應用遞送方案提供負載平衡、應用健康檢查等等諸多的功能,而每一筆交易都會經過負載平衡器的處理,因此應用遞送服務可以掌握的資訊非常多,當管理者需要了解問題所在或是確認連線,透過交易的日誌紀錄及分析,就能夠找出答案。
應用遞送方案在客戶環境內是一個非常重要的構件,無論是提供負載平衡、應用健康檢查,或是Reverse-Proxy的功能,這個構件就是在用戶最重要的應用前面,每一個交易都會經過負載平衡器的處理。但也因此,應用遞送服務可以看到的資訊非常多,當管理者需要了解目前核心業務的效能為什麼不好,或是確認連線問題,負載平衡器都能夠提供相當多的重要情報。
NSX Advanced Load Balancer方案在設計之初,就把交易的日誌紀錄與分析考量進來作為方案的基礎配置,客戶購買了NSX ALB的方案後都可以直接取得這個重要的維運功能,不需要額外購買其他的授權。無論是在生產環境的告警以及合規稽核,或是應用測試過程中的驗證與除錯,後面討論的日誌分析與搜尋功能都能發揮極大的效益,甚至是很多企業由傳統負載平衡器改採用NSX ALB方案的主要原因。
首先,來看一個交易連線的日誌範例,如圖1所示。
 圖1 交易連線的日誌範例。
圖1 交易連線的日誌範例。
在圖1的日誌內,可以找到與這個交易相關的重要資訊包括:
‧此交易發生的時間
‧由用戶端到負載平衡器,到後端的Server間,以及應用回應的延遲時間估算。這裡的相關資訊會在後面做更詳盡討論。
‧前段與後段連線之HTTP回應碼
‧來源用戶的相關資訊,包含用戶的來源IP、此用戶IP透過查詢內部Geo資料庫所對應的國家、用戶使用的作業系統與瀏覽器、加密方式與版本等等。
‧這筆交易對應的Avi服務引擎與後端的對應伺服器
‧HTTP內的完整URI與其他請求及回應的資訊
上述的資訊其實是標準HTTP連線內都應該可以看到的,但與不同企業進行介紹NSX ALB日誌功能的過程中,還真的有很多客戶是第一次發現原來負載平衡器可以抓到這麼多資訊。例如作業系統型態∕瀏覽器類型,這些通常是用戶瀏覽器發起詢問時,透過HTTP請求表頭內的User-Agent欄位所帶的相關內容,此時主機端的應用程式就可以依據這些資訊,提供較好的回應格式。
日誌服務應用示範
在View All Headers內,若點開可以看到更進一步的詳細說明,如圖2所示。其中顯示了重要的資訊,例如X-Forwarded-For、X-Forwarded-Proto等應用需要確認的訊息也會記錄於此。
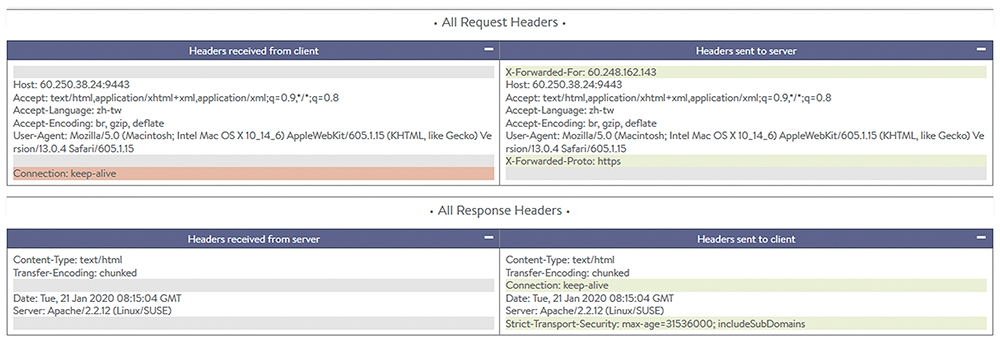 圖2 點開View All Headers後出現更多的詳細說明。
圖2 點開View All Headers後出現更多的詳細說明。
NSX ALB的交易日誌並非僅能在介面內查詢,管理者可以為了稽核、合規等理由希望在後端的Syslog Server做長期的日誌存放。
在圖3內,透過標準Syslog機制將NSX ALB的日誌往後端的Log Insight扔,下方就是透過Log Insight的互動介面看到同一筆交易的完整日誌。
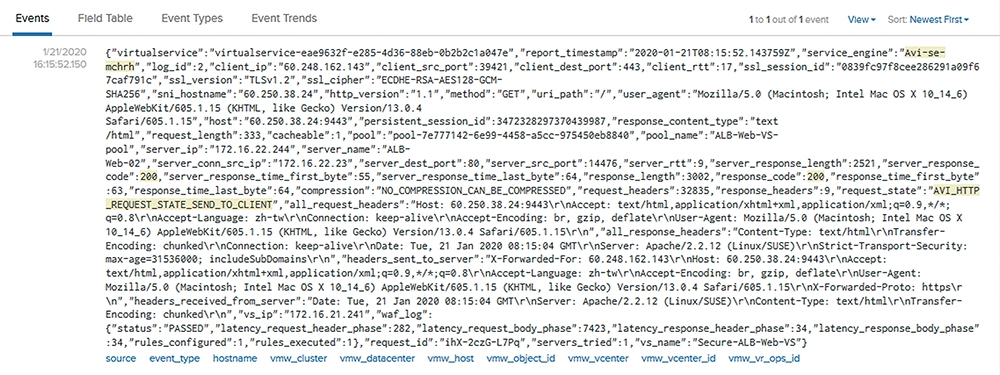 圖3 透過標準的Syslog機制將NSX ALB的日誌往後端的Log Insight扔。
圖3 透過標準的Syslog機制將NSX ALB的日誌往後端的Log Insight扔。
當然,NSX ALB的日誌服務不會僅針對HTTP/S的服務類型,純粹的TCP/UDP L4應用連線也會記錄。圖4所示是對應到一個TCP L4連線應用的日誌紀錄。與前面的相比,資訊就少多了,基本上就是用戶端(Client)到LB之間,以及LB到後端Server之間的兩個TCP連線相關資訊。
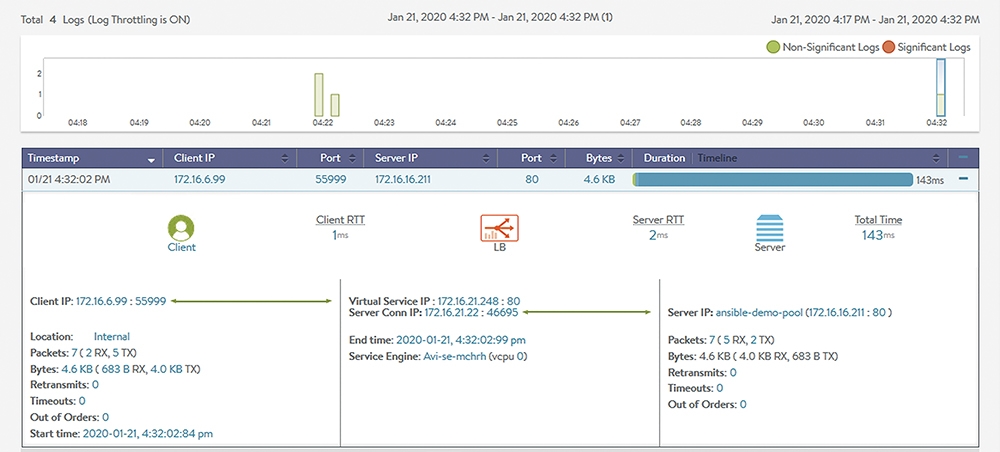 圖4 對應到TCP L4連線應用的日誌紀錄。
圖4 對應到TCP L4連線應用的日誌紀錄。
這個連線的日誌當然也可以在外部的Syslog Server進行儲存,圖5所示就是上述日誌的Syslog紀錄。
 圖5 上述日誌的Syslog紀錄。
圖5 上述日誌的Syslog紀錄。
這麼詳盡的日誌,在核心應用的維運上可以發揮非常強力的作用。想像一下一個日常經常發生的情境:重要的對外業務服務,客服那邊傳來了狀況,用戶抱怨現在為什麼連線變得超慢,可以馬上解決嗎?碰到這樣的狀況,很快地看了一下維運方案的Dashboard,好像各個構件都運作正常沒有告警。那接下來怎麼辦?這裡的癥結,是網路端的問題,業務放在虛擬化上造成的延遲,還是資料庫交易能力不足,或是儲存IO出了狀況,或是負載平衡器本身的效能不足呢?
如果沒有一些量化的維運資訊,大家就會指來指去說問題不在自己身上了。當然,要解決上述的問題,有很多方案可以導入。由網路到系統及儲存的Dashboard與告警機制、應用效能監控方案(Application Performance Monitor)、網路監控方案等等。但如同前篇討論,應用遞送方案位於核心業務的前方,經手各項重要交易,本身就能看到相當多資訊。圖6是前面就貼出的交易日誌範例,接下來,特別討論以圖中方框框選起來的交易End-to-End Timing部分,以及裡面的各部分時間定義。
在圖6中,整筆交易的End-to-End Timing是最後Total Time所顯示的81毫秒(ms),這代表此交易的總用戶體驗時間。但在整個時間內,又可切分為下列的時間段細項:
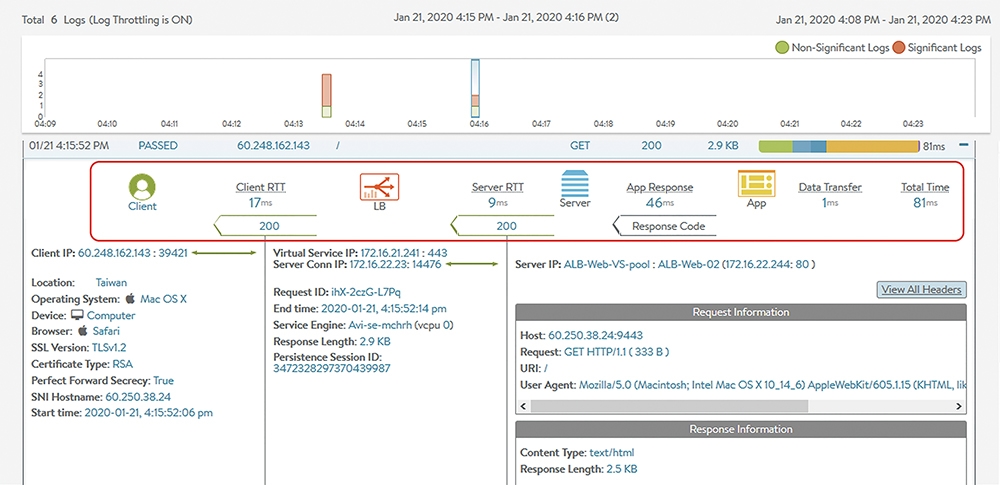 圖6 交易日誌範例。
圖6 交易日誌範例。
‧Client RTT(Client Round-Trip Time):由用戶端的瀏覽器∕行動設備到負載平衡器間的網路延遲時間。這段時間是資訊團隊無法控制的,延遲時間長,可能表示用戶從遙遠的美國連線回台灣,或是用戶本身的Internet線路壅塞等等。這裡的時間很容易估算,例如透過TCP連線前面的三向交握(Three-way Handshake)就能估算出由用戶端到服務引擎間的網路時間。
‧Server RTT(Server Round-Trip Time):由負載平衡器到後端Pool內伺服器的網路延遲時間。這裡已經在客戶可以管控的環境內,如果過大,當然應該進行處理。Server RTT是由負載平衡器到Server間的TCP三向交握連線來估算出,一般來說應該很低。如果出現不合理的長延遲時間,大概會是下列幾個原因,包括:負載平衡器(NSX ALB的服務引擎)與後端伺服器放置在不同地點,兩地間的網路延遲時間長,譬如服務引擎放在公有雲上,但是應用伺服器是在企業自己機房內;企業本身的資料中心網路/伺服器網卡出現問題或壅塞,造成連線回應過慢;後端伺服器可能是遭到惡意攻擊或效能過低,TCP Stack壅塞(簡而言之,被打爆了),因此新的TCP連線要求處理時間變長。
‧App Response:應用回應的延遲時間,這是一個估算值。應用回應的原因很多,可能是後端設備IO不好、資料庫處理能力差、App Server效能有問題等等都有可能。NSX ALB服務引擎所在的位置無法判斷是哪一段有狀況,但可以看到的是當用戶發出HTTP Method的要求時(如GET、POST、PUT),服務引擎過了多久才收到後端Server的回應。此時把這個時間扣除Server RTT的網路時間以及資料傳輸的需求時間(Data Transfer),就是App Response Time。
‧Data Transfer:應用資料本身的傳輸時間。NSX ALB是以服務引擎收到HTTP回應資料的第一個Byte到最後一個Byte所花費的時間來估算。
回到前面的討論。那麼當用戶抱怨應用效能不好時,NSX ALB的日誌分析能夠提供什麼協助?可以發現各個交易所花費的總時間,而更重要的,找到問題的發生點是在網路上,或者在系統上。
如果是Client RTT過高,能做的事情不多,回報客戶說聲抱歉,因為所在的地點實在太遠。當然,後續應該討論是不是要導入CDN或是把應用藉由Global Load Balancing放在全球不同地點。如果Server RTT過高,網路Team應該檢查Data Center Networking這段是否有壅塞,Server Team應該確認是否有過大TCP DDoS攻擊,或是LB/Server間的放置地點太遠。
而很常見的是App Response Time過高,此時就應該往後找問題。這裡要再次強調,NSX ALB的方案並不是APM(Application Performance Monitor)。NSX ALB的服務引擎只看到應用回應時間過長,但不會知道這個問題點是在Web、AP、DB哪個構件上,或者不是儲存IO有問題。可是大家在不需要購買昂貴的APM方案,在應用上植入外掛/Agent的狀況下,光採用NSX ALB的原生功能,就至少可以判斷問題是在網路或應用端,這是非常有價值的!
關鍵字搜尋日誌資訊
行文至此,大家應該可以看到在NSX ALB方案內原生就能提供非常詳細的連線日誌資訊。回到實務問題,無論是在應用進行測試或是實際上線,重要系統的連線資訊成千上萬甚至更多,要如何快速找到希望能看到的日誌資訊,能夠馬上進行問題排除呢?
這裡當然也是此方案的強項了。NSX ALB Controllers本身就內建像是日誌分析系統的相關功能,無論是透過時間或是對應相關條件的關鍵字,都可作為搜尋的條件。在圖7內,可以看到進行搜尋的方式包含了:
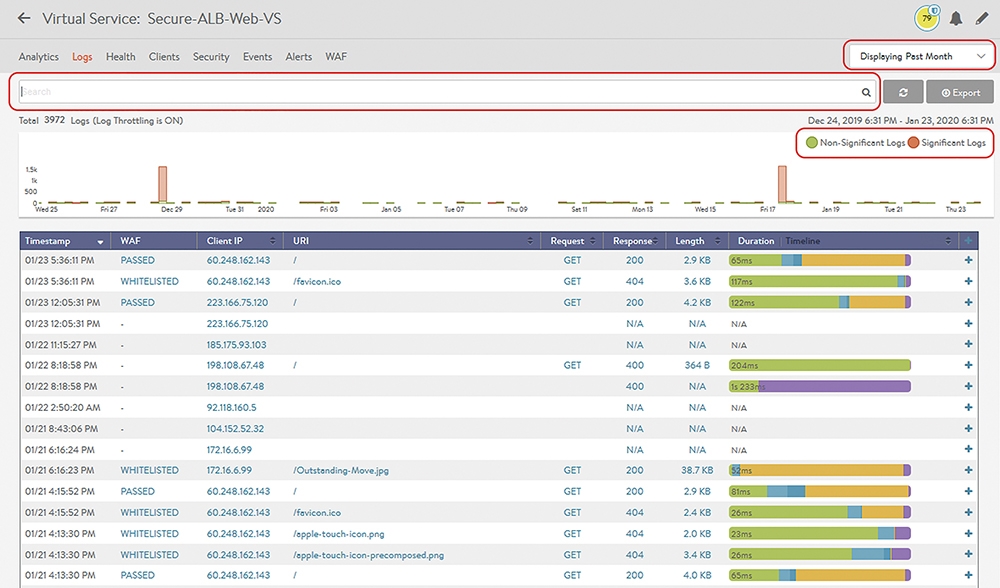 圖7 多種方式進行日誌搜尋。
圖7 多種方式進行日誌搜尋。
‧右上角可定義查詢日誌的時間區
‧上方的搜尋欄內可輸入一到多項搜尋條件,例如應用回應時間、用戶端資訊等等。
‧選擇要查詢的是重要日誌(Significant Logs)或是非重要日誌(Non-Significant Logs)。重要與非重要日誌的定義,在後面會再說明。
‧下面會顯示出相關符合條件的日誌時間軸,以及各日誌大要資訊,點開了就可以看到完整內容。
查詢及分析日誌紀錄
這裡舉出幾個例子,例如現在管理者想要查詢在一個月內,應用回應時間超過1.5秒的所有連線日誌。如圖8所示,當選擇時間是在一個月內,而搜尋列內輸入應用回應時間>1,500(ms)。此時在時間軸內就可以看到約是在12月28日以及1月17日時,有大量這樣的應用效能不佳事件發生。或者,想要特別查詢在特定區間內(例如圖9的12月25日中午到1月5日凌晨),來自台灣(client_location=Taiwan)且採用Safari瀏覽器(client_browser=Safari)的用戶,有哪些需要特別注意的重要連線(Significant Logs)。
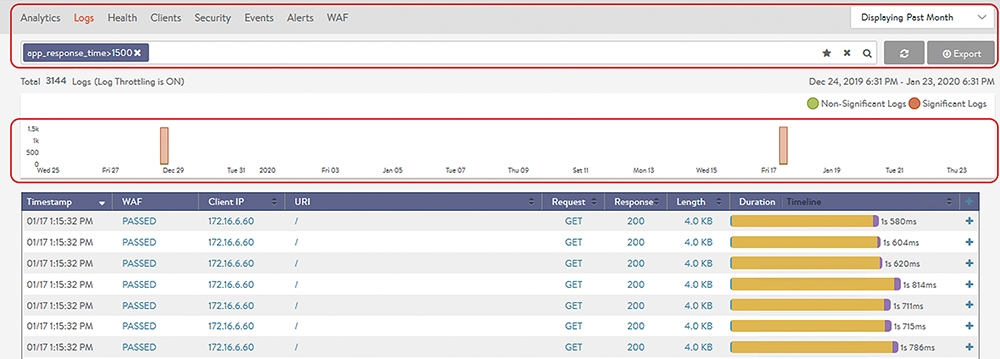 圖8 在搜尋列內輸入應用回應時間。
圖8 在搜尋列內輸入應用回應時間。
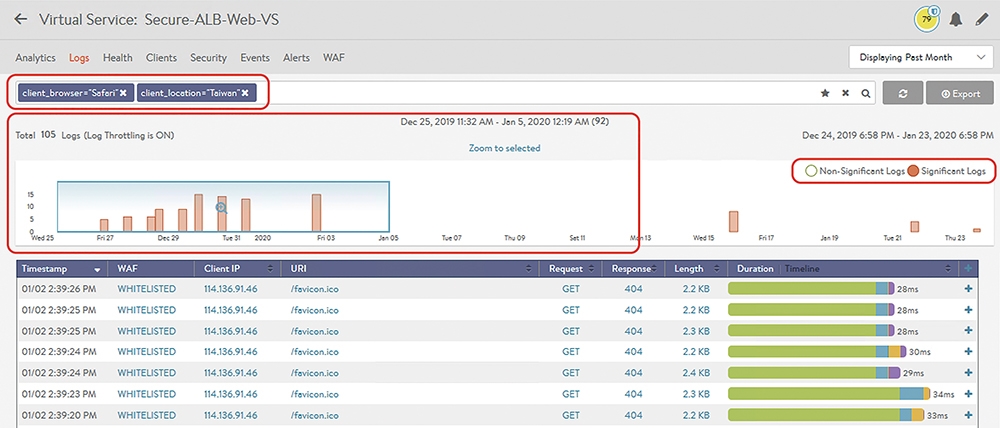 圖9 查詢在特定區間的重要連線。
圖9 查詢在特定區間的重要連線。
另外,或許又想要做一些統計。在上個月,所有連線到這個應用的用戶中,分別來自哪些國家以及對應的比例呢?NSX ALB的日誌內除了搜尋外,在右邊也可以拉出日誌分析。如圖10所示,選擇用戶分析項內的Location,就可以看出這個服務有哪些不同國家的用戶曾在這個月內進行連線要求。
 圖10 查詢有哪些不同國家的用戶曾在這個月內進行連線要求。
圖10 查詢有哪些不同國家的用戶曾在這個月內進行連線要求。
何謂Sgnificant Logs與Non-Significant Logs
這裡需要解釋一下什麼是「Significant Logs」與「Non-Significant Logs」。NSX ALB方案內有預先定義一些用戶交易連線「不正常」的狀況,當一個連線符合了這些狀況,預設就一定會被記錄下來,並且被定義為「Significant Logs」。不是完整的清單,但一般會被當作「不正常」的連線大致上可分成下列這幾類:
‧用戶到負載平衡器,或負載平衡器到後端Server的連線無法建立。
‧連線被不正常中斷。例如SSL的協議因為兩邊版本不符合,所以無法建立連線。
‧網路連線的異常事件,例如TCP要求的重傳數量過大、網路延遲時間過高等等。
‧HTTP相關的異常事件,像是異常的HTTP回應如4XX/5XX、應用回應時間過長等等。
而如果不符合上述的條件,也就是說,是一個非常正常、品質相當優良的連線,就會被當成「Non-Significant Logs」。通常在生產環境,因為應用連線數量龐大,會想注意的當然是Significant Logs,而正常完成的連線,即使日誌不記錄也沒有關係。但如果是在測試階段,或是有規則要求所有的用戶連線都必須在負載平衡器上有稽核紀錄,那此時就可能有必要啟用「Non-Significant Logs」了。
但當然,此時包含NSX ALB的服務引擎或Controllers在進行查詢時,就要考慮對於效能的影響,而且也建議將這些日誌往外部的日誌管理系統發送。一般來說,在生產環境內僅記錄Significant Logs即可,而Non-Significant Logs作為除錯之用。
結語
本文展示了NSX Advanced Load Balancer的日誌分析功能,事實上部分廠商的產品也有支援相關功能,但需要額外的授權與軟硬體,搜尋與分析功能也不見得強大,而這些功能在NSX ALB授權中都是內建的。下一篇文章,將介紹NSX Advanced Load Balancer在公有雲上面的運作方式。
<本文作者:饒康立,VMware資深技術顧問,主要負責VMware NSX產品線,持有VCIX-NV、VCAP-DTD、CCIE、CISSP等證照,目前致力於網路虛擬化、軟體定義網路暨分散式安全防護技術方案的介紹與推廣。>