送時,會把連線的來源IP以SNAT轉為自己,所以無論是哪台SE被指派作為此連線的負載平衡,後端的Server都會把連線回送給同一台SE。
而在SE要把這個連線回送給原本的用戶時,依據不同的環境,有兩種處理方式:
1. 在傳統網路架構時,Service Engine會將回應直接回傳給用戶,不會送給原本的Dispatcher再回傳。這是圖1左邊的Direct SE Return模式。
2. 在某些SDN架構下,SDN方案要維持Flow-state,同一個Flow的回傳不能來自不同的MAC-address。此時,回傳的連線會先回送給Dispatcher,再由Primary SE回傳。這是圖1右邊的Tunnel Return模式。
無論左邊或右邊,應該很清楚地看到,Primary SE的壓力一定是最大,整個服務的瓶頸會鎖在這台引擎的能力上。因此,原生派送機制的Scale比較小,一般建議Active/Active的範圍不要超過四台Service Engines。
搭配網路路由/SDN的機制
在這類機制內,多台服務引擎前端的網路設備可以負責做連線負載的分派。對應到指定的服務,Virtual IP在前端網路設備會知道可以分派到後端多台的Service Engine上來做處理。如圖2所示,處理的機制同樣可分成兩種:
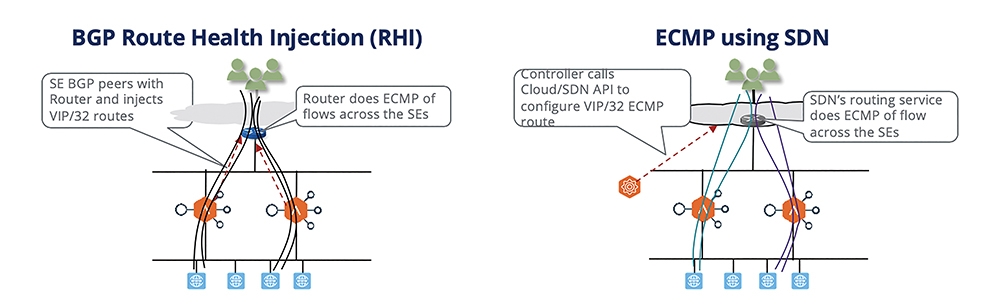 圖2 搭配網路路由/SDN的機制。
圖2 搭配網路路由/SDN的機制。
1. 傳統網路架構下,各台Service Engine要與前端網路設備跑標準BGP,並且透過Route Health Injection機制告知這個Virtual IP可以往本身送。因此,前端網路設備透過ECMP(Equal Cost Multi-Path)機制,在有用戶要連線到這個Virtual IP時,分派到不同的Service Engine上,這是圖2左邊的機制。
2. 在SDN架構下,NSX ALB會與SDN Controller透過API溝通,告知如果要到指定的VIP,後端請用ECMP轉送給不同的服務引擎,這就是圖2右邊的機制。
這個機制是在大型環境的建議方案,可以配置到多台引擎同時服務(限制在BGP/SDN可以允許的ECMP上限,比如說一個Virtual IP可以對應到64個後端引擎)。用圖2左邊或右邊的架構,就要看環境,是否有支援BGP,或者是否與NSX Advanced Load Balancer有整合的SDN方案可以搭配。
DNS派送機制
如同名稱,DNS派送機制是當用戶在連往服務入口前,直接於查詢時由DNS控制進行分派,告知用戶連往哪台服務引擎。
如圖3所示,在這個架構下,NSX ALB Controller會透過API來配置DNS,對應到指定服務FQDN可以回應不同的Virtual IP(對應到不同的Service Engines)。
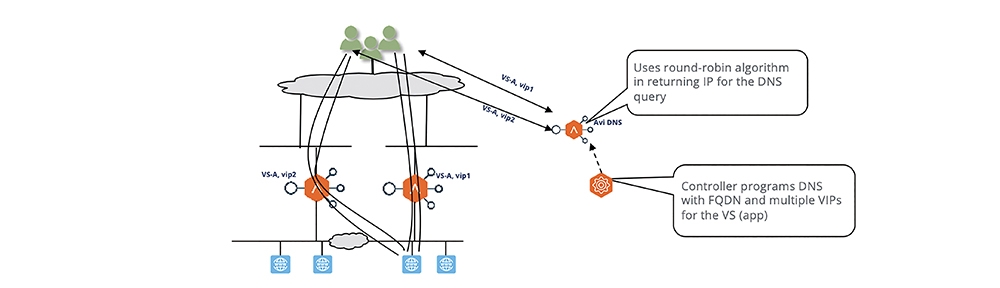 圖3 DNS派送機制。
圖3 DNS派送機制。
所以,不同的用戶同樣要連到VS-A.example.com,有些用戶會取得vip1,有些用戶會取得vip2,以此類推,就能夠多台同時服務了。如果服務引擎失效,Controller偵測到這樣的狀態,同樣透過API去編輯DNS紀錄,把死掉的服務引擎上對應的VIP紀錄移除。
此架構的限制在於NSX ALB必須要能夠透過API去控制DNS紀錄。目前,只有支援NSX ALB本身提供的DNS服務,以及AWS的Route 53。
無論採用以上哪種架構,對應到單一服務,Persistence Table都會在各台引擎間同步(若選擇採用如Source-IP Persistence、TLS Persistence等等方法)。因此,即使在Active/Active架構內出現服務引擎失效,用戶連線轉到其他台引擎服務的狀況,連線也不會中斷。
聽起來,採用Active/Active的架構非常棒,但有沒有限制呢?要運作這樣的架構確實有一個前提:「Active/Active架構需要採用Reverse-Proxy/SNAT模式來運作」。也就是說,用戶連線的來源IP會被修改成服務引擎本身的網路位置。在這種模式內,如果應用系統需要知道用戶真實來源IP,必須採用以下兩種方式之一:
‧HTTP表頭內的X-Forwarded-For欄位
‧採用Proxy Protocol協議
如果新應用系統可以支援SNAT模式,且可以透過上述方式來抓取用戶地址,此時NSX ALB的Active/Active架構就非常棒了。但如果對於傳統業務,一定只能用網路層看用戶來源IP,那就只能用Active-Standby機制。NSX ALB可支援Active-Standby機制,但這就不是此方案的特殊強項,使用市面上的傳統應用遞送方案就可以做得非常出色。
Scale-Out/Scale-In實作
抓幾張圖給大家看一下NSX Advanced Load Balancer方案內的服務Scale-Out/Scale-In是怎麼做。圖4是在NSX ALB的Controller GUI內,管理者可以點入一個Virtual Service,將看到目前這個Virtual Service底層是由Avi-se-miyey與Avi-se-wtkyc這兩台Service Engine來服務。這邊採用的是前端所提的Dispatcher機制,因此Avi-se-miyey目前是Primary的角色,Virtual IP長在這台虛機上。
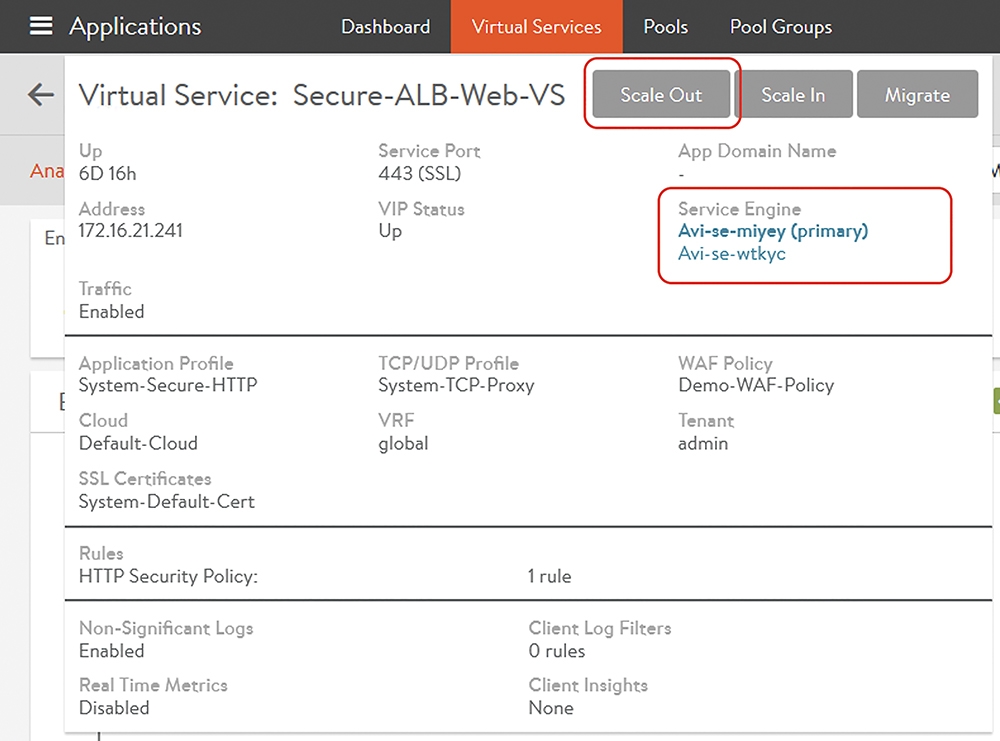 圖4 點入一個Virtual Service。
圖4 點入一個Virtual Service。
上面有Scale Out的選項。如果管理者覺得目前的兩台Service Engine效能不夠,可以直接點擊這個選項。
此時,選項內會詢問哪個VIP要擴張等資訊。當管理者希望將Virtual Service擴張到其他服務引擎時,NSX ALB Controller會尋找是否有空的Service Engine可以提供服務。或者,也可以勾選「Create Service Engine」,強制要求產出新的服務引擎,如圖5所示。
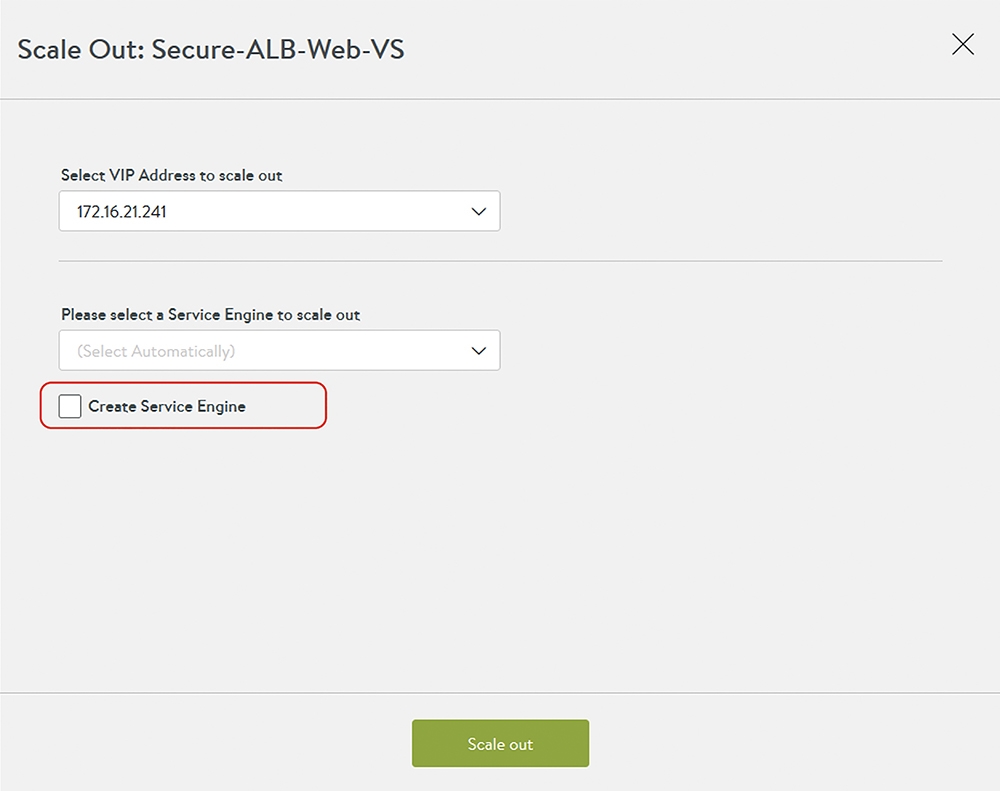 圖5 可勾選「Create Service Engine」,來強制要求產出新的服務引擎。
圖5 可勾選「Create Service Engine」,來強制要求產出新的服務引擎。
在這個範例內,因為原本在vCenter內僅有部署Avi-se-miyey、Avi-se-wtkyc兩台服務引擎虛機,沒有其他的服務引擎。因此,當管理者要求將上述的Virtual Service再Scale-Out時,Controller發現沒有現成的引擎可以使用。所以,NSX ALB Controller透過南向對vCenter的API,要求在vCenter內部署新的服務引擎。在圖6中,可以看到目前vCenter自動產生一台新的虛機叫做Avi-se-cyqfk。
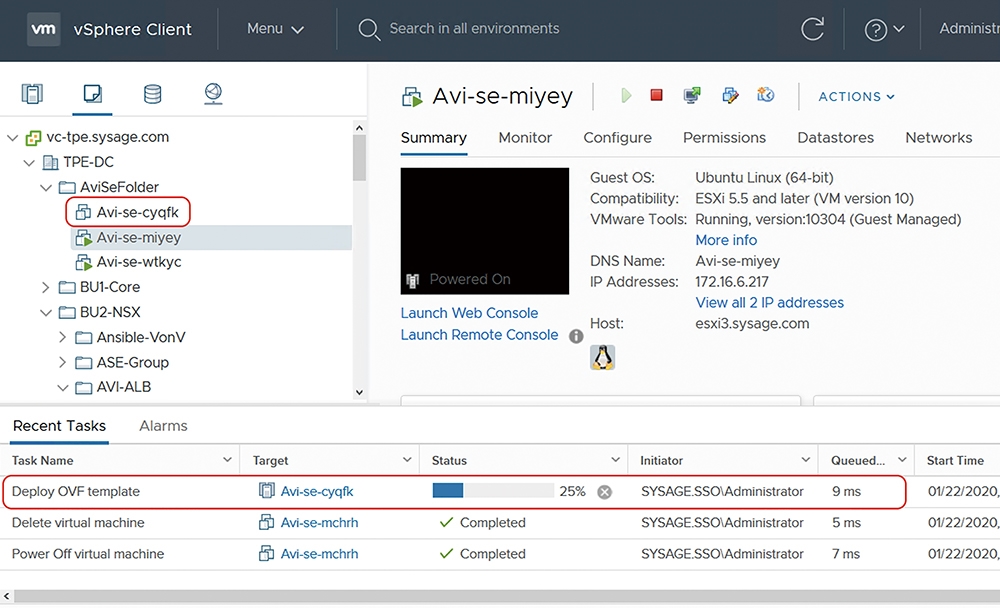 圖6 vCenter自動產生一台新的虛機。
圖6 vCenter自動產生一台新的虛機。
上述的虛機產生後,會自動與Avi Controller通訊。接著,管理者要求的Virtual Service Scale-Out作業就可以在新的服務引擎上生效,如圖7所示。
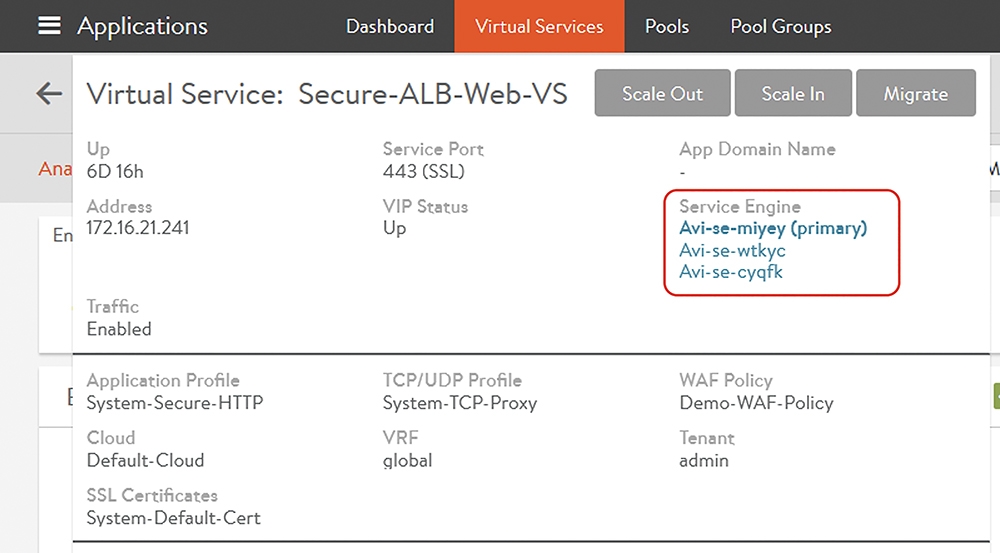 圖7 Virtual Service Scale-Out作業已經可以在新服務引擎上生效。
圖7 Virtual Service Scale-Out作業已經可以在新服務引擎上生效。
在這邊,有幾個重點想和大家討論一下:
‧上面的動作是由管理者驅動,透過NSX ALB Controller對私有雲或公有雲的API呼叫,「自動」進行服務引擎部署等Scale-Out/Scale-In作業。
‧上述的動作當然可以用其他的自動化編排工具或是利用API呼叫,也可以在達成某些條件時(例如同時連線數到達某個門檻以上)來啟用。
‧上述的作業可以在很短的時間,例如數分鐘內完成。
請大家思考一下這樣的方式與硬體架構的差別。坊間的方案當然也有一些特殊的Active-Active運作機制,比如說一台大型設備內配置多張板卡提供平行服務,或是以LACP的方式讓多台硬體設備同時進行負載平衡處理。但回到原點:採用這些特殊方案的方式就是要採用這些廠商的「硬體」。也就是說,如果發現目前的負載平衡效能不足,就算不是把原本的硬體設備打掉重買,擴充的過程仍然包含了規劃、硬體採購、設備到貨、安裝上架、網路底層配置等等。上面講的是幾個星期幾個月的時間,而不是像前面展示的,只要有底層的虛擬化或公有雲資源池,隨時可以快速擴充。對於要求速度、能快速因應業務需求的環境來說,採用硬體的彈性還是不足夠的。
估算Avi的效能需求
本文最後來討論一個前面文章內詢問的問題。一般來說,在部署一個新業務前,業務團隊很難準確回答應用的連線需求量。但假設其實業務團隊可以抓準需求量呢?那當然很好,就可以用下面討論的方式來估算Avi的效能需求。通常負載平衡器對應Web應用,最重要的效能指標有兩項:
‧SSL TPS(Transactions Per Second):用白話文講,每秒新增的交易連線量。舉例來說,之前與一個著名的客戶聊天時,他們說當他們長官下令一個新的促銷活動時,從活動開始幾分鐘內,連線量就衝到六七十萬筆。在這種狀況下,每秒新增的連線量至少也有個一兩萬沒有問題
‧SSL Throughput:顧名思義,對於這個應用南北向的流量頻寬估算。
對負載平衡器來說,真正在吃CPU效能的不是封包轉送、NAT這些東西,而是加解密。所以,雖然廠商的Datasheet上面各種規格洋洋灑灑列了一大堆,通常在比較效能時,看上面這兩項就可以:負載平衡器需要做加解密時(跑SSL),可支撐的加密頻寬大小,以及每秒新增的連線量有多少。
這裡不想長篇大論地做規劃機制說明,但由圖8內簡單的舉例做討論:假設可以從業務團隊得到效能規格:這個業務需要每秒可以新增10,000個交易,而且南北向的頻寬規劃為3Gbps。此時,需要多大的服務引擎容量呢?
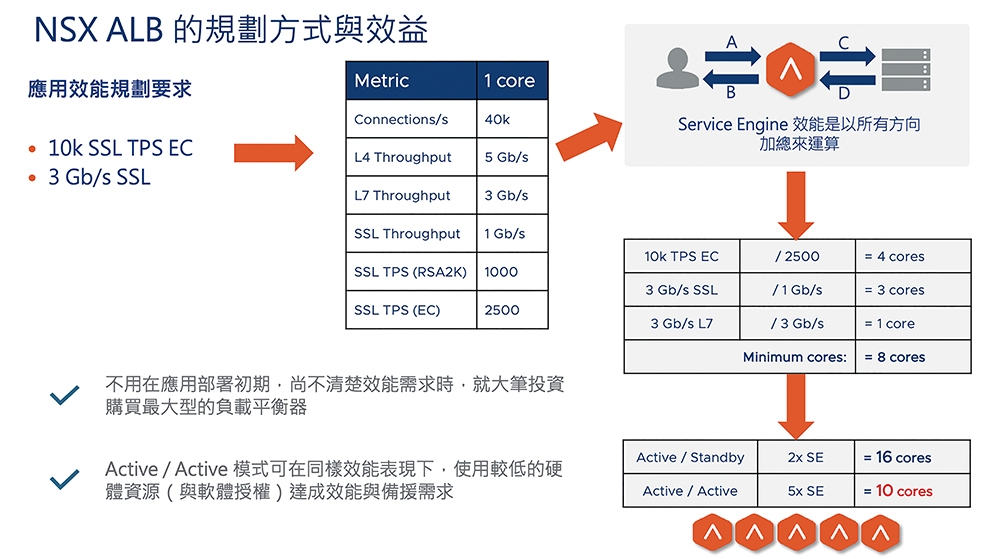 圖8 NSX ALB2的規劃方式與效益示意圖。
圖8 NSX ALB2的規劃方式與效益示意圖。
以粗略估算的方式來討論。業務團隊通常提出的效能要求是由外部用戶到負載平衡的這一段,也就是圖8右上角的A/B部分。這邊如果是採用HTTPS,在需要每秒10,000個SSL新連線的狀況下,如果採用資源耗用較少的ECC機制,每個服務引擎的Core約可處理每秒2,500個新連線。因此,在TPS部分,需要4個Core。
而以SSL Throughput的需求,若業務需要3Gbps的南北向流量,每個服務引擎的Core約可處理1Gbps的加解密流量,因此這邊需要3個Core。
但同樣地,需要估算由負載平衡器到伺服器端的流量處理需求,也就是圖8右上角的C/D部分。這裡假設就不加密了,只有HTTP。但因為負載平衡器會讀取並處理HTTP 7層封包,即使不加密,也要花效能來提供資源。NSX ALB約抓每個Core可以處理3Gbps,因此這邊也要耗費1個Core。
所以加起來,需要8個Core的運算能力。那這時候要怎麼來規劃需要的服務引擎呢?
如果採用傳統的Active-Standby模式,那這個服務需要有2個Service Engine,一個Service Engine需要8個Core,另一個備援。這樣,需要總共16個Core的資源。
如果採用推薦的Active-Active模式,那這個服務的規劃方式就很多元了。假設每個Service Engine採用2個Core,那麼8個Core的運算能力需要同時有4個引擎來服務,另外再加一個備援。此時,只需要準備10個Core的資源(共5個引擎,每個2 Core)。
這邊看到在NSX Advanced Load Balancer Active/Active架構下的特點:
在這種架構下,可以用比較少的硬體資源與軟體授權,達成相同的效能要求(上面的16 Core與10 Core)。如果這裡的說明還太複雜,請大家想像一下,有一堆硬碟,要做RAID 1或是RAID 5,哪個可以使用的磁碟空間比較大?這是很類似的比較。其次,就算規劃得不準,也沒關係。NSX ALB的架構是有彈性的,如果規劃太多,那可以把服務引擎的Core數減少,把多餘的授權拿去別的地方用。而如果規劃得不夠,多買一些授權,把現有的服務引擎再Scale Up/Scale Out就好了。這比原來硬體的方式彈性太多了吧!
花了兩篇文章討論NSX Advanced Load Balancer的架構與AA機制。下篇文章要將討論另外一個新話題:NSX Advanced Load Balancer方案的分析功能。
<本文作者:饒康立,VMware資深技術顧問,主要負責VMware NSX產品線,持有VCIX-NV、VCAP-DTD、CCIE、CISSP等證照,目前致力於網路虛擬化、軟體定義網路暨分散式安全防護技術方案的介紹與推廣。>