調研機構Gartner也認為,資料湖倉整合並統一了資料倉儲和資料湖的功能,其主要目標即是在單一平台上支援人工智慧、商業智慧、機器學習和資料工程。
從歷史演進看資料架構變革
資料分析需求由來已久,1852年流行病學家John Snow便運用資料分析來找出霍亂疫情的源頭。在近期的資訊時代,資料倉儲便是設計來實現與支援商業智慧(BI)的一種架構,不過,早期資料倉儲所連結與統整資料,主要還是以結構化資料為主,隨著大數據(Big Data)崛起,面對資料量(Volume)、資料類型(Variety)或是資料傳輸速度(Velocity)急劇增長,傳統資料倉儲架構已無法因應大數據的使用需求,而後便發展出資料湖來加以因應。
AWS台灣暨香港專業架構師團隊總監楊仲豪解釋,從資料倉儲、資料湖、資料中台乃至於資料湖倉,其實就是一連串的演化過程,「因為大數據崛起,才有資料湖的出現。而資料湖的概念就是讓大家都把所有資料先收集起來,之後才進行分析。」他提到,起初也只是從檔案開始收集,後來發現資料收集的樣態實在太多樣化,而後才發展出物件儲存,此後包含影像、聲音都可以存放在物件儲存中。
 Data Lakehouse想要實現的是在不同的資料服務中快速協作。(資料來源:AWS)
Data Lakehouse想要實現的是在不同的資料服務中快速協作。(資料來源:AWS)
然而,資料湖仍有不足之處。例如民眾到銀行提款時,資料庫會記錄是哪一台ATM、什麼時間點、所在位置、提了多少金額等等交易資料,這些資料會存放在資料庫內,同樣也會存放在資料湖中,問題在於,進行大數據分析時,並不會分析列資料(Row Data),而是以台北市、新北市等區域為主,換言之,Row–based的資料就必須透過擷取、轉換和載入(ETL)轉換成Column-based資料才能加以分析。不只如此,企業可能還有來自於第三方供應商、商圈以及人流資料要引進,於是便又發展出資料中台。
資料中台是一種概念,通常是用來描述一個整合化、統一的資料架構,目的是為了打破資料隔閡,讓企業內部所有業務的資料都能被收集、管理與應用,以實現更好的資料可用性、品質以及價值,從而支援資料驅動的決策與業務創新。
他提到,資料湖想要解決的是多元型態的資料(Multi-type Data)、結構與非結構化資料以及資料的耐用性問題。但是因為要存放大量的資料,因此資料湖的特性就是要有耐用性以及便宜的成本,在這樣的條件下,就不會是高吞吐量的設計。然而如前所述,進行大數據分析時,須要將資料從Row-based轉換成Column-based,而這個過程其實需要運算力,資料中台可以在大數據分析中運用分散式運算來創造資料價值。
打造輕鬆移動資料的能力
進入到人工智慧(AI)與機器學習(ML)蓬勃發展的時代後,各個業務單位紛紛希望運用機器學習來尋求更好的競爭力,然而不管是資料庫還是資料倉儲,想要支援機器學習都相對不容易,從架構、想法到開發工具都不盡相同。而且,隨著資料型態更為多元,機器學習還會衍生到圖形分析,例如鑑識溯源,以及詐欺與時間軸等應用都是常見的圖形分析應用,尤其是時間軸的應用後還會有很多日誌的分析需求,甚至未來還會有其他新型態的發展,例如生成式AI已發展到多模態,在種種驅動因素之下,Data Lakehouse於焉產生。
他提到,資料湖倉想要實現的是在不同的資料服務中快速協作,更強調Inside Out以及Outside In。這個資料架構同樣以Data Lake為中心,周邊圍繞的是一系列的專用資料服務以及彼此之間能夠輕鬆移動所需資料的能力。由於其能夠支援更廣泛的資料管理策略,讓使用者可以根據應用程式在各種架構和模型之間進行選擇。在分析與進階AI應用時,也可以直接從資料湖運行,而不是在資料倉儲中重新制定資訊副本。此外,也能保有資料倉儲提供的不可分割性、一致性、獨立性和耐久性(ACID),確保資料的品質。
資料湖倉的五個邏輯層
從AWS角度來看,Data Lakehouse架構有五個邏輯層的堆疊,而每個邏輯層都由多個滿足特定需求的專用元件組成。在資料來源層(Data Sources)方面,資料湖倉能擷取與分析來自於OLTP、ERP、CRM、LOB等應用程式的結構化批次資料,也能收集來自於Web應用程式、行動裝置、感測器、視訊串流與社群媒體的資料。而資料擷取層(Data Ingestion Layer)提供的是透過各種協定,提供連結能力內部資料與外部資料來源的能力,它能將擷取而來的大量批次以及串流資料傳送到資料倉儲以及資料湖的元件中。
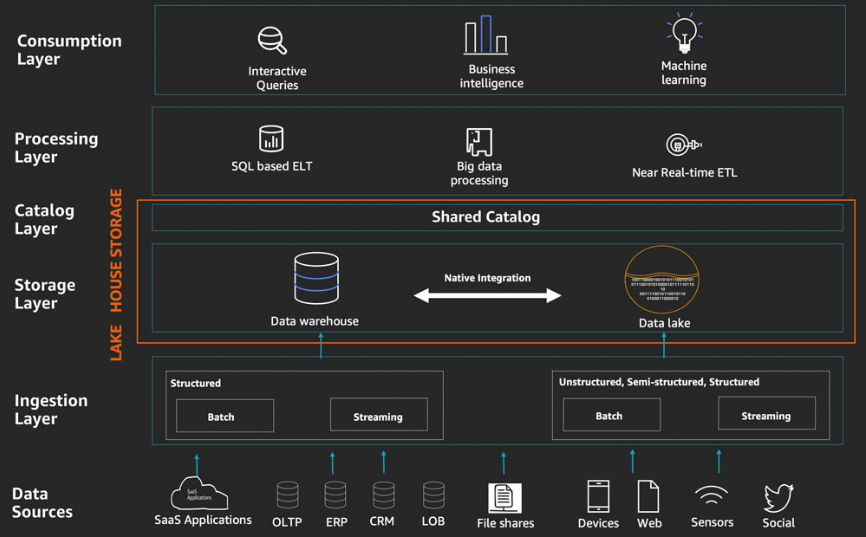 Data Lakehouse架構有五個邏輯層的堆疊。(資料來源:AWS)
Data Lakehouse架構有五個邏輯層的堆疊。(資料來源:AWS)
資料儲存層(Data Storage Layer)則包含已原生整合的資料倉儲和資料湖元件,為了提供一致且可信任的資料,資料在存放到資料倉儲前,需要透過ETL來對資料進行大量的預處理、驗證以及轉換。由於資料倉儲和資料湖已高度整合,從資料倉儲中卸載大量的冷資料也能改存放到資料湖中,以降低儲存成本。
目錄層(Catalog Layer)則負責儲存Meta Data,這一層是由資料倉儲以及資料湖共用。須留意的是,Data Lakehouse的儲存涵蓋了資料儲存層以及目錄層。
最後是資料處理層(Data Processing Layer)以及資料使用層(Data Consumption Layer),資料處理層負責執行各種轉換,其可以存取資料湖倉的所有資料以及元資料(Meta Data),好處是減少不必要的資料遷移。透過資料驗證、清理、標準化、轉換和富集(Enrichment)將資料轉換為可使用狀態。而資料使用層,則能支援各式的分析方法,包含BI分析、機器學習以及互動式SQL查詢等等。
楊仲豪指出,在每一個邏輯層中,都有多款對應的AWS方案,就以資料湖來說,S3 Express One Zone是目前AWS提供最低延遲的物件儲存類別,與標準的S3相比,資料存取速度可快上10倍。
而下一個演化則是Translational Data Lake,去年AWS便已支援開源資料湖的儲存框架,如Apache Hudi、Iceberg。這可為資料湖加上轉換的能力,讓分析使用者可從多個來源輕鬆探索、準備、移動和整合資料。「現在我們又開始往下延伸,進入到Zero ETL,目的是降低各種不同的資料管道的建置與維護負擔。以便能更快速輕鬆地連接所有數據,獲得更好、更快的洞察。」他說。