本篇文章將探討目前業界在AI風險評估方面所做的努力。雖然目前已經有一些不錯的研究成果,但人們卻仍忽略了應該將因果關係與攻擊情境做連結的重要環節。
本文將探討目前業界在AI風險評估方面所做的努力。雖然目前已經有一些不錯的研究成果,但人們卻仍忽略了應該將因果關係與攻擊情境做連結的重要環節。
有誰在做些什麼?
在資安界,不同領域對不受控AI有著不同的觀點:
‧OWASP聚焦在漏洞與防範,發表了大型語言模型(LLM)應用程式10大漏洞(Top 10 for LLM Applications)報告,並在LLM AI網路資安與治理檢核表(LLM AI Cybersecurity and Governance Checklist)中提供一些高階指引。
‧MITRE專門研究駭客的攻擊手法與技巧,藉由ATLAS矩陣將MITRE ATT&CK框架延伸至AI系統。
‧MIT最新發表的AI風險資料庫(AI Risk Repository)提供一個包含700多種AI風險的線上資料庫,並依據原因和風險領域來分類。
接下來,就讓我們逐一檢視。
OWASP
不受控AI和OWASP提出的10大LLM風險幾乎每一項都有關,除了「第10項:竊取模型」(LLM10:Model Theft)之外,也就是「在未經授權的情況下存取、複製或外傳專屬LLM模型」。此外,「脫離正軌」的行為也不算是漏洞,也就是當AI遭到入侵或出現意外行為的情況。所謂的「脫離正軌」:
‧可能的原因包括:提示注入、模型下毒、供應鏈、不安全的輸出,或是不安全的擴充元件。
‧如果在10大漏洞的「第9項:過度依賴」(LLM09:Overreliance)的情況下,可能會有更大的影響。
‧可能導致「阻斷服務」(Denial of Service,LLM04)、「敏感資訊外洩」(Sensitive Information Disclosure,LLM06)和∕或「過多的代理權限」(Excessive Agency,LLM08)。
其中,「過多的代理權限」尤其危險,這是指LLM「採取了一些行動而導致意外的後果」,並擁有過多的功能、權限或自主性。這一點可以透過確保系統與功能的適當存取,並利用「人機循環」(Human-in-the-loop)來加以防範。
OWASP的10大漏洞在防範不受控AI上提出了不錯的建議(後面會再提到),但卻沒有顧慮到因果關係:「也就是攻擊是否蓄意」。
他們的資安與治理檢核表也提供一份方便的行動清單,確保LLM在各種風險情境下都能安全導入。它將「影子AI」(Shadow AI)列為許多企業機構最迫切的非駭客LLM威脅。然而,壞蛋總是躲在暗處偷偷壯大,所以缺乏治理的AI已經超出政策所允許的AI用途。假使無法掌握影子AI系統的可視性,那就無法知道他們是否已經變壞。
MITRE ATLAS
MITRE的手法、技巧與程序(TTP)框架是任何網路威脅情報人員的首要參考資源,有助於將許多攻擊程序中的步驟分析標準化,讓研究人員更容易發現某些攻擊行動。儘管ATLAS將ATT&CK框架延伸至AI系統,但它無法直接解決不受控AI的問題。不過,「提示注入」、「越獄」和「模型下毒」等可用來破壞AI系統進而產生不受控AI的手法都已經列入了ATLAS TTP當中。
事實上,這些遭到破壞的AI系統本身就是TTP:代理式AI系統可執行任何ATT&CK手法與技巧(如偵查、資源開發、突破防線、存取機器學習模型、執行)來造成破壞。所幸,目前只有高明的駭客才有辦法破解AI系統來達成其特定目的。不過,光知道他們已經在試圖進入這類系統,就足以令人擔心。
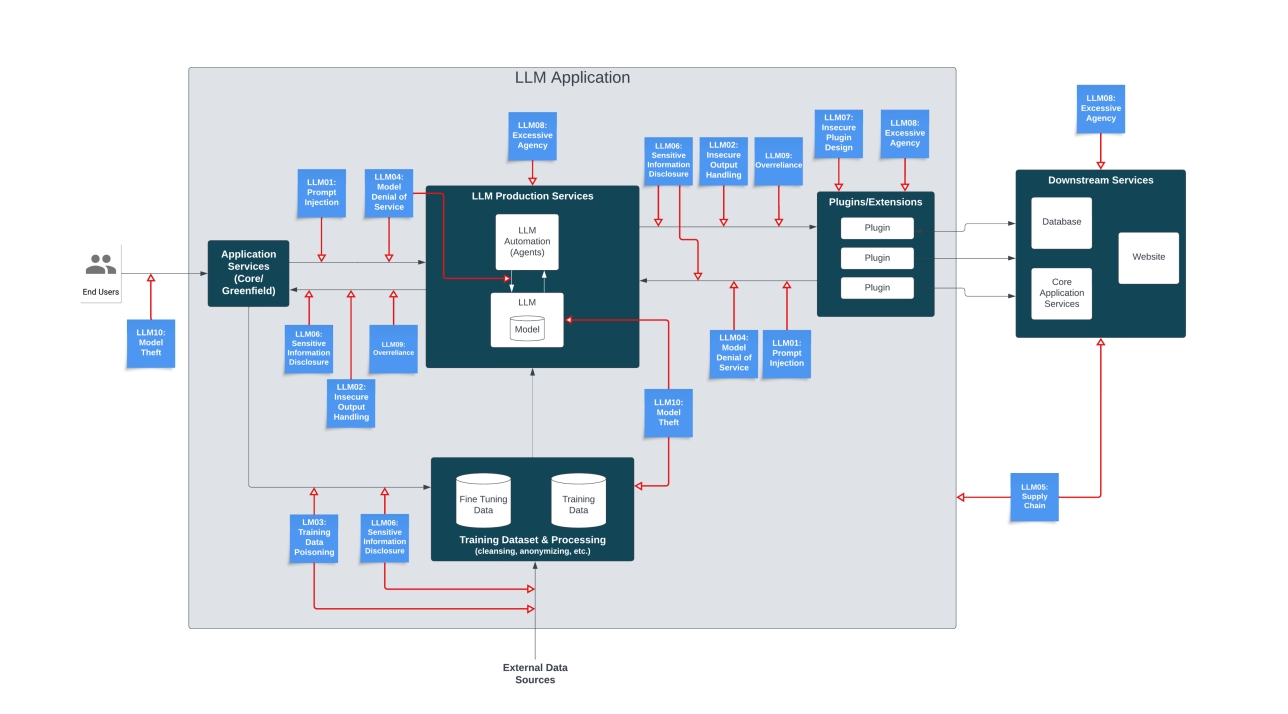 大型語言模型(LLM)應用程式資料流示意圖。(資料來源:OWASP)
大型語言模型(LLM)應用程式資料流示意圖。(資料來源:OWASP)
儘管MITRE ATLAS和ATT&CK已經涵蓋了遭人破壞的AI,但卻還未涵蓋天生惡意AI。目前並無駭客在目標環境安裝惡意AI系統的例子,儘管這只是時間早晚的問題:隨著企業開始採用代理式AI,駭客也會開始這麼做。以這樣的方式將AI用於攻擊,本身就是一種技巧。從遠端部署AI,就好像把AI當成惡意程式一樣,不過當然不只是這樣。而使用內含AI服務的代理機器人來發動攻擊,就如同使用AI殭屍網路一樣,但同樣也不只這樣。
MIT AI風險資料庫
最後,還有MIT的風險資料庫,這是一個內含數百種AI風險的線上資料庫,還有一份詳細介紹該主題最新文獻的主題地圖。該資料庫廣泛收錄業界對AI風險的各種觀點,可說是一項非常珍貴的資源,其收錄的風險有助於更全面的分析。很重要的是,它談到了因果關係的議題,包含三個主要層面:
‧誰是問題發生的原因(人、AI、不明)
‧如何發生在AI系統中(意外或蓄意)
‧何時發生(之前、之後、不明)
「意圖」對於了解不受控AI尤其重要,儘管它只有在OWASP資安與治理檢核表的中提到。意外的風險通常來自於某項弱點,而非MITRE ATLAS攻擊技巧或OWASP漏洞。
此外,「風險是誰所造成」也有助於分析不受控AI的威脅。人類和AI系統都可能不小心導致不受控AI的產生,但天生惡意的AI則原本就是設計用來攻擊。天生惡意的AI理論上也可能試圖破壞現有的AI系統來使它變壞,或者設計用來製造自己的「後代」,儘管目前認為人類才是蓄意不受控AI的元凶。
了解風險的發生時機,是任何威脅研究人員的基本條件,他們應該對AI系統生命週期所有環節的狀況都瞭若指掌。換句話說,在部署前和部署後,都要對系統進行評估並檢查是否有脫離正軌的現象,以便揪出天生惡意、遭人破壞或意外變壞的AI。
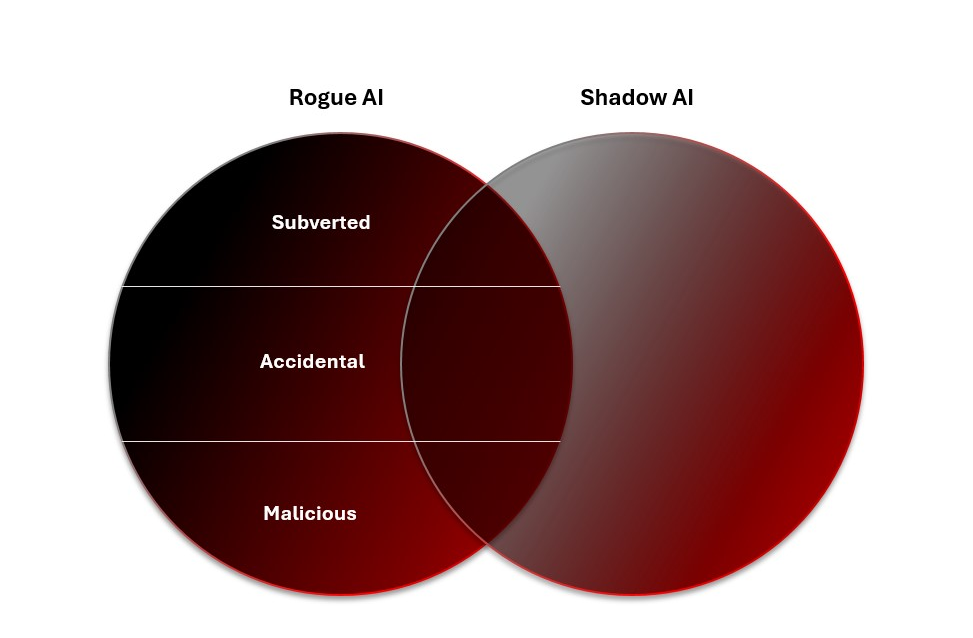 不受控管的AI(Rogue AI)與影子AI(Shadow AI)。
不受控管的AI(Rogue AI)與影子AI(Shadow AI)。
MIT將風險分成7個關鍵群組和23個子群組,其中不受控AI直接歸類在「AI系統安全、故障與限制」(System Safety, Failures and Limitations)領域。其定義如下:
「與道德標準或人類的目標或價值觀(尤其是設計者或使用者的目標)相衝突的AI系統。這些衝突的行為有可能是人類在設計與開發過程中所造成,例如獎勵駭客(Reward Hacking)與目標不當泛化(Goal Mis-generalization),可能導致AI運用一些危險的能力(如操弄、欺騙或當下狀況)來追求力量、自我擴散,或達成其他目的。」
透過因果關係與風險情境來達成縱深防禦
基本上,採用AI系統會增加企業的攻擊面,而且可能是大幅度增加。企業必須更新其風險模型來將不受控AI的威脅列入考量。此時,「意圖」將會是關鍵:意外變壞的AI在很多情況下都會造成傷害,而且不牽涉到駭客。但如果傷害是蓄意的,那麼誰正在使用什麼資源來攻擊誰,就是非常需要了解的情況。到底是駭客,還是天生惡意的AI正在攻擊你的AI系統來讓它變壞?他們是否正在攻擊你的整個企業?還有,他們使用的是你的資源、他們自己的資源,或是某個已遭破壞的AI代理。
這些全部都是企業所面臨的風險,不論部署前或部署後。儘管資安界已經有些不錯的研究來改善這類威脅的分析,但在不受控AI方面所缺乏的,是一套同時將因果關係與攻擊情境納入考量的方法。只要解決了這點,就能開始做好萬全準備,並徹底防範不受控AI的風險。
<本文作者:Trend Micro Research 趨勢科技威脅研究中心本文出自趨勢科技資安部落格,是由趨勢科技資安威脅研究員、研發人員及資安專家全年無休協力合作,發掘消費者及商業經營所面臨層出不窮的資安威脅,進行研究分析、分享觀點並提出建議。>