RAG系統透過先檢索、後生成的機制,於生成回應前先從外部即時資料庫中提取相關資訊做為參考,使生成內容具備可溯源性與可驗證性。本文將分成上下兩集探討RAG的基本背景與核心框架,比較RAG與其他AI的不同之處,並透過實際操作建構RAG基礎架構。
在當前企業數位轉型的趨勢下,各產業積極導入AI模型建構智慧化的服務平台,涵蓋AI智能客服、智慧醫療等多元應用。然而,大型語言模型(Large Language Model,LLM)做為其核心技術,存在先天性的限制。在處理海量知識時,儘管LLM具備強大的語意理解能力,但面臨具有時效性的資訊以及長尾知識,往往受限於訓練資料不夠全面,或者模型僅能依賴訓練期間所學得的參數化知識,無法即時查詢或更新外部資訊等侷限,模型生成的內容不夠精確,進而產生誤導性的「幻覺」資訊或是模型出現偏見。對於仰賴AI輔助決策的企業而言,上述缺陷恐導致錯誤決策,重創企業商譽。
為了克服LLM依賴參數化記憶所帶來的侷限,「檢索增強生成(Retrieval-Augmented Generation,RAG)」技術提供了具體解方。
RAG系統透過「先檢索、後生成」的機制,於生成回應前先從外部即時資料庫中提取相關資訊做為參考,使生成內容具備可溯源性與可驗證性。特別是專門的領域,如醫療、法律等極度依賴專業利基知識的領域中,該機制能提升回應的精準度與專業性。然而,RAG系統的實際效能取決於檢索品質、資料時效性及提示詞設計等多項因素,建立系統化的評估指標與持續優化機制,是企業AI建置須投入的關鍵成本。
RAG背景與相關技術
以下先說明RAG的背景與相關技術。
LLM的不足
為何需要檢索增強生成(RAG)?先從LLM的三個天生限制談起。大型語言模型(LLM)在人類語言理解與生成上表現驚人,但它並非毫無缺陷。
首先是幻覺(Hallucination)與「長尾知識」的困境。所謂「幻覺」不只是模型出錯,更是因為訓練數據分布失衡的結果。如圖1所示,當訓練數據過度集中在常見的資訊時,模型會產生嚴重的偏誤;它對於常識(恐龍的頭部)瞭如指掌,但對於那些樣本數量極少的稀有知識(恐龍的「長尾巴」),則因缺乏足夠的樣本而成了模型的認知盲區。在這種情況下,模型容易被主類別的邏輯「綁架」,從而一本正經地編造錯誤資訊,正是所謂的「幻覺」。
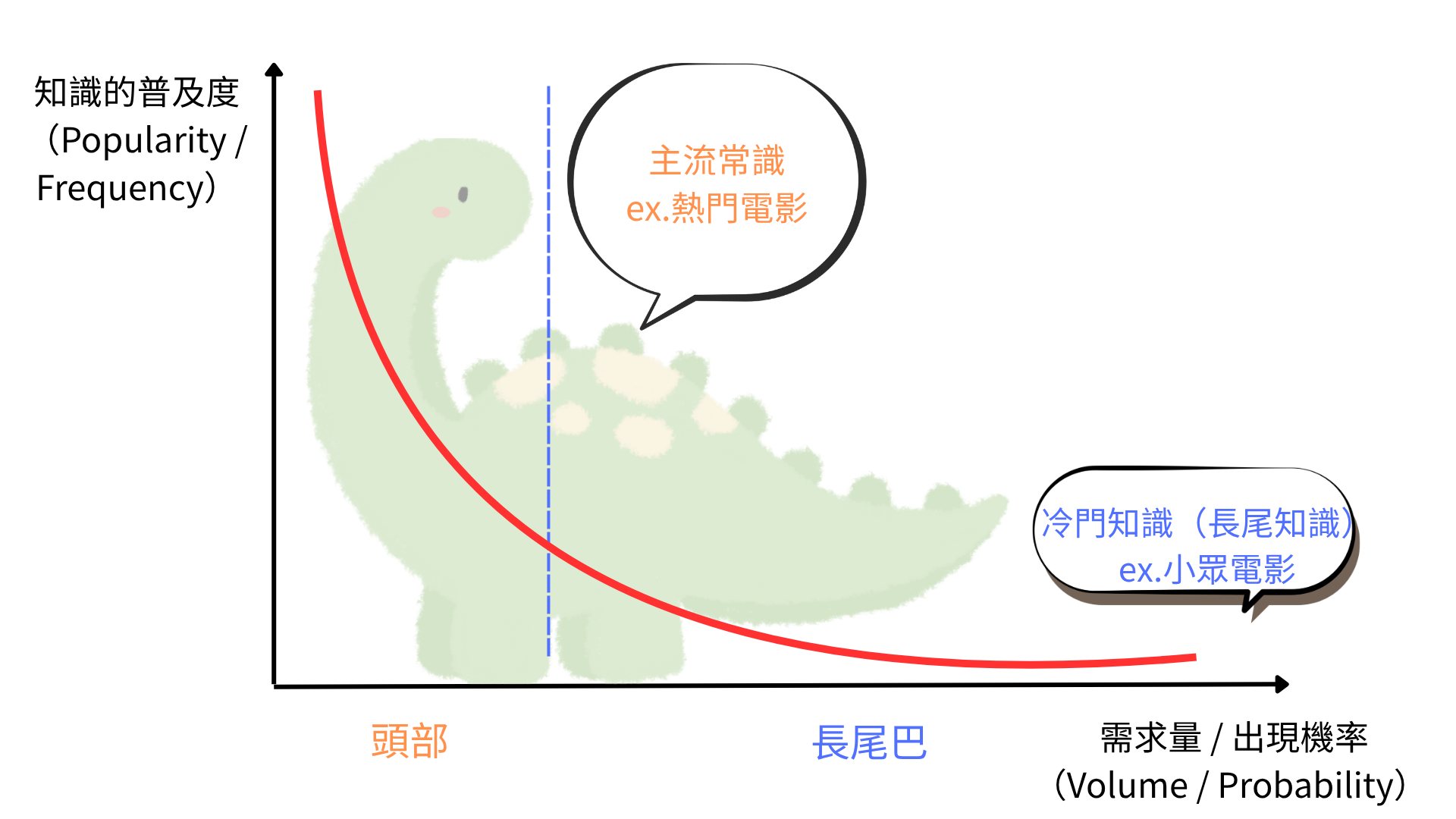 圖1 長尾知識理論。
圖1 長尾知識理論。
事實上,在一個資料集中,那些被AI忽視、不常見的類別常常是最關鍵的。以自動駕駛車為例,AI感知模型必須具備預測違規或突發事故的能力,但自動駕駛資料集裡,不可能全是肇禍、違規的場景樣本(大部分場景還是安全的)。這種數據不平衡的情況下,模型很容易產生標籤偏見(Label Bias),在面對真正的危機時,因缺乏經驗而產生幻覺或誤判。
其次是知識時效性(Outdated Knowledge)的斷層,LLM的知識庫受限於「知識截斷點(Knowledge Cutoff)」。一旦訓練完成,便無法自動更新動態資訊。這意味著在此之後發生的重大新聞、新興科技研發成果或社會趨勢,皆屬於其「內部記憶」之外的盲區,使其無法應對需要即時資訊的任務。此外,這更引發了資料相依性(Data Dependency)的連鎖錯誤。例如,當使用者詢問現任總統的配偶是誰時,模型可能因底層知識過時,將「前任總統」的家庭關係錯誤地「張冠李戴」到現任者身上,產生邏輯錯亂的幻覺回應。
最後是AI模型的黑箱風險與不可解釋性。LLM的知識是透過訓練過程中編碼於模型中的數千億個參數(Parameters)而成,稱為「參數化記憶」。這種機制存在前面提及的瓶頸:它難以捕捉極其稀有的長尾資訊,且一旦訓練完成,在不依賴外部檢索或工具的情況下,便無法即時更新動態資訊。更重要的是,LLM的運作模式如同「闔書考試(Closed-book)」,雖然能給出答案,卻無法交代其知識來源。這種「知識不在預訓練範圍內(Knowledge not in pre-training)」的限制,使得使用者無法驗證答案是參考了哪些文章,導致其回應缺乏可信度與可追溯性。
為了解決LLM的不足,RAG出現了
傳統的LLM可比擬為在進行一場Closed-book的考試,只能憑藉大腦既存知識回答問題,包含模糊或過時的記憶造成資訊錯誤。相反地,RAG則解決LLM的限制,它給了AI一本可以隨時翻閱、即時更新的百科全書,讓它進行一場Open-book的考試。AI不再只靠記憶回答問題,而是先「翻書(檢索)」,再根據書中的內容「總結回答」,以下將詳細介紹。
RAG定義與基本流程
檢索增強生成(Retrieval-Augmented Generation,RAG)是一種結合「資訊檢索(Retrieval)」與大型語言模型(LLMs)的技術。旨在解決LLM於回應使用者問題時出現幻覺、編造不存在的資訊、資料庫過時與不足、推理過程不透明等問題。RAG無須重新訓練模型,它透過從外部數據庫(如維基百科、企業資料庫)檢索相關資訊,並將「檢索到的資訊」與「原始查詢」一起輸入至模型,並生成更有依據的回應。RAG框架大幅提升生成內容的準確性與可靠性,特別是在具高度專業性任務中,在於無須重新訓練模型的情況下,即可更新知識,確保答案不再只是憑空想像。
RAG的基本架構著重於如何整合「檢索」與「生成」這兩個部分,用來解決LLM在處理知識密集型任務的限制。先檢索外部知識庫,再讓LLM依據檢索結果生成,強調「可更新」與「可追溯來源」。圖2為RAG整體流程總覽圖,圖3則是RAG基本框架說明,針對圖中的RAG技術細節,將在文後詳細介紹。
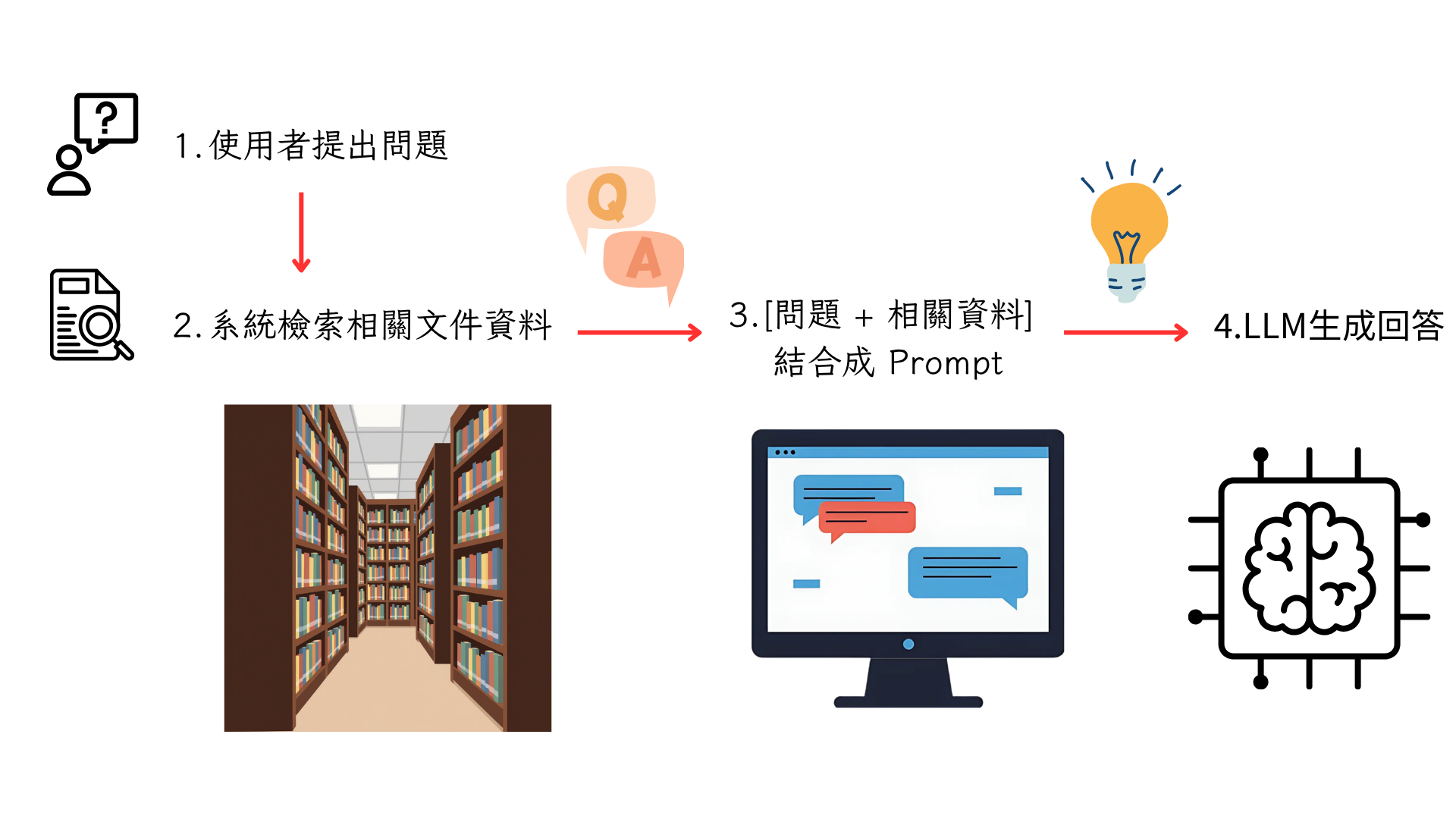 圖2 RAG整體流程總覽圖。
圖2 RAG整體流程總覽圖。
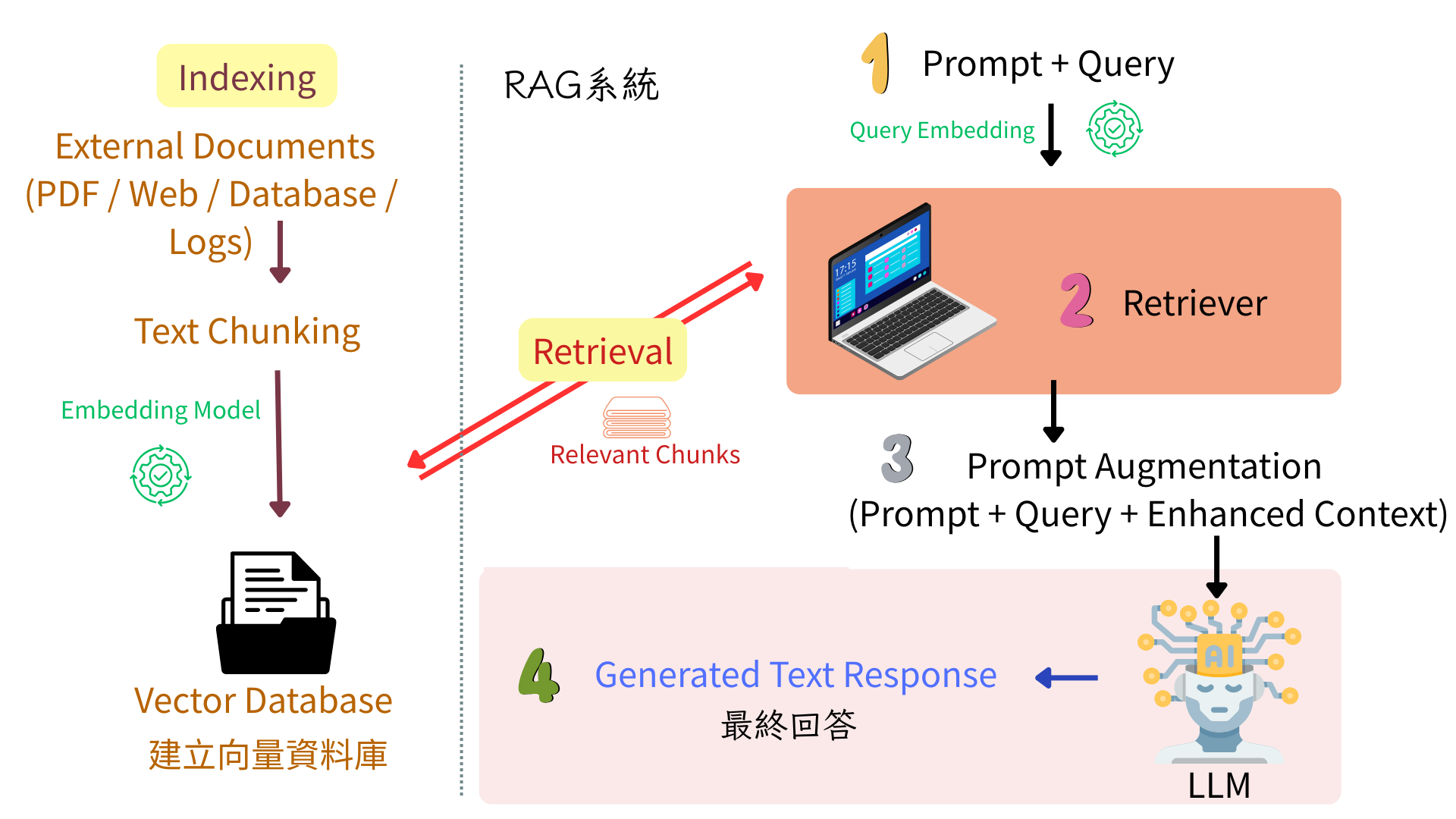 圖3 RAG基本框架。
圖3 RAG基本框架。
RAG的演進歷程
RAG技術的演進由簡單架構演變為更複雜、更具彈性的系統,文獻中常將RAG的發展整理為Naive RAG、Advanced RAG以及Modular RAG三大進展:
首先是初級RAG(Naive RAG),其為最基礎RAG架構。流程包含索引(Indexing)、檢索(Retrieval)及生成(Generation)。系統須預先將文件切分(Chunking)並轉化為向量索引。當用戶提問時,系統檢索向量資料庫,並透過演算法進行相似度比對,將檢索到最相似的參考資料結合提示詞(Prompt)輸入至LLM後生成回應,藉此獲得較具依據的推理。然而,這種模式容易出現精準度(Precision)低、檢索到的內容可能不相關、召回率(Low Recall)低、未能檢索到所有相關內容的問題,在生成階段則可能面臨幻覺或回答不連貫產生冗餘的困境。
為了解決初級RAG的局限性,高級RAG(Advanced RAG)引入了檢索前(Pre-retrieval)和檢索後(Post-retrieval)的優化策略。這包括優化索引結構,如數據粒度、索引結構、Metadata、優化查詢,以及在檢索後進行重排序(將最相關文檔排在前面,或重新計算語義相似度)和上下文壓縮(處理上下文窗口限制和噪音資訊),以確保輸入LLM的資訊是最相關且精簡的。
目前更先進的架構為模組化RAG(Modular RAG),提供了高度的適用性和多樣性。它引入了特定的功能模組,如搜尋模組(Search)、記憶模組(Memory)、路由模組(Routing)等。模組化RAG允許各模組間替換或重新配置,甚至可以進行端到端的訓練,不再局限於線性的檢索生成流程,開發者可以根據任務需求客製化。
RAG與微調的比較
RAG和微調(Fine-tuning)是兩種優化LLM的主要方法,兩者並非互斥,而是可以互補的。主要差異在於資料庫更新的方法:
RAG就像給LLM一本百科全書,只更新資料庫中的知識,並不改變模型本身的參數,適合需要動態更新知識、高精確度檢索以及高可解釋性的場景。
微調則須重新訓練模型、調整參數,就像讓學生內化知識成為長期記憶,適合需要複製特定結構、風格或場景,能為模型行為專門客製化。此兩者的差異可參考表1的 說明。
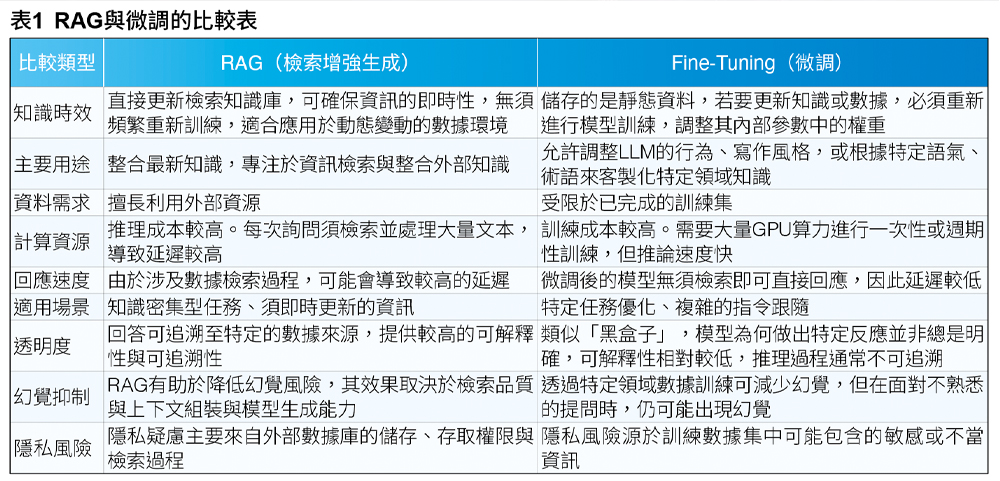
儘管有上述差異,但RAG與微調可互補,例如可以先利用微調讓模型學會特定的輸出格式或專業領域的術語(如醫療用正式報告格式),然後在推理時搭配RAG來獲取最新的具體病例或研究數據。
RAG的三大核心技術支柱
RAG的檢索與生成流程由三大關鍵環節的技術整合:檢索(Retrieval)、增強(Augmentation)以及生成(Generation),RAG的主要目標是讓語言模型「先查資料,再依資料回答」。整體流程為:使用者問題→檢索相關資料→增強成上下文→語言模型生成答案。
檢索(Retrieval)
從海量知識庫中,精確快速地找到與查詢者問題相關的資訊片段,為後續推理邏輯的階段提供可靠的依據。一般而言,RAG檢索流程可拆解成幾個步驟:
可以類比為圖書館的查書系統:預先依據書本類別建立索引,查書時,即可根據主題、關鍵字快速定位到正確的書架與書籍。首先,將原始文件(如PDF、網頁)切割成小塊(Chunks或Passages),以提升檢索的精準度。常見作法包括固定長度切分(例如每300~500 tokens為一個單位)、語意切分、段落切分等。接者,透過Embedding Model(如OpenAI text-embedding-3或Sentence-BERT)將每一個Chunk轉換成高維向量(Vector),並存入向量資料庫(Vector Database)中以便搜索。
當使用者提出問題時,系統將問題也轉換為向量(使用與文件相同的Embedding Model),接著做相似度比對,透過計算向量之間的距離(例如餘弦相似度Cosine Similarity),從資料庫中檢索出語意最相近的前K筆內容(Top-K Chunks)。
被普遍認為是提升系統表現最有效也是最實務的方法,結合稀疏檢索與稠密檢索兩者優勢,以同時兼顧召回率與精準度:
‧稀疏檢索:尋找文件中精確出現的關鍵字,如專有名詞、產品型號。常見方法如BM25,是一種衡量「關鍵字與文件相關性」的排名演算法。其缺點為無法處理「詞彙缺口(Vocabulary Gap)」。如果使用者查詢的用詞與文件中實際參考的資料文檔不同(如「老鼠」與「齧齒類動物」),即使語意相同,也可能無法成功檢索。
‧稠密檢索:透過將文字轉為數學向量,以向量化的方式表示語意,計算語義空間中的距離便能理解文字背後含意,即使詞彙不同也能成功比對。其缺點為容易遇到「假相關」;有時兩個句子語義相近,但確切的資訊(如數字、特定的法律條文編號)卻不一致,仍可能被判定為高度相關。
檢索後的初步結果(Top-K)往往包含雜訊或語意重疊的內容。因此,使用更精細的模型(如Cross-Encoder)對初步結果重新排序,移除重複內容或相似度不足的內容。同時,根據時間、來源等條件進一步篩選,確保輸入模型的是「最精華」的資料。
增強(Augmentation)
負責將檢索到的資訊有效地與「使用者原始問題」整合、轉換為語言模型可理解的上下文(Context),注入到語言模型中:
系統會將檢索到的資訊(如程式碼片段、研究論文)與用戶的原始問題(Query)進行整合,按照相關度依序排列,並加入特定的指令,形成一個邏輯連貫的提示詞(Prompt)。
建立一個優化模型回應的模板設計。除了提供參考資料外,還可以加入少樣本學習範例,能引導模型更好地遵循指令格式(如JSON輸出)並進行邏輯推理。提示詞工程範例如圖4說明。
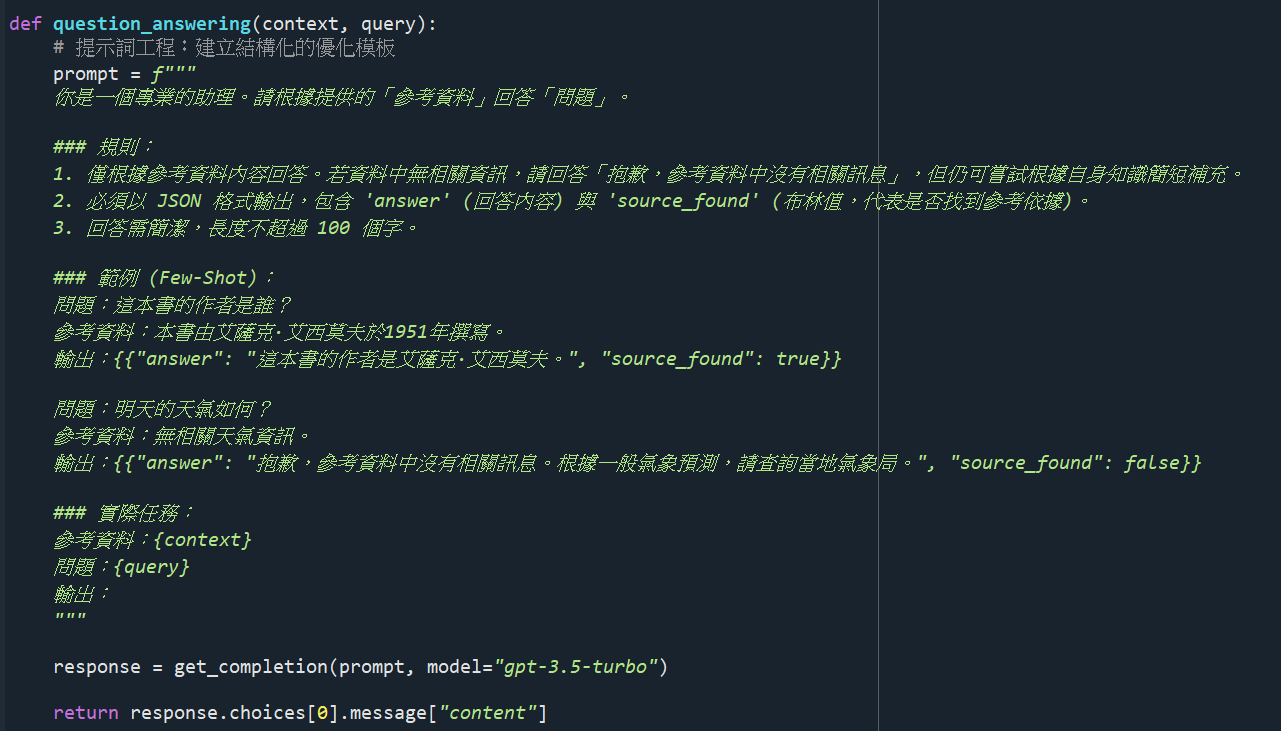 圖4 提示詞工程範例。
圖4 提示詞工程範例。
生成(Generation)
由大型語言模型根據「用戶的原始問題(Query)」+「增強後的上下文(Context)」生成最終回應,同時利用自身的語言能力與先前檢索到外部知識,產生較精確、較貼題的輸出,例如回答問題、摘要文件、撰寫說明等。此目的為提高回答的準確性與可信度,並有效降低幻覺。
模型讀取包含背景知識的Prompt。
模型不再是天馬行空地猜測,而是被約束在提供的Context範圍內進行總結、翻譯或回答。
較先進的RAG系統會要求模型在生成答案時標註資料出處,實現可追溯性,這在專業領域(醫療、資安)至關重要。
RAG的評估與驗證
評估RAG系統的表現比評估一般LLM更複雜,因為它涉及「檢索品質」與「生成品質」的雙重指標。
RAG系統的評估重點在於檢索到的內容是否精確、是否包含回答問題所需的資訊,如NDCG(Normalized Discounted Cumulative Gain)和命中率(Hit Rate)。一般LLM則側重於評估LLM生成的內容是否從檢索到的上下文中推導出來(而非幻覺),以及是否切題,其中對於有標準答案的任務,可使用F1分數或EM(Exact Match)衡量精確度;對於無標準答案的任務,則須評估語義相關性。
RAG三大核心指標
為了標準化RAG的評估,主要關注三大核心指標:
‧上下文相關性(Context Relevance):檢索到的內容是否與問題相關。
‧答案忠實度(Answer Faithfulness):生成的答案是否完全來自檢索到的上下文,而非幻覺或偏見,確保模型沒有胡編亂造。
‧答案相關性(Answer Relevance):確保生成的回答確實解決了用戶的問題與需求。
四大核心能力
除了上述評估指標外,完整的RAG評估還包含對以下四項能力的測試,旨在衡量LLM在整合檢索到的資訊後,其回答的適應性與穩健性:
‧噪聲魯棒性(Noise Robustness):測試RAG系統在檢索到與問題無關或干擾性資訊時,LLM是否仍能準確辨識並過濾雜訊,維持正確回答的能力。
‧拒絕回答(Negative Rejection):當檢索到的資訊不足以回答問題時,評估LLM是否能正確判斷資訊缺失並拒絕回答,而非強行編造、生成錯誤答案。 ‧資訊整合(Information Integration):評估RAG系統是否能從多個檢索到的片段中整合資訊,以回答複雜問題。
‧反事實魯棒性(Counterfactual Robustness):測試RAG系統在面對錯誤時或與事實相悖的資訊時的辨識與處理能力。
針對RAG表現的自動化評估與基準測試
由於人工評估RAG的表現耗時費力,不僅需要手動標記正確標準答案,還須建立大量資料庫等,為了提高評估的效益與加速RAG的評估週期,因而發展出多種測試用的自動化評估工具與基準。
利用Ragas、ARES或TruLens等框架,透過LLM來自動判定上述衡量RAG表現的指標,通常不需要人工標記正確答案的情況下即可進行無參考的評估(Reference-free)。改為直接利用如GPT-4的AI模型作為判斷與衡量工具(如同考試的評分閱卷老師,給定「一定的評分標準表,即評估框架」;LLM老師依據「考生的答案,即來自RAG檢索內容與回答」,進行語意判斷,為RAG表現打分數),實現自動化驗證與評估以及「LLM-as-a-Judge」,大幅降低人工標註成本。
使用如Retrieval-Augmented Generation Benchmark(RGB),採用公開基準集來測試RAG系統在噪聲魯棒性、拒絕回答等方面的能力。針對特定應用場景(如法律),除了使用公開基準集外,通常需要自建標準數據集(例如整理法院判例、法條學說並進行人工標註),以確保系統符合特定的業務需求與準確度標準。
待續
本文完整介紹了RAG的發展背景及其相關技術,下集文章將繼續未完的說明,以情境模擬的方式透過LM Studio建立本地端RAG,並模擬Ragas自動化評估工具。
<本文作者:社團法人台灣E化資安分析管理協會(ESAM, https://www.esam.io/)中央警察大學資訊密碼暨建構實驗室 & 情資安全與鑑識科學實驗室(ICCL and SECFORENSICS)1998年成立,目前由王旭正教授領軍,並致力於資訊安全、情資安全與鑑識科學、資料隱藏與資料快速搜尋之研究,以為人們於網際網路(Internet)世界探索的安全保障(https://hera.secforensics.org/)>