人工智慧的熱潮持續延燒,AI PC新機與邊緣AI裝置齊發,在在都反映出AI無所不在的時代即將來臨。然而,成功的AI策略,最為關鍵的核心還是資料,如何釋放散落在各地、舊有系統,以及雲原生的應用系統環境中的資料潛力,是現今多數企業面臨的挑戰。 台灣戴爾科技集團技術副總經理李百飛指出,資料湖倉(Data Lakehouse)雖然才剛在台灣起步,但在國外討論已非常熱烈,原因即是要同時管理維護資料倉儲(Data Warehouse)與資料湖(Data Lake)架構並不容易,也漸漸無法因應AI時代下的應用需求,這才催生出新的現代化資料架構平台。「當一門技術發展到一體機解決方案時,代表著其火紅的程度,Dell研發設計的Data Lakehouse專用設備,也是基於實際需求而生。這款方案已將軟、硬體整合,同時結合資料分析引擎(Dell Data Analytics Engine,DDAE),可橫跨多個資料系統處理包含開放的檔案格式以及Table格式資料。」
Two-tier現代化改造仍有不足
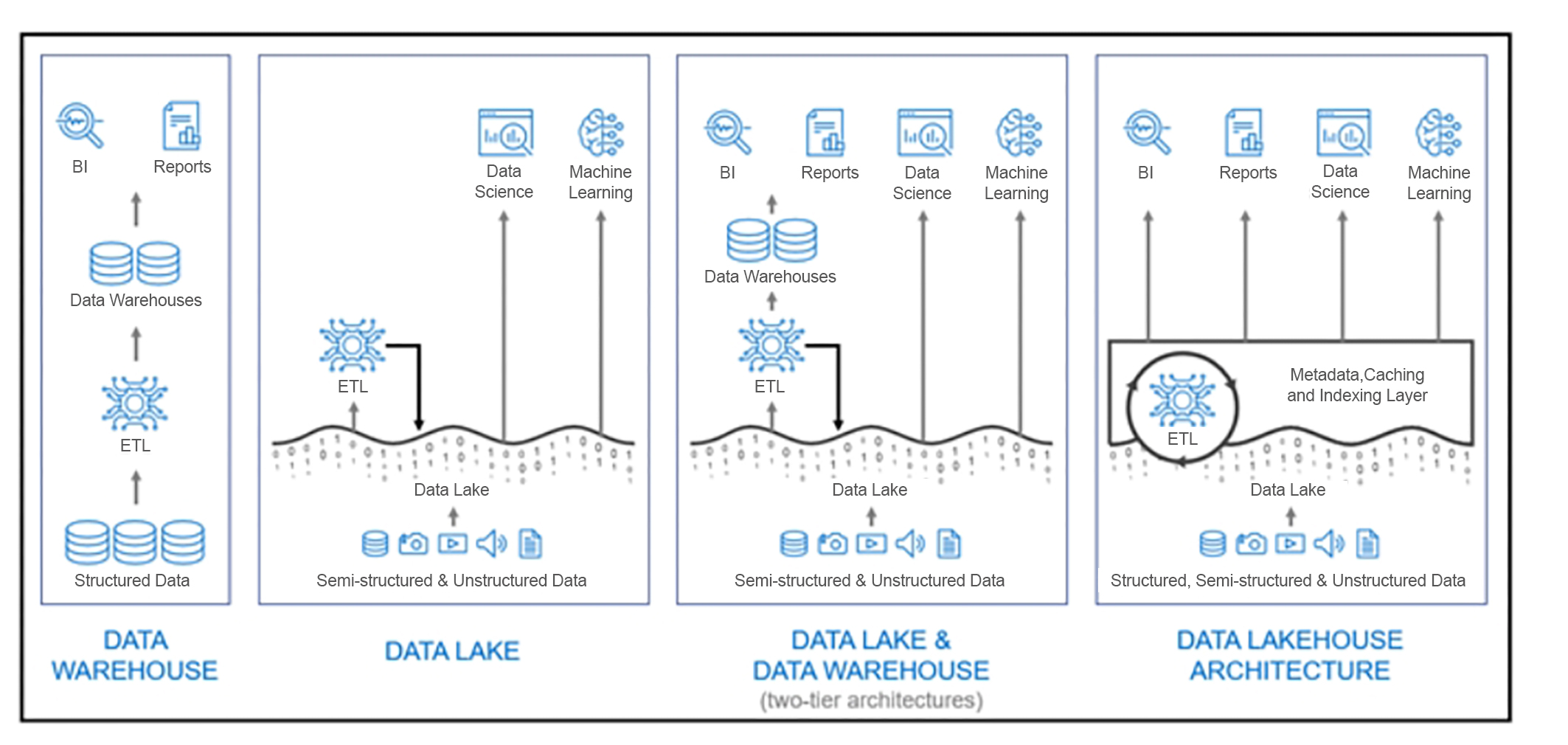
傳統上,資料倉儲是一種關聯式資料庫管理系統(RDBMS),可連結與統整許多不同的資料庫,透過擷取、轉換和載入(ETL),把多個來源的資料合併到資料倉儲裡,因此多半以結構化資料為主,使用者可以將這些高品質的結構化資料拿來進行商業智慧(BI)分析或是產出報表。而資料湖則可以收集包含結構化、半結構化以及非結構化資料,由於儲存的成本較低,更適合用來存放大量資料,常見與機器學習以及大數據分析搭配使用。
 針對分析的資料儲存方法論。(資料來源:Dell)
針對分析的資料儲存方法論。(資料來源:Dell)
他解釋,一開始資料倉儲與資料湖是兩個獨立的架構,但隨著企業的資料環境日益複雜,資料型態更為多樣化,不少企業內部會以資料倉儲加上資料湖這種Two-tier架構來因應資料分析的需求,以便同時為BI以及資料科學提供服務。
這種現代化改造的好處是,企業既可以繼續使用資料倉儲技術,同時也能保持儲存的靈活性和可擴展性。而且資料湖也可以作為資料倉儲的資料來源,資料科學家可以擷取資料湖上的資料,透過ETL流程把資料轉換並匯整到資料倉儲中,以進一步分析。不過,由於資料是從資料庫移動到資料湖,再從資料湖透過ETL Pipeline進到資料倉儲,可想而知,這種策略會導致可靠性降低,並且可能會出現較舊的資料。
「Data Lakehouse概念的出現就是為了改善既有資料架構的不足,」李百飛指出,資料湖倉的作法是在Lakehouse架構中整合SQL查詢引擎,如此就可以把結構化、半結構化以及非結構化資料當中有固定欄位的部分對應起來。亦即在資料湖上設置一層虛擬層,在這個虛擬層中提供SQL查詢語法以及Table欄位,透過這一層,所有的BI工具就可以存取資料湖裡面的資料,甚至產出報表。而資料科學家取用或是進行機器學習時,可以直接存取資料湖的資料,或是從虛擬層中下達SQL語法來擷取結構化資料。
「從資料收集的角度來看,讓各式各樣的資料直接存放進資料湖是最快的作法,而且也會更符合成本效益,反之,如果把所有的原始資料都儲存到資料倉儲,企業可能必須要支付更高昂的投資成本,而且,儲存容量若是一下子擴充太大,資料倉儲也會處理不來。」他繼續說明,但是資料湖並沒有Schema的概念,因此,需要有虛擬層去模擬資料庫,甚至做到資料庫的工作,如此一來,企業就無須再建置資料倉儲系統,「唯一的缺點是,資料湖倉不能用於線上交易處理(OLTP),只能用來分析。而好處是,由於是虛擬層去模擬資料庫,所以欄位數並沒有限制,即使是超過一萬個欄位也可以輕鬆應對。」
攜手Starburst Data 實現快速分析查詢
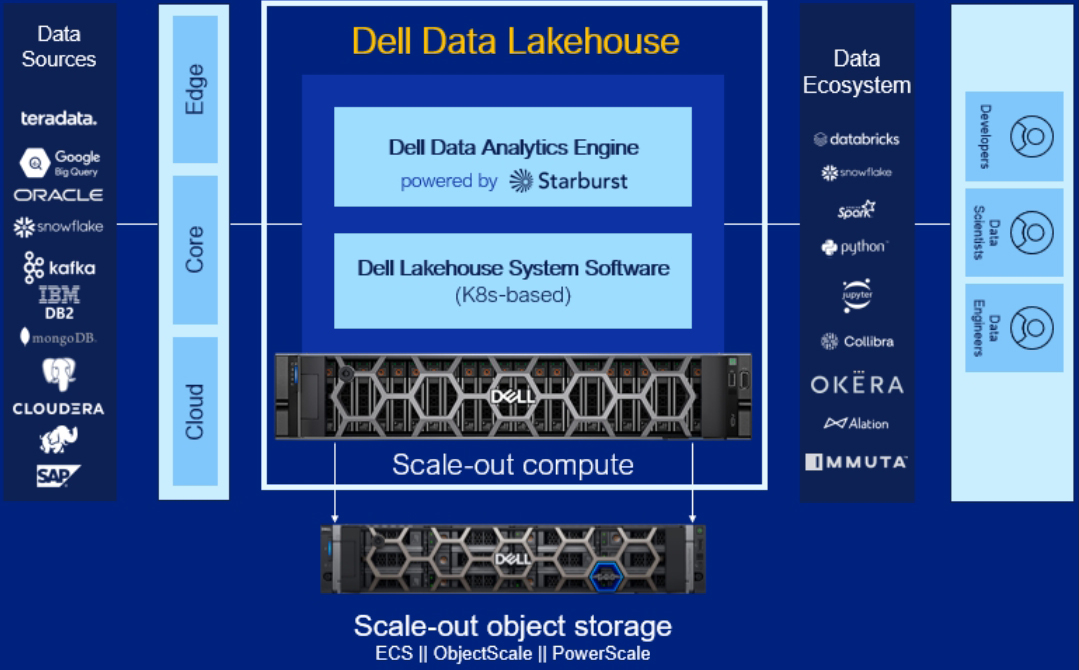
簡單地說,資料湖倉提供了高效能引擎來協助企業存取與探索資料,而且可以就地探索,資料的使用者也能很輕易地存取與連接到各種資料來源。為了實現此一目標,Dell在Data Lakehouse方案中納入了由Starburst提供支援的資料分析引擎(DDAE)、Data Lakehouse系統軟體、可橫向擴充的伺服器與物件儲存等幾個元件。
李百飛解釋,Starburst提供支援的資料分析引擎以及相關的生命週期管理軟體,都已經封裝在Dell提供的可橫向擴充的伺服器,在物件儲存方面,則有ECS、ObjectScale以及PowerScale等三款儲存方案可供選擇。比較特別的是,Data Lakehouse系統軟體,這是Dell Data Lakehouse的中樞神經系統,其簡化了生命週期管理,可透過預先建置的自動化和整合用戶管理降低IT 營運支出。Data Lakehouse系統軟體本身是容器技術建構,因此也會有容器管理平台。
 Dell Data Lakehouse核心功能。(資料來源:Dell)
Dell Data Lakehouse核心功能。(資料來源:Dell)
另外,由Starburst提供支援的資料分析引擎目前也已支援許多開放格式,例如Parquet、Avro以及ORC 等等開源檔案格式。像是可透過物件儲存提供高效能ACID資料表儲存(Table Storage)的Delta Lake、專為PB等級的Table設計的Apache Iceberg,以及資料處理引擎Apache Spark等,目前也都有支援。
他提到,Starburst是開放原始碼分散式SQL查詢引擎Trino的商業版本,而Trino即是以執行快速分析查詢而聞名,因此使用上會更為快速。「資料湖倉非常適合AI與機器學習應用場景,」一般來說,AI分析的結果若要準確,就要做好資料分類,如果資料分散在不同檔案夾裡面,而且又摻雜著不同的照片,最終將會影響到辨識的成果。Data Lakehouse解決的方法是事先運用SQL的語法來把想要的照片挑出來給AI進行訓練,不用將這些資料全部都集中存放在某個資料夾中,只要讓AI演算法看到這些檔案,而且是更精準地告訴AI資料位於哪一個資料集群即可,如此,資料就更容易被存取以及交叉運用。
他最後強調,Data Lakehouse的優勢是可以突破過去資料倉儲的技術,卻又提供與原本資料倉儲一樣的能力,甚至提供更好支援的方法,而且又能降低成本。因為能夠快速取得資料加速決策,因此更能降低風險。