本文將深入剖析最新vSphere 8的亮眼特色功能,讓管理人員對此有更深的認識與理解,並將實作示範vSphere 8中所支援的新式UDT機制,讓關機中卻有遷移需求的VM虛擬主機也能夠進行快速遷移,有效縮短資料傳輸時間。
在2022年VMware Explore大會上,VMware官方正式發布最新的vSphere 8版本。同時,從vSphere 8版本開始,VMware官方採用新的版本發布模型,分別稱為「初始可用性」(Initial Availability,IA)和「通用可用性」(General Availability,GA),簡單來說,新的版本發布方式和vSphere+雲端服務版本將保持一致。
首先要說明的是,當VMware官方發布RC和RTM之後,將會採用和GA相同測試品質和發布標準的流程,在2週後發布IA版本,接著在4~6週後發布GA版本,而無須像過去必須等待6個月之久才能取得帶有新功能和增強功能的版本,如圖1所示。
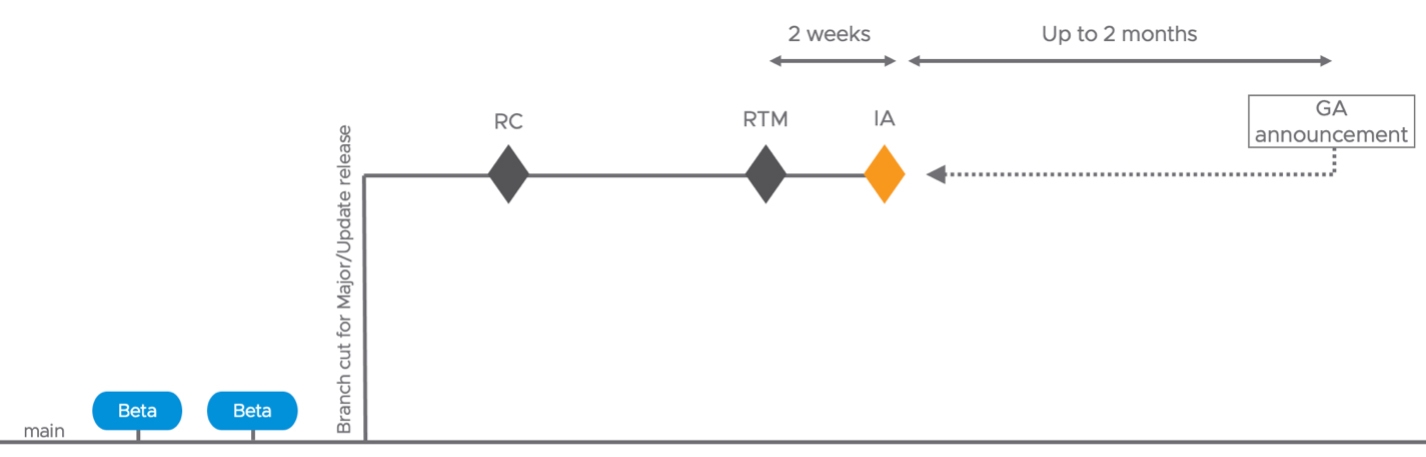 圖1 RC、RTM、IA以及GA版本發布週期示意圖。 (圖片來源:New Release Model for vSphere 8 - VMware vSphere Blog)
圖1 RC、RTM、IA以及GA版本發布週期示意圖。 (圖片來源:New Release Model for vSphere 8 - VMware vSphere Blog)
vSphere 8亮眼特色功能
最新發布的vSphere 8提供了許多新穎功能,分別說明如下。
新世代傳輸架構DPU和DSE
在過去虛擬化基礎架構中,管理人員已經很熟悉各種資源的規劃和調度,例如負責運算資源的CPU和Memory、負責圖形運算的GPU。同時,隨著AI人工智慧和ML機器學習的興起,許多管理人員應該已經發現到,底層負責傳輸大量資料的網路資源也必須跟上,才能讓各項資源的整合與整體服務之間相得益彰,這項新技術稱之為「資料處理單元」(Data Processing Unit,DPU),如圖2所示。
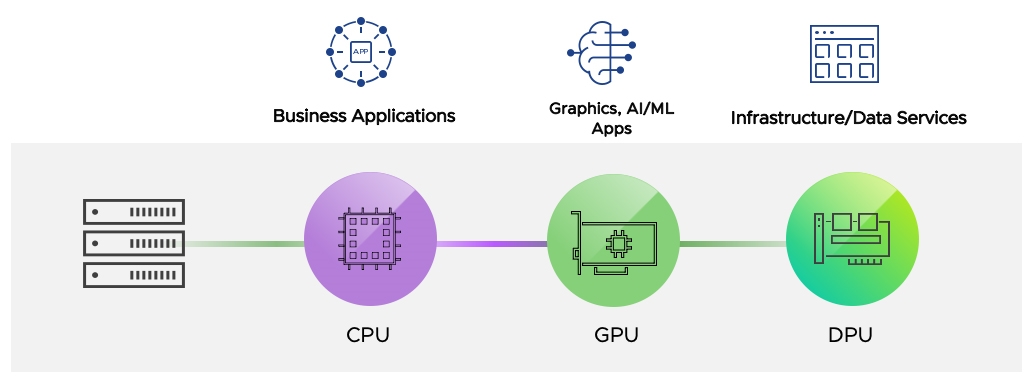 圖2 企業和組織資料中心除了原有的CPU/GPU資源外,現在也需要DPU資源。 (圖片來源:vSphere on DPUs: NOW Available on vSphere 8 | VMware)
圖2 企業和組織資料中心除了原有的CPU/GPU資源外,現在也需要DPU資源。 (圖片來源:vSphere on DPUs: NOW Available on vSphere 8 | VMware)
DPU目前以SmartNIC的型態推出,如圖3所示,外型雖然與PCIe介面卡相同,但SmartNIC內含ARM CPU處理器,以及支援編譯功能的加速器,並且通常配置10Gb到100Gb的多個通訊埠,以及一個用於管理用途的乙太網路通訊埠。最重要的是,SmartNIC有個本地端儲存資源,提供管理人員安裝軟體,例如將ESXi虛擬化管理程序安裝於其中。
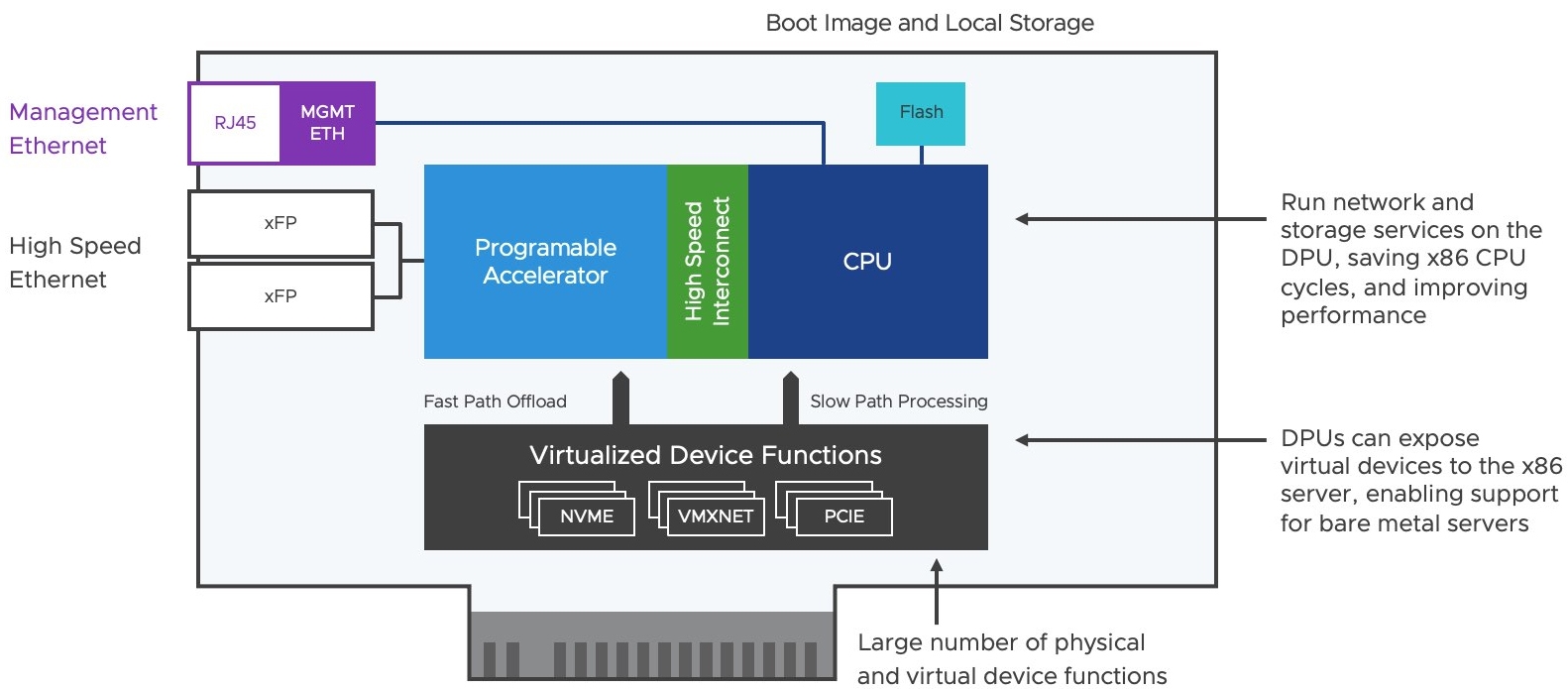 圖3 SmartNIC運作架構示意圖。 (圖片來源:The rise of DPUs in the Infrastructure | VMware)
圖3 SmartNIC運作架構示意圖。 (圖片來源:The rise of DPUs in the Infrastructure | VMware)
SmartNIC能夠整合高效能的網路介面進行資料傳輸,那麼安裝在x86硬體伺服器上的SmartNIC,以及x86硬體伺服器上原有的工作負載,例如NSX Service、vSAN Data Servies等等,如何無縫並且有效地卸載至SmartNIC上,這便是接下來所要討論的Project Monterey,如圖4所示。
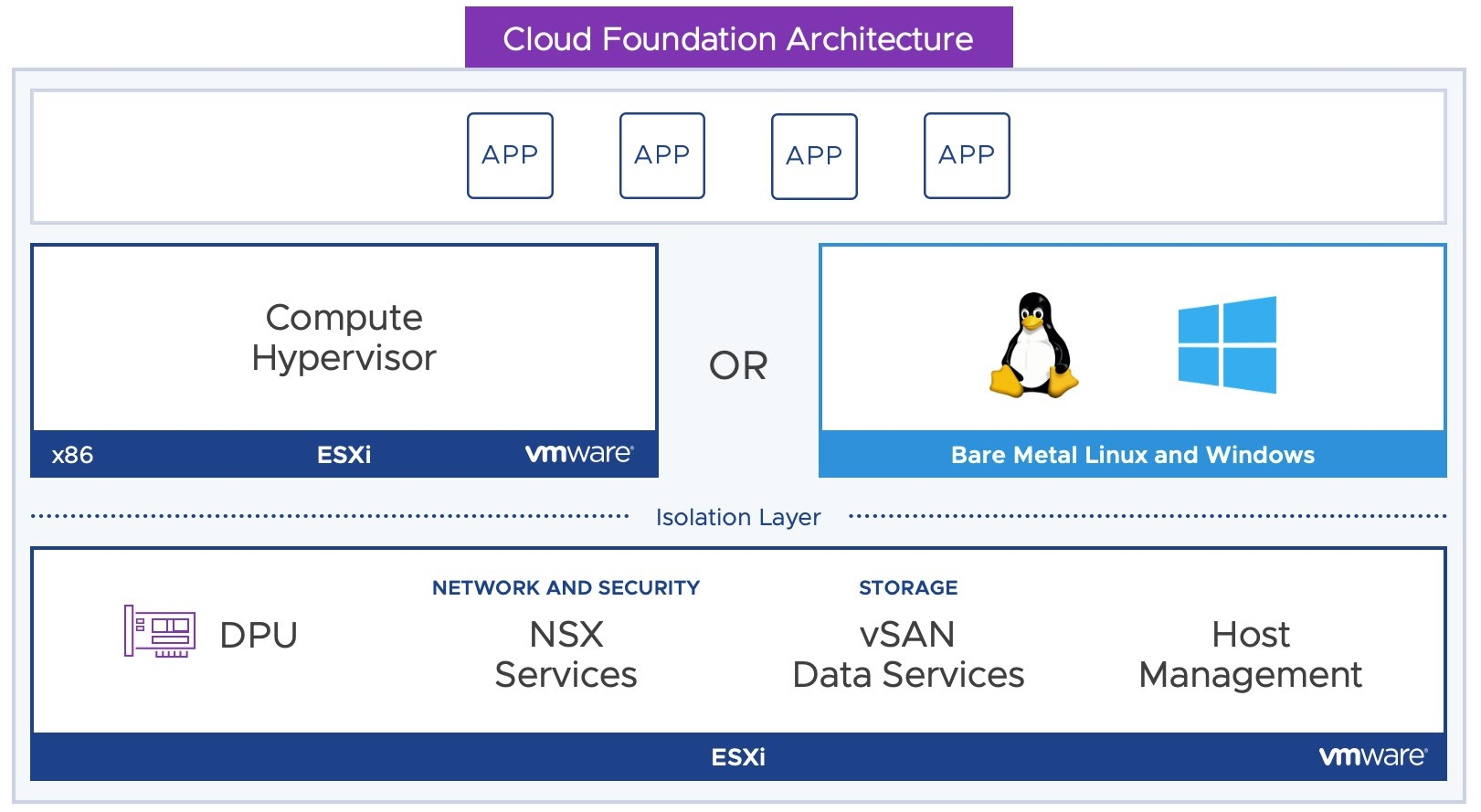 圖4 Project Monterey運作架構示意圖。 (圖片來源:The rise of DPUs in the Infrastructure | VMware)
圖4 Project Monterey運作架構示意圖。 (圖片來源:The rise of DPUs in the Infrastructure | VMware)
簡單來說,在最新vSphere 8版本中,推出的「分佈式服務引擎」(Distributed Services Engine,DSE)特色功能,如圖5所示,就是剛才所提到的Project Monterey正式版本。在vSphere 8運作架構中,現在可以直接在DPU上安裝另一個ESXi執行程序,讓上層的ESXi專心處理運算的工作負載即可,而NSX及vSAN Data網路傳輸作業的部分,則直接卸載給底層DPU上的ESXi處理,讓上層的ESXi能夠處理和承載更多的VM虛擬主機和容器。
 圖5 vSphere DSE分佈式服務引擎運作架構示意圖。 (圖片來源:Meet vSphere Distributed Services Engine | VMware)
圖5 vSphere DSE分佈式服務引擎運作架構示意圖。 (圖片來源:Meet vSphere Distributed Services Engine | VMware)
值得注意的是,企業組織除了配置DPU硬體介面卡外,還必須搭配最新的vDS虛擬分佈式交換器「8.0」的版本和NSX服務,並且在新增vDS分佈式交換器時,組態設定採用的DPU廠商,如圖6所示,才能順利將工作負載卸載到底層的DPU上,並且不會增加任何ESXi的CPU運算資源開銷。
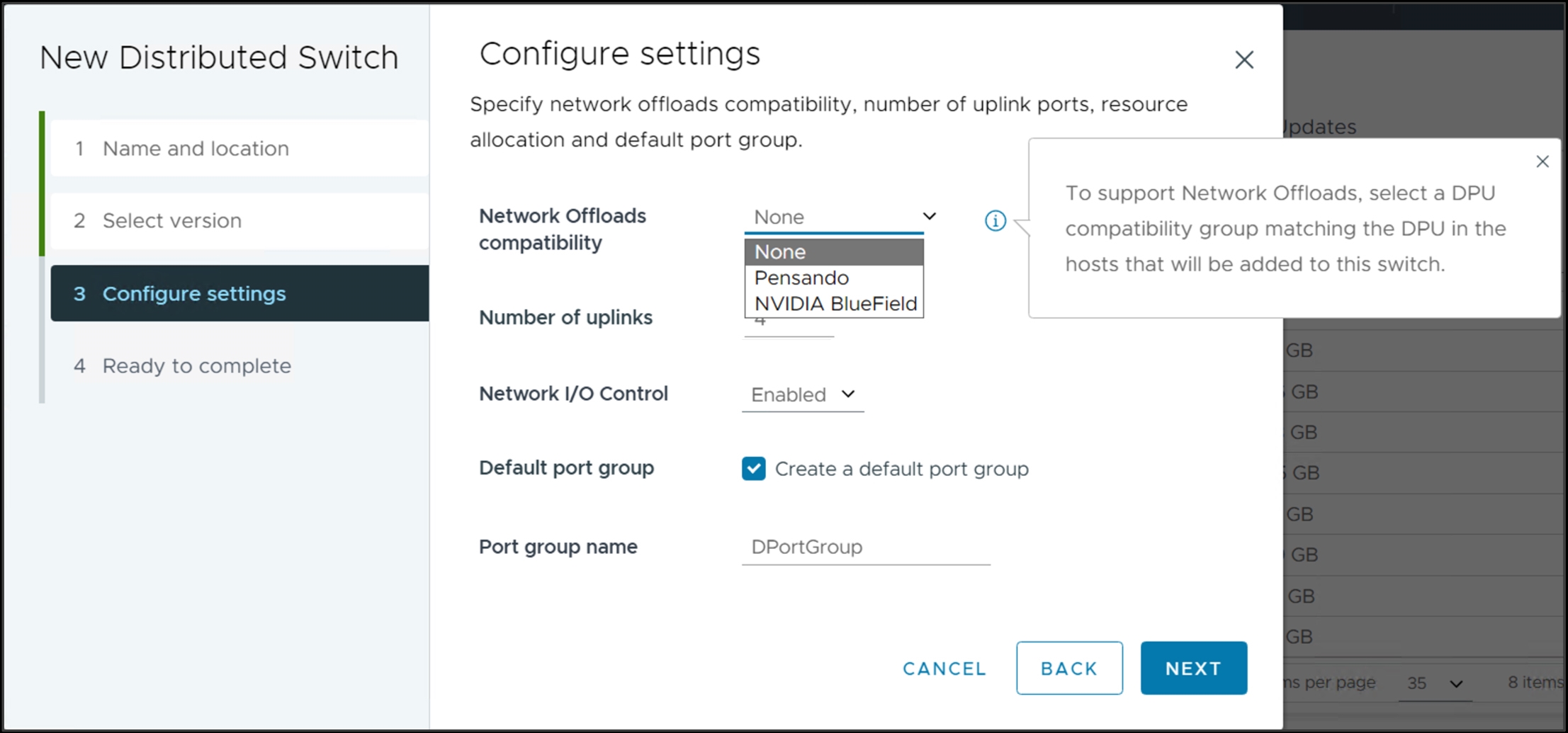 圖6 選擇DPU技術以便卸載網路服務至DPU。 (圖片來源:Simple Configuration for Network Offloads | VMware)
圖6 選擇DPU技術以便卸載網路服務至DPU。 (圖片來源:Simple Configuration for Network Offloads | VMware)
整合GPU和NIC裝置
透過最新的「裝置群組」(Device Group)機制,讓連接在同一個PCIe Switch的GPU和NIC裝置,除了支援原有廠商所提供的「互連」(Interconnect)機制外,不同的裝置之間可以透過裝置群組機制整合在一起,並且提供給上層運作的VM虛擬主機使用,有效減少管理人員手動處理的流程和時間,如圖7所示。
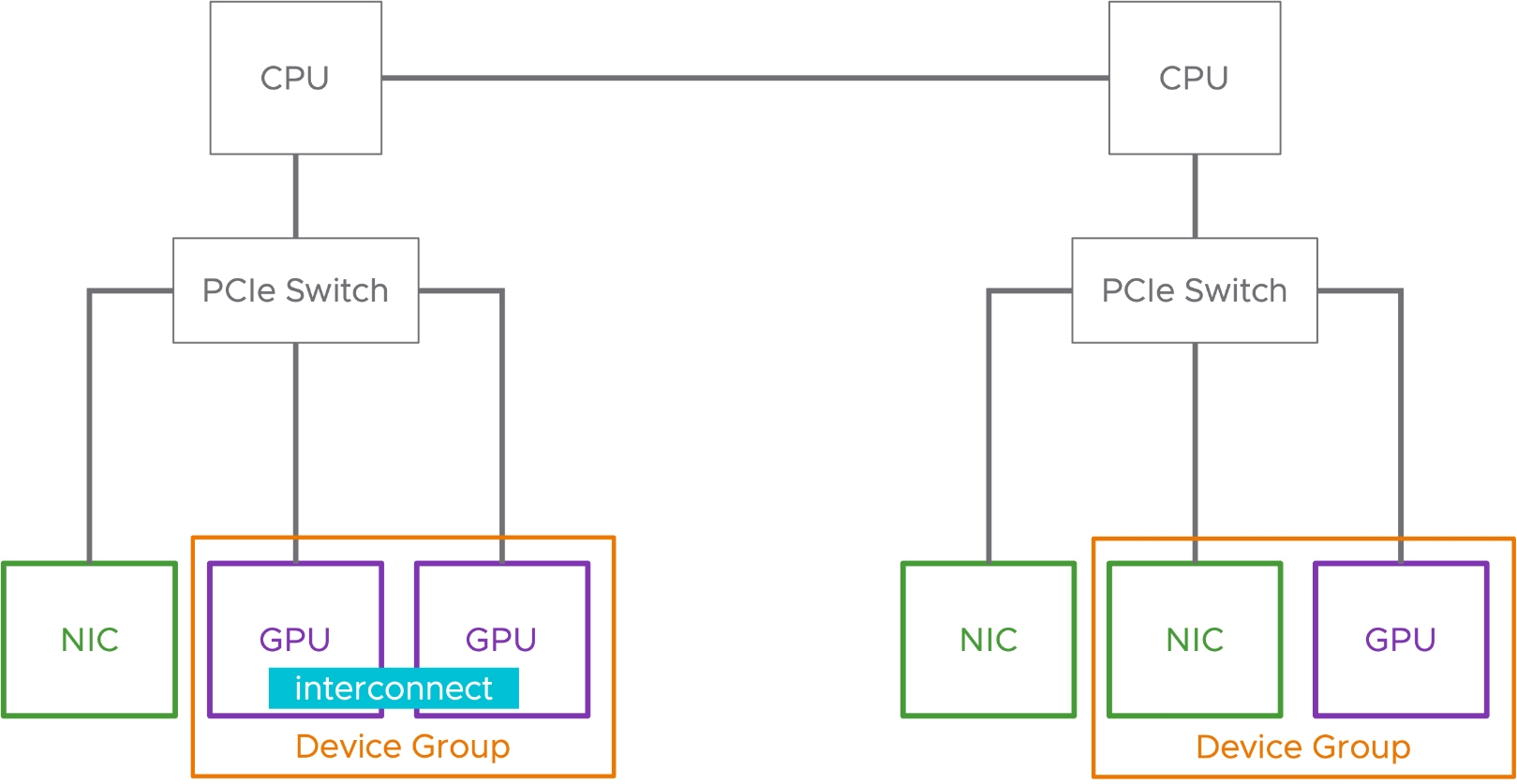 圖7 裝置群組機制運作示意圖。 (圖片來源:Unified Management for AI/ML Hardware Accelerators | VMware)
圖7 裝置群組機制運作示意圖。 (圖片來源:Unified Management for AI/ML Hardware Accelerators | VMware)
因此,透過裝置群組整合之後的單一裝置,對於VM虛擬主機來說,同樣只是新增一個單一PCI Device即可,並且配置裝置群組這樣的VM虛擬主機,仍然支援DRS VM Placement機制和vSphere HA高可用性機制。
當管理人員為VM虛擬主機配置裝置群組時,在新增PCI Device作業流程中,系統將會顯示已經裝置群組後的狀態,如圖8所示,第一個PCI裝置便是二個GPU透過NVLink所組合,第二個PCI裝置則是GPU整合NIC的裝置。
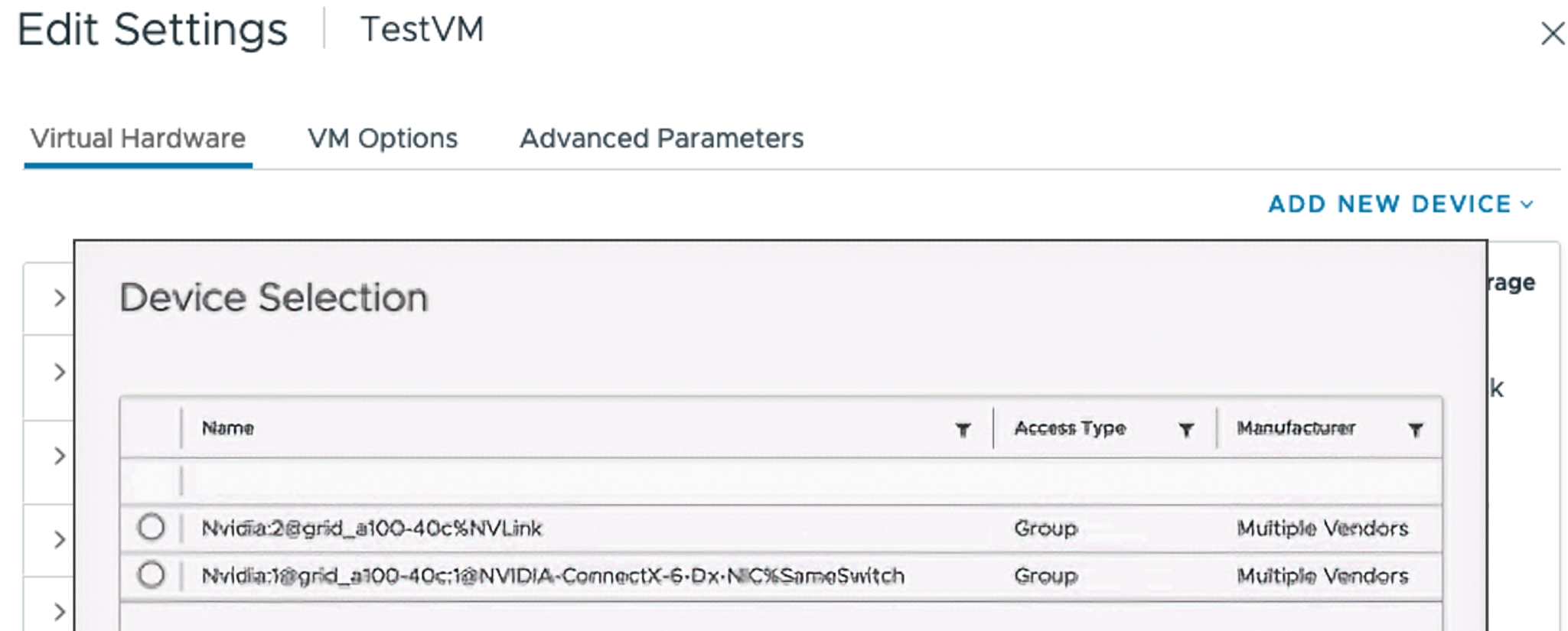 圖8 為VM虛擬主機新增裝置群組後的PCI Device。 (圖片來源:Simplified Hardware Consumption with Device Groups | VMware)
圖8 為VM虛擬主機新增裝置群組後的PCI Device。 (圖片來源:Simplified Hardware Consumption with Device Groups | VMware)
彈性化虛擬硬體裝置DVX
在過去的版本中,一旦組態設定VM虛擬主機使用DirectPath I/O直連機制時,可以得到完全使用底層硬體裝置效能的好處,然而,這個直連機制的副作用,會導致VM虛擬主機喪失某些vSphere特色功能。舉例來說,這樣的VM虛擬主機無法執行vSphere vMotion進行遷移,也不能被vSphere DRS自動執行調度作業,更無法被vSphere HA高可用性機制所保護。此外,也無法針對VM虛擬主機進行暫停作業,以及針對vMemory記憶體與vDisk虛擬硬碟進行快照。
現在,最新的vSphere 8推出「虛擬裝置擴充模組」(Device Virtualization Extensions,DVX),是基於Dynamic DirectPath I/O技術之上,並為裝置廠商提供新的運作框架和API。因此,底層的ESXi安裝DVX驅動程式,上層的VM虛擬主機使用支援DVX機制的虛擬裝置,達成高效能使用底層硬體的目的,同時又能保有vSphere特色功能,例如透過vSphere DRS自動執行調度作業,並被vSphere HA高可用性機制所保護,如圖9所示。
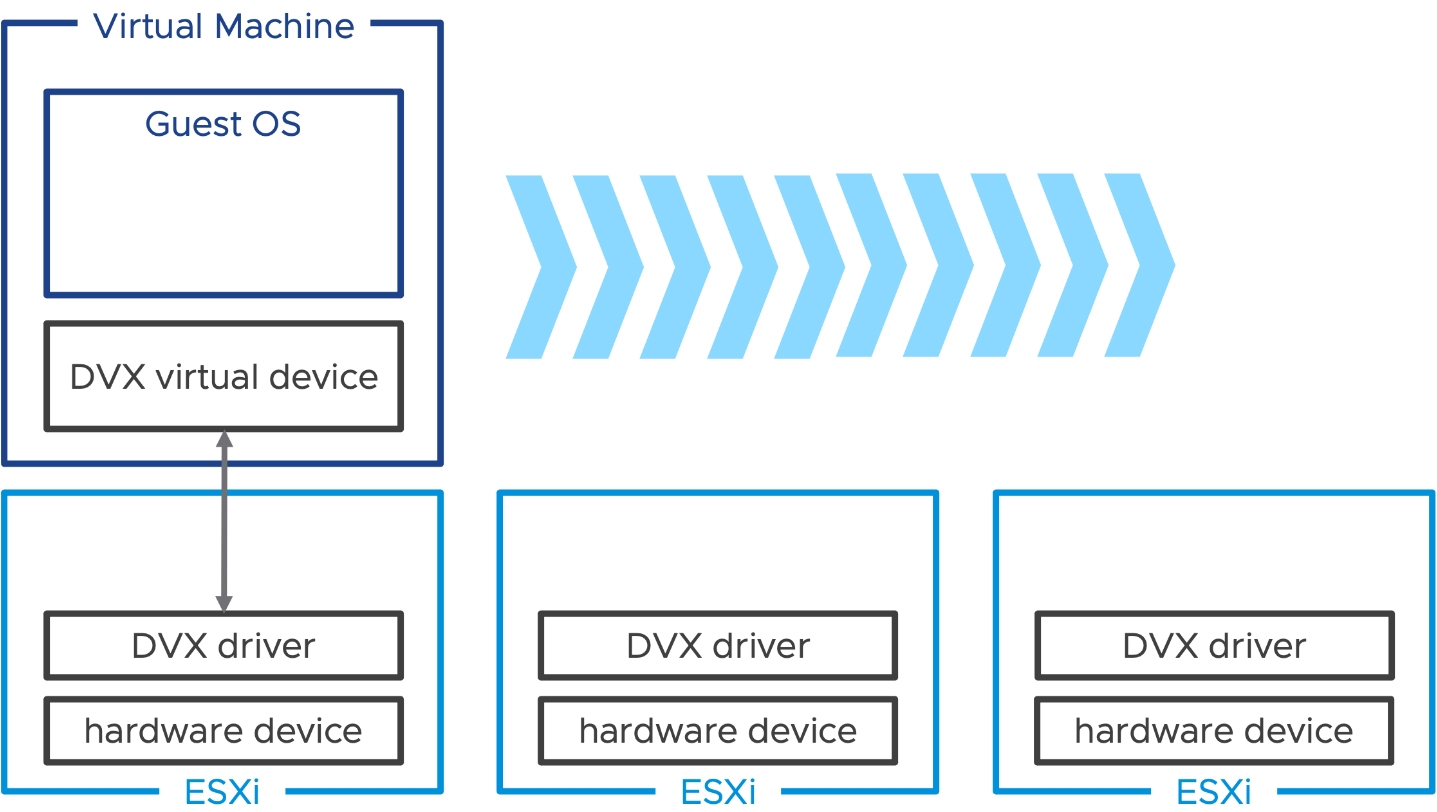 圖9 DVX虛擬裝置擴充模組運作流程示意圖。 (圖片來源:Next-Generation of Virtual Hardware Devices | VMware)
圖9 DVX虛擬裝置擴充模組運作流程示意圖。 (圖片來源:Next-Generation of Virtual Hardware Devices | VMware)
TKG 2.0和vSphere Zone
事實上,在vSphere 7版本時,便加入vSphere with Tanzu新特色功能,也就是將原有vSphere叢集重新建構為支援容器工作負載的Kubernetes叢集,讓ESXi虛擬化平台成為Kubernetes容器平台的Worker節點,並在ESXi上直接運作容器Pod。
同時,也推出支援私有雲和公有雲部署的TKG(Tanzu Kubernetes Grid),也就是支援企業在地端資料中心內部署的TKGs(Tanzu Kubernetes Grid Service for vSphere),以及部署至公有雲的TKGm(Tanzu Kubernetes Grid Multi-Cloud)。
現在,最新的vSphere 8版本重新整合為統一的Kubernetes容器平台,無論是部署到地端資料中心或公有雲,都是採用同一套的TKG 2.0版本,並且加入新的「vSphere Zone」隔離機制,支援跨越多個vSphere叢集進行整合,以便獲得最大的可用性和資源,並搭配來自Cluster API開放源始碼中的ClusterClass宣告機制,以便管理人員能夠決定將容器部署成跨vSphere叢集,或是在各自的vSphere叢集中互相隔離工作負載,如圖10所示。
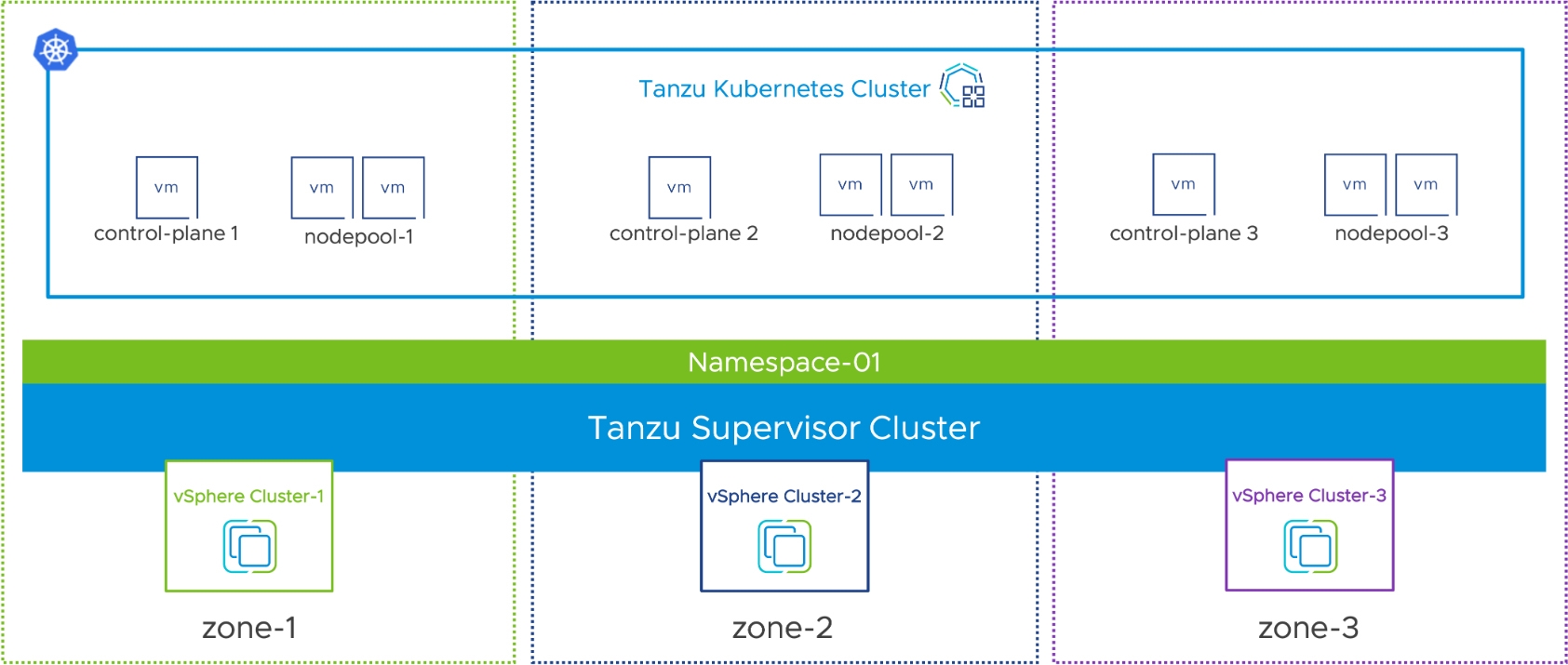 圖10 TKG 2.0和vSphere Zone運作架構示意圖。 (圖片來源:vSphere with Tanzu | Improving Workload Resilience in Modern Apps | VMware)
圖10 TKG 2.0和vSphere Zone運作架構示意圖。 (圖片來源:vSphere with Tanzu | Improving Workload Resilience in Modern Apps | VMware)
vCenter智慧型復原DKVS
對於vSphere基礎架構有管理經驗的人來說,一定知道整個vSphere運作架構的組態設定和統計資料都是儲存在vCenter Server管理平台當中。雖然統一式的集中管理有其優勢,然而碰上災難事件時卻有可能會產生盲點。
舉例來說,管理人員定期在每天凌晨3點為vCenter Server執行備份作業,但是vCenter Server卻在晚上8點時發生災難事件,此時即便立即為vCenter Server執行備份復原作業,但是從凌晨3點到晚上8點之間,仍然發生許多事件和各項工作負載的統計資料,因此復原後的vCenter Server管理平台,將會遺失這段期間的事件和統計資料。
在最新vSphere 8版本中,推出「分散式鍵值儲放區」(Distributed Key-Value Store,DKVS)機制,這項機制的設計原理在於,當vCenter Server管理平台發生災難時,這段期間發生的事件和統計資料也都會儲存在ESXi主機內。
因此,當vCenter Server管理平台進行災難復原後,與vSphere叢集中的眾多ESXi節點主機進行溝通,並將災難發生至上次備份時間期間的事件和統計資料取回,讓vCenter Server管理平台能夠迅速恢復,並且取得vSphere叢集和ESXi節點主機的最新資訊,如圖11所示。
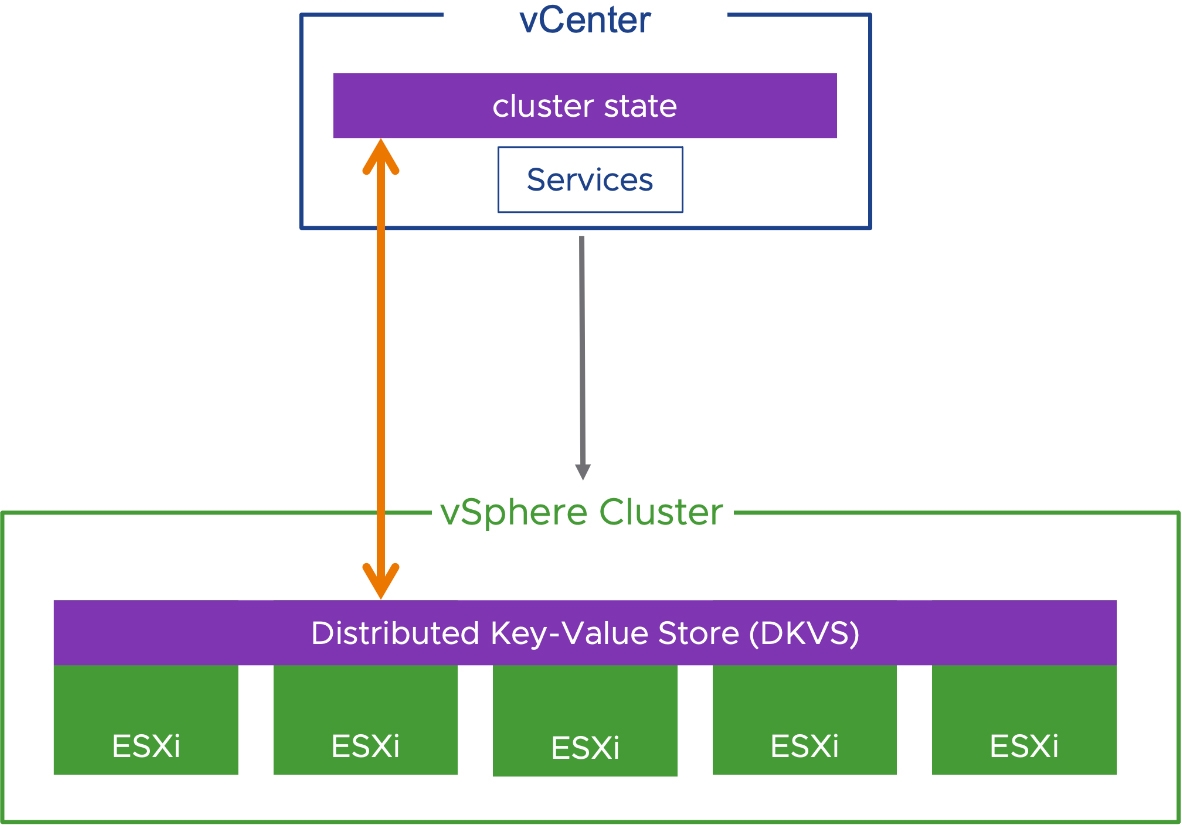 圖11 DKVS分散式鍵值儲放區運作架構示意圖。 (圖片來源:Enhanced Recovery of vCenter | VMware)
圖11 DKVS分散式鍵值儲放區運作架構示意圖。 (圖片來源:Enhanced Recovery of vCenter | VMware)
vMMR v2增強型記憶體監控機制
在vSphere虛擬化基礎架構中,對於工作負載的記憶體使用量和監控機制,一直是VMware努力增強和改進的方向,以便能夠承載更多的工作負載於vSphere架構中。從vSphere 7 U3版本開始,推出「vSphere記憶體監控和修復」(vSphere Memory Monitoring and Remediation,vMMR)機制。
最新的vSphere 8將原有vMMR記憶體監控和修復增強至vMMR v2版本,如圖12所示,透過更智慧的記憶體監控和修復機制,有效增強vSphere DRS自動化調度工作負載,讓VM虛擬主機和容器等工作負載能夠在最佳化的DRS調度決策中得到最充足的資源,確保VM虛擬主機和容器內的營運服務得到最佳效能和各項資源。
 圖12 vMMR v2記憶體監控和修復管理畫面示意圖。 (圖片來源:Enhanced DRS Performance | VMware)
圖12 vMMR v2記憶體監控和修復管理畫面示意圖。 (圖片來源:Enhanced DRS Performance | VMware)
vMotion Notifications敏感型應用程式專用
過去的vSphere版本中,雖然vMotion線上遷移機制,能夠滿足絕大多數應用程序的需求,並且在遷移過程中和遷移後,對於應用程式都是無縫遷移,並不會對應用程式造成任何影響。
然而,對於某些「時間敏感應用程式」(Time-Sensitive Application)、VoIP、叢集服務等,可能會產生不良的影響。舉例來說,可能在執行vMotion遷移期間導致VoIP掉線,或者觸動到叢集服務的心跳機制,因而導致引發容錯移轉叢集切換的動作。
因此,vSphere 8推出「vMotion通知」(vMotion Notifications)機制,能夠針對這些特定的應用程式進行通知後才遷移,確保應用程式準備完畢才進行遷移的動作。下列為VM虛擬主機執行vMotion通知時的執行步驟,如圖13所示:
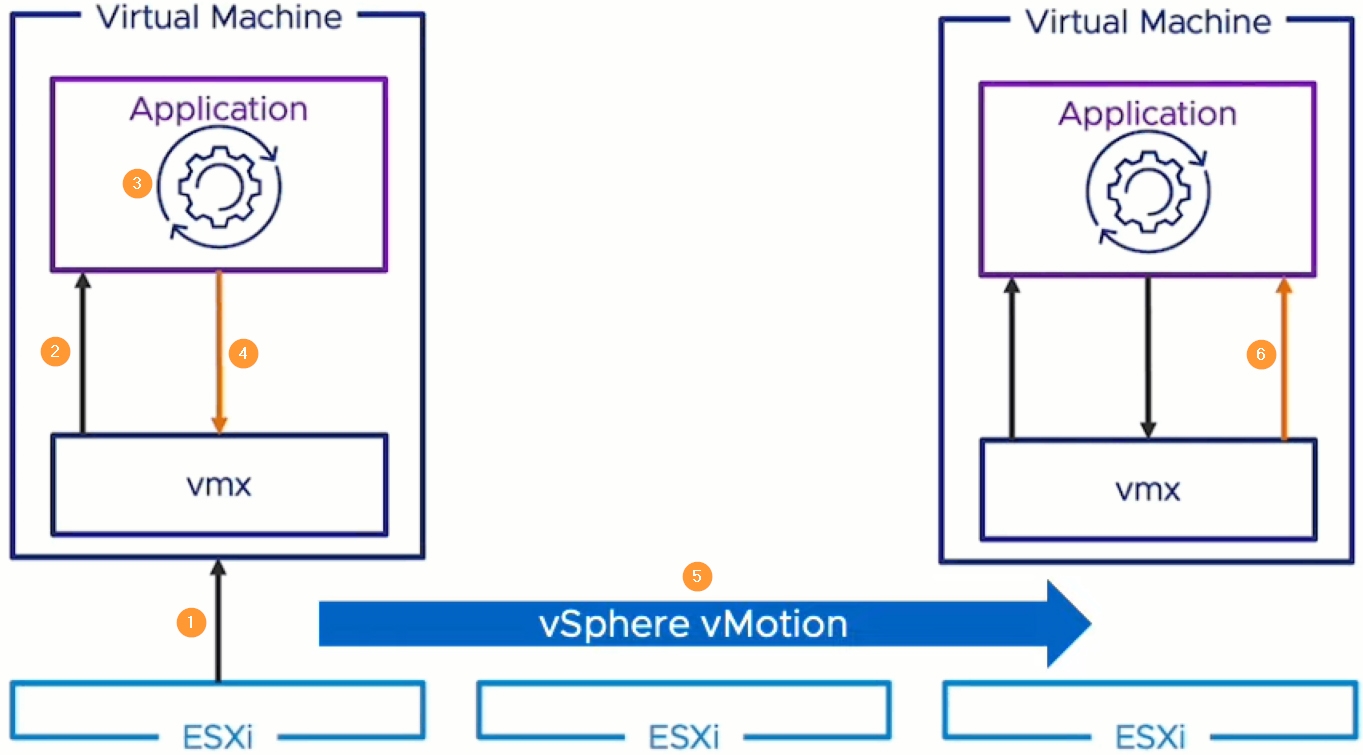 圖13 vSphere vMotion Notification遷移流程示意圖。 (圖片來源:vSphere vMotion Notifications | VMware)
圖13 vSphere vMotion Notification遷移流程示意圖。 (圖片來源:vSphere vMotion Notifications | VMware)
1.管理人員為VM虛擬主機執行vMotion線上遷移。
2.VM虛擬主機中的應用程式,收到vMotion遷移程序開始執行的通知。
3. 應用程式開始準備vMotion遷移作業。
4. 應用程式發送確認(Acknowledgement)訊息給vMotion遷移程序,確認可以開始執行遷移作業。
5.系統透過vMotion機制線上遷移VM虛擬主機至別台ESXi節點主機。
6.應用程式收到vMotion遷移程序通知遷移作業已完成。
值得注意的是,預設並不會為VM虛擬主機啟用vMotion通知機制,因為必須要為應用程式進行改寫的動作才行。此外,啟用vMotion通知機制的VM虛擬主機,也將無法透過vSphere DRS進行自動化調度,僅能由管理人員手動觸發進行vMotion遷移作業。
實戰vSphere vMotion UDT傳輸機制
過去的vSphere版本不斷增強和提升vSphere vMotion線上遷移的能力,讓企業組織在需要遷移運作中的VM虛擬主機工作負載時,無論是遷移運算資源的vSphere vMotion,或是遷移儲存資源的vSphere Storage vMotion機制,都能以最快的速度完成線上遷移作業,避免VM虛擬主機中的營運服務產生任何卡頓甚至中斷的情況。
然而,有些管理人員可能發現,透過vSphere vMotion機制線上遷移運作中的VM虛擬主機時,確實能夠在最短時間內遷移完成,若是遷移「關閉」(Power Off)的VM虛擬主機,尤其是配置大容量儲存空間時,那麼遷移時間將需要很長時間,甚至同樣的遷移情境,將VM虛擬主機「開機」(Power On)後進行遷移,反而遷移時間縮短許多,為何會有這種遷移時間差異的情況出現?
主要原因在於,「線上遷移」(Hot Migration)的執行程序、I/O同步機制、傳輸效能,都與「離線遷移」(Cold Migration)不同所導致。舉例來說,VM虛擬主機運作中執行遷移時採用的Hot Migration,會採用最佳化後的「多執行緒」(Multi-Thread),與ESXi節點主機的多核心協同運作,傳輸效能最高可達80Gbps。
反觀VM虛擬主機關閉時執行遷移採用的Cold Migration,採用的則是「網路文件複製」(Network File Copy,NFC)通訊協定,並且僅採用「單執行緒」(Single-Thread),只使用ESXi節點主機的單顆核心進行運算,傳輸效能最高僅能到達1.3Gbps,如圖14所示。
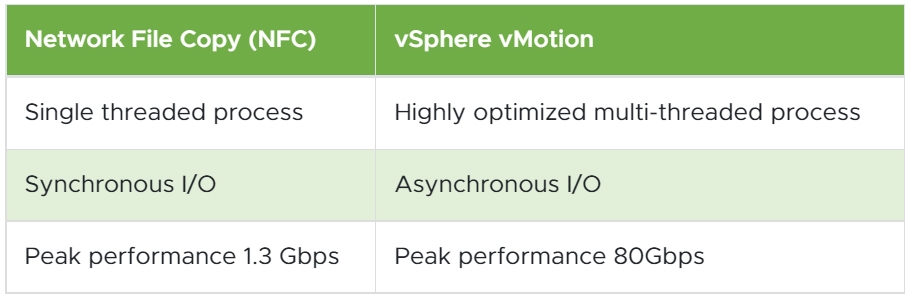 圖14 vSphere vMotion與NFC通訊協定和傳輸效能比較。 (表格來源:vSphere vMotion Unified Data Transport | VMware)
圖14 vSphere vMotion與NFC通訊協定和傳輸效能比較。 (表格來源:vSphere vMotion Unified Data Transport | VMware)

認識UDT傳輸機制
新版的vSphere 8採用「統一資料傳輸」(Unified Data Transport,UDT)機制,來處理Cold Migration遷移的VM虛擬主機傳輸作業。一旦VM虛擬主機關閉並且觸發Cold Migration遷移作業時,系統將會以原有的NFC通訊協定為「控制通道」(Control Channel),而「資料傳輸」(Data Transfer)部分則會改採vSphere vMotion通訊協定,以便提升傳輸效能和傳輸速度節省大量時間。
值得注意的是,有些管理人員會忽略ESXi節點主機的VMkernel Port組態設定,進而造成傳輸速度上異常緩慢,舉例來說,管理人員並未把ESXi節點主機的傳輸流量類型隔開,將Management和vMotion流量類型混用,而一般來說Management管理網路可能只有1Gbps的傳輸速度,因此執行Migration遷移作業時便導致傳輸效率不彰。
又或者是,已經將實體網路和ESXi節點主機的傳輸流量類型隔開,但是在組態設定上卻忽略VMkernel Port的部分,未將原有共用Management網路的vMotion取消勾選,造成Migration遷移作業時仍舊使用Management慢速網路進行傳輸,如圖15所示。
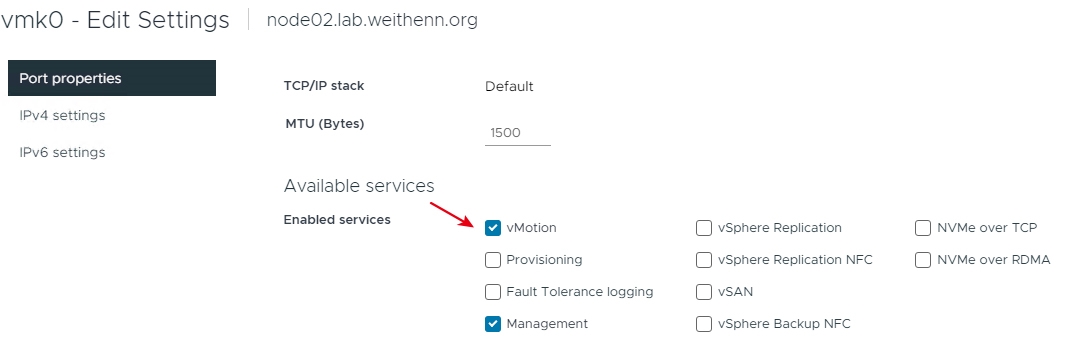 圖15 在Management慢速管理網路中啟用vMotion傳輸流量類型。
圖15 在Management慢速管理網路中啟用vMotion傳輸流量類型。
執行Migration遷移作業時,系統如何判斷使用的遷移網路?舉例來說,執行Hot Migration時會使用vMotion Network,而使用Cold Migration時則會使用Management Network,如圖16所示,管理人員也可以使用此方式確認組態設定和實體網路的規劃是否一致,確保Migration遷移作業執行時,網路傳輸能夠如同規劃般順利執行並快速傳輸完畢。
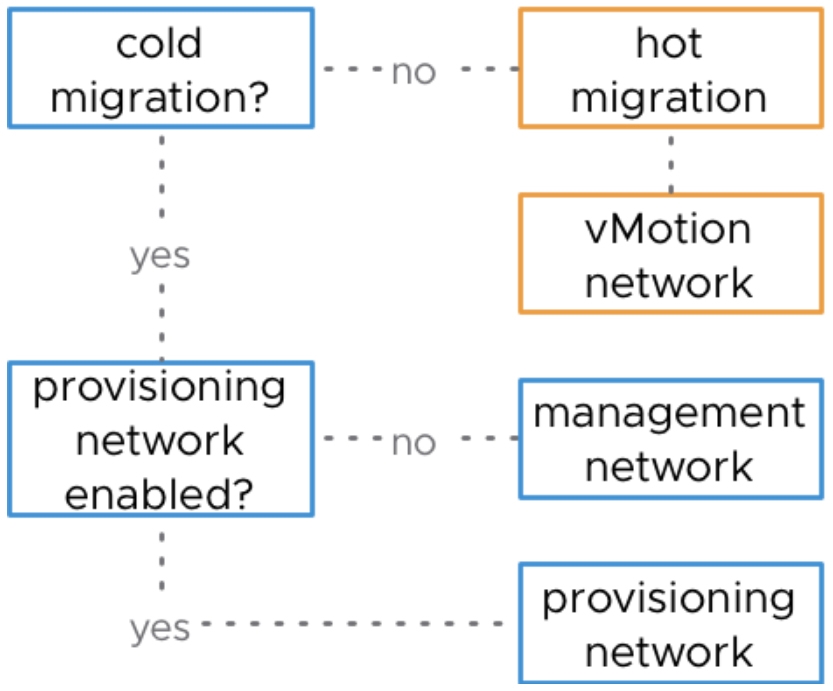 圖16 Hot Migration和Cold Migration使用傳輸網路流程圖。 (圖片來源:Hot and Cold Migrations; Which Network is Used? - VMware vSphere Blog)
圖16 Hot Migration和Cold Migration使用傳輸網路流程圖。 (圖片來源:Hot and Cold Migrations; Which Network is Used? - VMware vSphere Blog)
採用傳統NFC的Cold Migration
在實戰演練部分中,採用最新的vSphere 8 IA版本,搭配最新的vCenter Server 8.0(Build 20519528)管理平台,而在UDT傳輸測試流程的VM虛擬主機,則是配置2 vCPU、8GB vRAM以及50GB Thick Provision Eager Zeroed類型的虛擬硬碟,如圖17所示。
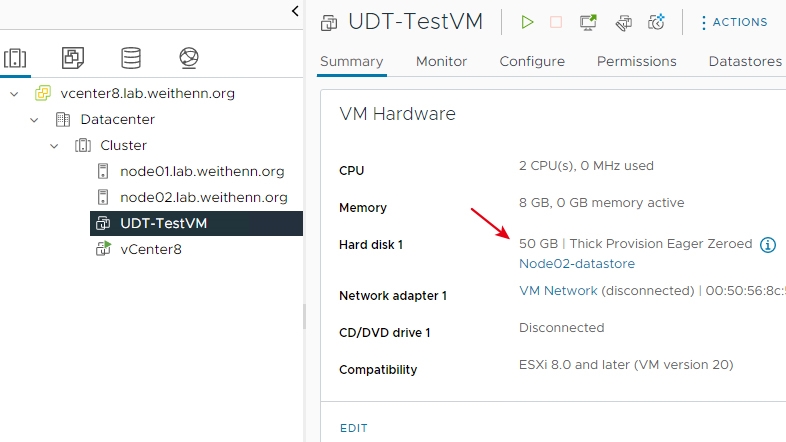 圖17 測試新式UDT傳輸機制的VM虛擬主機配置。
圖17 測試新式UDT傳輸機制的VM虛擬主機配置。
首先,在此實作中率先測試使用傳統NFC通訊協定進行Cold Migration,針對這樣的VM虛擬主機配置將其關機後進行遷移,觀察將會花費多少傳輸時間。
目前測試的「UDT-TestVM」虛擬主機運作於Node02節點主機上,在vCenter管理介面中,依序點選「UDT-TestVM > Actions > Migrate」。在彈出的Migration互動視窗中選擇「Change both compute resource and storage」選項,然後按下〔Next〕按鈕繼續Cold Migration流程,如圖18所示。
 圖18 針對關機中的VM虛擬主機,執行Cold Migration遷移作業。
圖18 針對關機中的VM虛擬主機,執行Cold Migration遷移作業。
在2. Select a compute resource頁面中,選擇將UDT-TestVM虛擬主機運算資源遷移至虛擬化基礎架構中哪一台ESXi主機,在本次實作選擇「node01.lab.weithenn.org」,並確認下方相容性檢查結果為「Compatibility checks succeeded.」,然後按下〔Next〕按鈕。
在3. Select storage頁面中,選擇要將UDT-TestVM虛擬主機儲存資源遷移至虛擬化基礎架構中哪一個Datastore中,在本文實作環境中選擇「Node01-datastore」,此時在下方相容性檢查結果將會警告管理人員「This can lead to lower network copy throughput.」,目前的傳輸網路吞吐量不佳的警告訊息,但是仍然能夠按下〔Next〕按鈕繼續遷移流程。
在4. Select networks頁面中,選擇UDT-TestVM虛擬主機虛擬網路,是否要連接至不同的vSwitch虛擬網路交換器或Port Group連接埠群組,在本文實作環境中採用預設值即可。最後,在5. Ready to complete頁面中,確認相關資訊無誤後按下〔Finish〕按鈕,便立即執行NFC通訊協定的Cold Migration遷移作業。
此時,可以在vCenter管理介面下方Recent Tasks區塊中看到Cold Migration遷移作業的執行進度,或是切換到「Cluster > Monitor > Tasks and Events > Tasks」,查看更詳細的Cold Migration遷移作業內容,從結果中可以看到此次採用傳統NFC通訊協定的遷移作業花費「6分12秒」,如圖19所示。
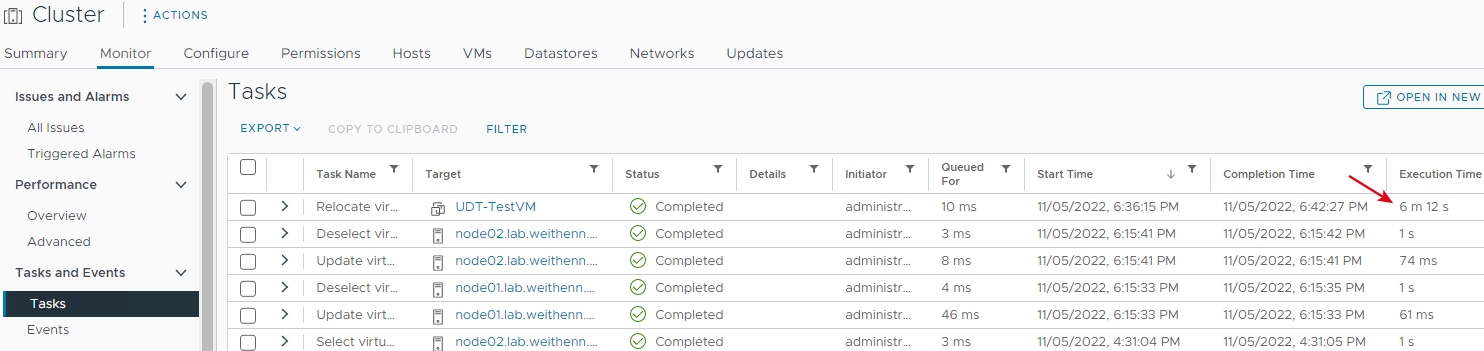 圖19 採用傳統NFC通訊協定執行Cold Migration遷移作業所花費的時間。
圖19 採用傳統NFC通訊協定執行Cold Migration遷移作業所花費的時間。
使用新式UDT的Cold Migration
在使用新式UDT機制進行Cold Migration遷移之前,必須先為來源端和目的端的ESXi節點主機,針對VMkernel Port進行組態設定,才能確保稍後使用Cold Migration遷移作業時使用新式的UDT機制,而非傳統的NFC通訊協定進行資料傳輸。
在vCenter管理介面中,依序點選「ESXi Host > Configure > Networking > VMkernel adapters > Edit」,在VMkernel Port組態設定視窗中,勾選「Provisioning」項目後按下〔OK〕按鈕,如圖20所示。
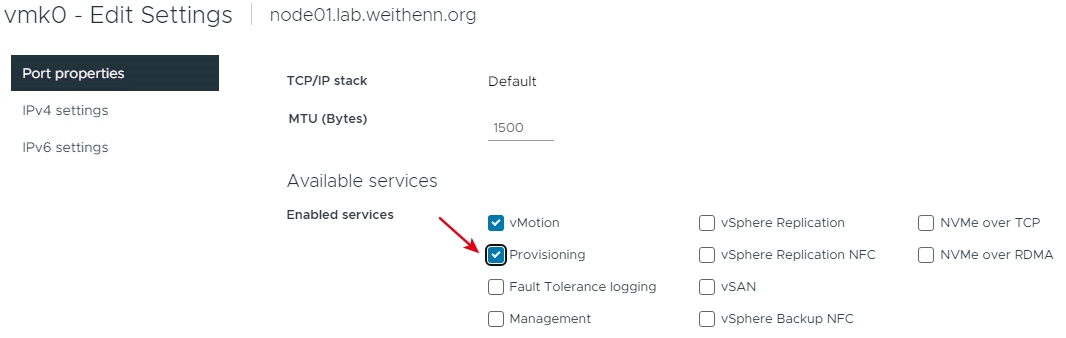 圖20 在VMkernel Port組態設定視窗中勾選Provisioning項目。
圖20 在VMkernel Port組態設定視窗中勾選Provisioning項目。
確保來源端和目的端的ESXi節點主機,都已經為遷移網路的VMkernel Port啟用「Provisioning」類型後,同樣的遷移情境,此時的UDT-TestVM虛擬主機將從剛才的Node01遷移回Node02,並觀察遷移作業時間與剛才傳統的NFC通訊協定有何不同。
在vCenter管理介面中,依序點選「UDT-TestVM > Actions > Migrate」,在彈出的Migration互動視窗中選擇「Change both compute resource and storage」選項,然後按下〔Next〕按鈕。在2. Select a compute resource頁面中,選擇要將UDT-TestVM虛擬主機運算資源,遷移至虛擬化基礎架構中哪一台ESXi主機,在本文實作環境中選擇「node02.lab.weithenn.org」,並確認下方相容性檢查結果,若正確無誤便按下〔Next〕按鈕。
在3. Select storage頁面中,選擇要將UDT-TestVM虛擬主機儲存資源,遷移至虛擬化基礎架構中哪一個Datastore中,在本文實作環境中選擇「Node02-datastore」,此時在下方相容性檢查結果,並不會像剛才實作NFC通訊協定時產生警告訊息,而是通過相容性檢查的「Compatibility checks succeeded.」訊息,如圖21所示,按下〔Next〕按鈕繼續遷移流程。
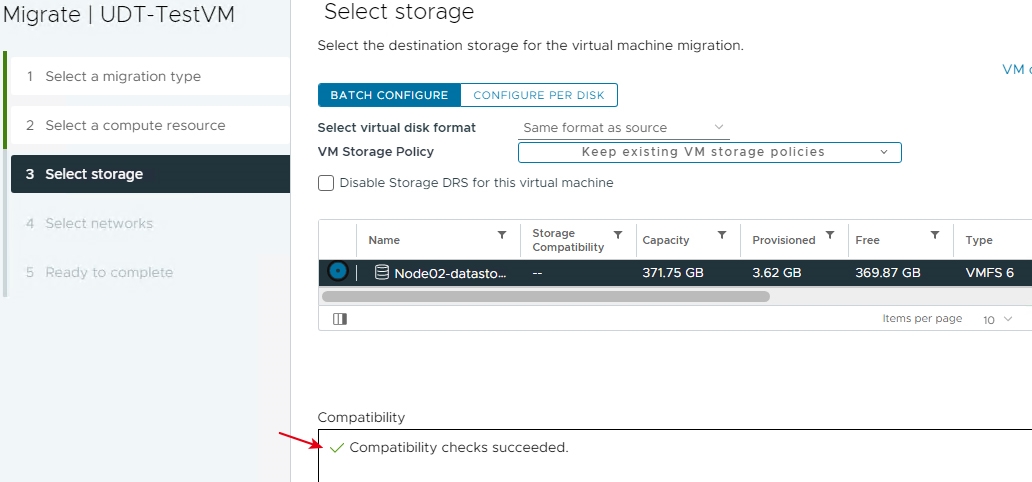 圖21 選擇儲存資源時順利通過系統相容性檢查作業。
圖21 選擇儲存資源時順利通過系統相容性檢查作業。
在4. Select networks頁面中,選擇UDT-TestVM虛擬主機虛擬網路,是否要連接至不同的vSwitch虛擬網路交換器或Port Group連接埠群組,在本文實作環境中採用預設值即可。
最後,在5. Ready to complete頁面中,確認相關資訊無誤後按下〔Finish〕按鈕,便立即執行採用新式UDT機制的Cold Migration遷移作業。
同樣地,在vCenter管理介面下方Recent Tasks區塊,看到Cold Migration遷移作業的執行進度,或是切換到「Cluster > Monitor > Tasks and Events > Tasks」,查看更詳細的Cold Migration遷移作業內容,從結果中可以看到改採新式UDT機制的遷移作業僅花費「39秒」便遷移完成,如圖22所示。
 圖22 改採新式UDT機制的遷移作業僅花費39秒便遷移完成。
圖22 改採新式UDT機制的遷移作業僅花費39秒便遷移完成。
結語
透過本文的深入剖析和實作演練後,相信管理人員對於最新vSphere 8的亮眼特色功能,已經有更深一層的認識和理解。
同時,在實作演練部分中,本文也實作了最新vSphere 8中支援的新式UDT機制,讓關機中卻有遷移需求的VM虛擬主機,同樣達到快速遷移的目的,有效縮短資料傳輸時間。
<本文作者:王偉任,Microsoft MVP及VMware vExpert。早期主要研究Linux/FreeBSD各項整合應用,目前則專注於Microsoft及VMware虛擬化技術及混合雲運作架構,部落格weithenn.org。>