本文將說明如何打造一個專屬於Amazon Braket的客製化程式碼助理,透過生成式AI加速量子程式開發。這款Braket程式碼助理整合於Amazon Braket的notebook執行個體中的JupyterLab整合開發環境,並透過Amazon Bedrock提供的各種大型語言模型驅動而成,為使用者打造對話介面。
隨著生成式人工智慧(AI)的應用日漸普及,從剛起步的開源貢獻者,到經驗豐富的企業軟體工程師,開發者正逐漸依賴生成式AI助理來自動化重複性工作,並將開發週期縮短最多30%。
本文將說明如何打造一個專屬於Amazon Braket的客製化程式碼助理,透過生成式AI加速量子程式開發。這款Braket程式碼助理整合於Amazon Braket的notebook執行個體中的JupyterLab整合開發環境(IDE),並透過Amazon Bedrock提供的各種大型語言模型(LLM)驅動而成,為使用者打造對話介面。
這項助理工具不僅適合初學者,也能支援進階開發者進行量子運算工作負載的建構。使用者能透過對話介面提問各種量子運算的相關問題,例如:「請撰寫一段Python程式碼,建立n個量子位元的GHZ電路」,或「將一個隨機量子電路提交至SV1模擬器、本地模擬器與IQM Garnet設備,並比較量測結果」。助理便會在數秒內提供完整的程式碼範例,並附上詳細註解。
透過檢索增強生成(RAG)自訂LLM
市面上許多開箱即用的生成式AI工具在處理Python或Java等主流程式語言時,已展現出高度實用性。然而,當應用於新興的程式語言或專用軟體函式庫時,往往需要進一步的模型客製化。針對量子程式設計進行LLM客製化,往往是一項極具挑戰的任務,原因在於該領域橫跨多個專業學門,不僅涉及量子電路、演算法與硬體平台的概念,也涵蓋資料結構與軟體開發工具包(SDK)等技術知識。目前,量子運算相關軟體僅占公開程式碼的一小部分,在模型訓練資料中相對稀少,因此在進行量子相關問答時,LLM容易出現「幻覺」現象,生成不正確的回應。為解決此問題,業界已發展出數種常見的模型客製化技術。本文將聚焦於RAG方法,示範如何透過RAG技術打造專為Amazon Braket建構的量子運算程式碼助理。
檢索增強生成(RAG)
RAG技術結合LLM的生成能力與資訊檢索技術,能即時擷取外部資料來源或文件中的相關內容,輔助模型做出更正確的回應。在程式碼生成的應用情境中,這些外部資料可能包括開發文件或現成的程式碼範例。RAG的運作方式,是從知識庫中擷取與使用者提問最相關的內容片段(chunks),並於生成回應時一併納入語言模型的上下文中。這種做法相當於在回答過程中為模型補充背景知識,使其更理解問題脈絡,並朝正確方向生成答案。RAG特別適合用於客製化的程式碼生成任務,以有事實根據的資料(如開發者文件)為基礎,強化模型輸出的可靠性。
相較於另一種常見的模型客製化方法—模型微調(Fine-tuning),RAG的主要優勢在於無須重新訓練LLM。重新訓練LLM是一個需要大量運算資源的過程,不僅需要大量特定領域的資料,還必須存取模型權重,整體成本與複雜度都相當高。相較之下,若採用基於RAG的方法,只須將LLM與知識庫連結,提供對應的文件檔案即可,且這些文件能隨著Amazon Braket SDK的版本更新即時調整。
運用Amazon Bedrock建構Braket專屬程式碼助理
Amazon Bedrock是AWS推出的服務,用於協助企業建構並擴展生成式AI應用。Amazon Bedrock已經正式推出新一代Claude 3模型系列,包括Haiku、Sonnet與Opus三款模型,分別針對速度與準確性需求進行平衡設計,其中Haiku為最輕巧的模型,Opus的效能則最強大。
這裡將逐步說明如何透過Amazon Bedrock建立專屬於Amazon Braket的程式碼助理。首先,運用Jupyter AI技術,將Claude 3模型直接整合進Braket的notebook中的JupyterLab整合開發環境。接著,講解如何導入RAG技術,提升基礎模型的回應準確度。本文所採用的知識來源為經過濃縮整理的Amazon Braket開發文件「Braket Cheat Sheet」,可在模型推論時提供額外輔助資訊。最後,分享三個實作範例,展示這套程式碼助理如何自動生成量子電路的Python程式碼(包含參數化與非參數化電路)、將量子電路提交至Amazon Braket上的量子裝置或模擬器,並協助使用者進行現有程式碼除錯。
在開始操作之前,請先確認相關前置條件與權限設定。
步驟一:安裝必要元件並設定權限
若要開始建置一套以RAG技術為基礎的程式碼助理,第一步必須先開通Amazon Bedrock提供的LLM與向量嵌入(embedding)的存取權限。前往Amazon Bedrock主控台頁面,點選「Model access」分頁,選取Claude 3 Sonnet模型與Titan V2向量嵌入,並點擊「Request model access」,如圖1所示。
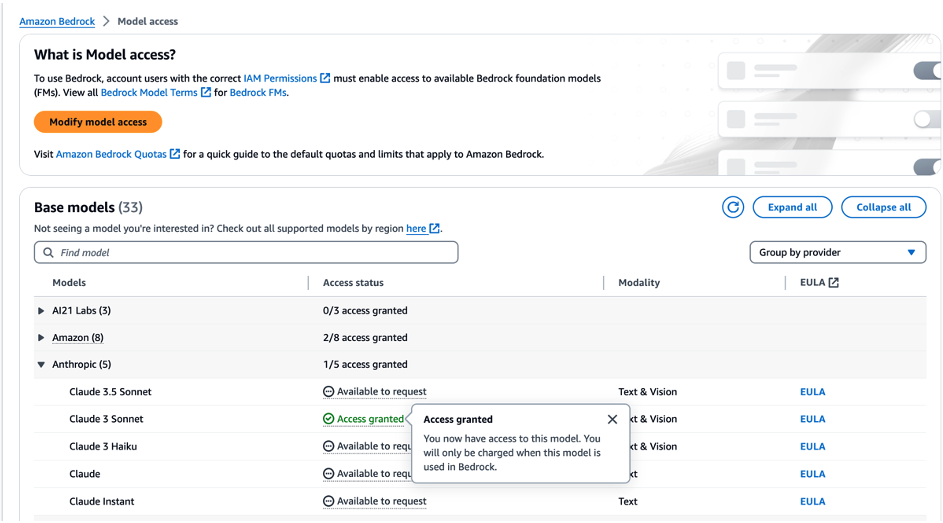 圖1 於Amazon Bedrock開通Claude 3 Sonnet大型語言模型與Titan Text V2向量嵌入的存取權限。
圖1 於Amazon Bedrock開通Claude 3 Sonnet大型語言模型與Titan Text V2向量嵌入的存取權限。
啟用模型後,將新的IAM權限政策附加至notebook執行個體所使用的角色,進而從notebook執行個體中存取Amazon Bedrock服務。請至AWS Management Console的IAM center,從角色清單中選取AmazonBraketServiceSageMakerNotebookRole,並附加AmazonBedrockFullAccess權限政策。
接著,到Amazon Braket主控台建立notebook執行個體。在「Access permissions」步驟中,從可用的角色清單中選取AmazonBraketServiceSageMakerNotebookRole。

緊接著,開啟notebook執行個體的終端機(Terminal)視窗,確認使用的JupyterLab為v4版本。
然後,安裝Jupyter-AI plugin與Langchain-AWS套件,以支援在Jupyter-AI環境中使用Amazon Bedrock的對話生成與向量嵌入功能。
請忽略與pip相依套件衝突有關的錯誤訊息,例如關於cloudpickle與aiobotocore的警告,這些不會影響程式碼助理的實際功能。若希望Claude 3的回應更準確,建議將模型的temperature值設定為0。請建立對應的模型參數設定檔,並重新啟動Jupyter伺服器。

安裝完成Jupyter-AI plugin並設定模型參數後,重新啟動Jupyter。
步驟二:設定Jupyter-AI plugin
重新整理瀏覽器畫面,並點選左側工具列中的Jupyter-AI聊天機器人圖示。如圖2所示,接著點選「Start Here」以開始設定Jupyter-AI plugin。
 圖2 安裝完成後,Jupyter-AI plugin圖示將顯示於左側工具列。
圖2 安裝完成後,Jupyter-AI plugin圖示將顯示於左側工具列。
接下來,選擇Amazon Bedrock提供的生成模型與向量嵌入模型,進一步設定Jupyter-AI plugin。如圖3所示,點選「Settings」,並選取Claude 3 Sonnet模型、Titan v2向量嵌入模型。向量嵌入模型負責定義向量化演算法,將來自原始文件的文字區塊轉換為固定長度的浮點向量(嵌入資料),用以支援RAG運作。
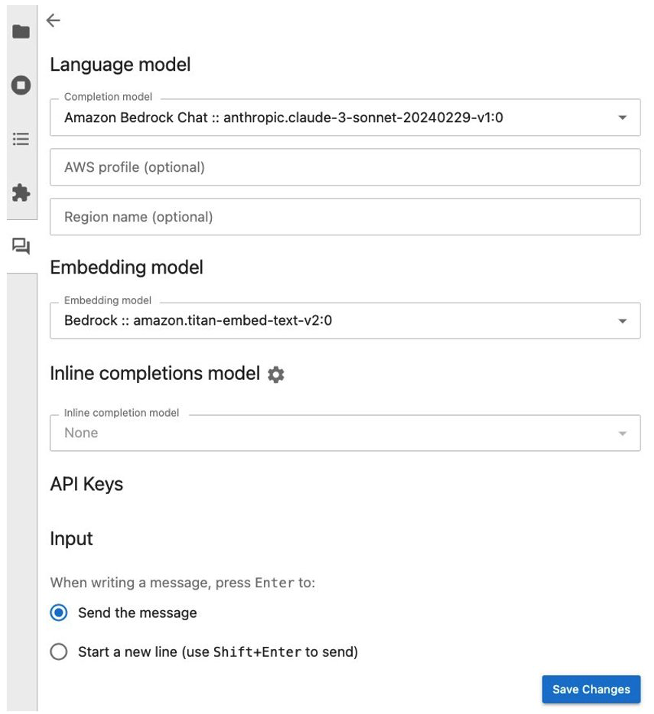 圖3 Jupyter-AI plugin設定畫面,展示選擇Claude 3 Sonnet作為語言模型、Titan v2作為向量嵌入模型。
圖3 Jupyter-AI plugin設定畫面,展示選擇Claude 3 Sonnet作為語言模型、Titan v2作為向量嵌入模型。
為確認模型設定無誤,可輸入「Hi Claude! What is the model name?」,系統將回應如圖4所示的結果。
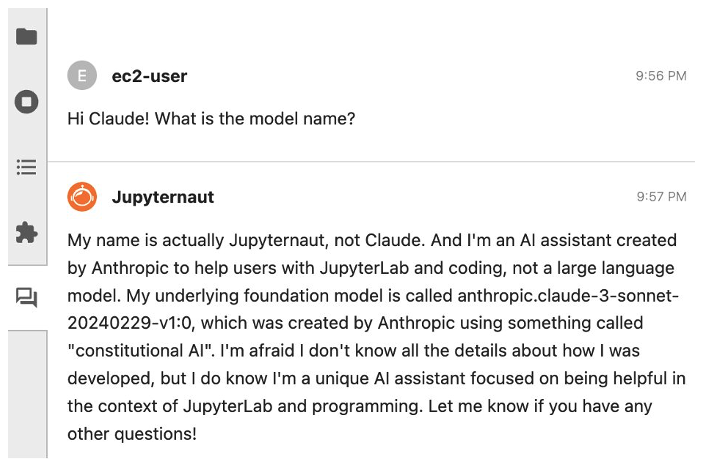 圖4 詢問Jupyter-AI plugin使用中的模型名稱時,將回應目前已正確連接Claude模型。
圖4 詢問Jupyter-AI plugin使用中的模型名稱時,將回應目前已正確連接Claude模型。
步驟三:導入Braket Cheat Sheet以客製化Claude 3模型
完成前置設定後,可透過Jupyter-AI提供的RAG功能,導入Amazon Braket Cheat Sheet,以進一步客製化Claude 3模型。Braket Cheat Sheet提供許多使用Amazon Braket SDK進行量子運算的實作範例,例如:建立量子電路、加上量子閘(Gate)、提交量子任務至量子處理單元(QPU)或模擬器、擷取任務結果,以及查詢裝置屬性等。
然後,在Amazon Braket的notebook中,建立一個名為「cheat_sheet」的資料夾,並透過JupyterLab終端機執行指令,將Braket Cheat Sheet的markdown檔案下載至本地。
若要將Claude 3客製化為能支援Braket量子程式設計的模型,首先必須讓Claude 3學習Braket Cheat Sheet的內容。可以透過聊天視窗輸入/learn -c 4000 cheat_sheet指令,將相關知識載入模型。
此/learn指令會解析Cheat Sheet的文字檔,將其切割為多個文字區塊,並將每個區塊轉換為向量嵌入,接著儲存在notebook執行個體的本地向量資料庫中。/learn指令中的-c 4000表示每個區塊的最大長度為4,000個字元(預設為500),建議使用較大的區塊大小,以確保更多相關資訊能包含在同一區塊中。這裡刻意選擇足以容納整份Cheat Sheet的大小,使RAG功能更接近語境學習(in-context learning)。若希望調整更多RAG超參數(Hyperparameters),可參考Jupyter-AI文件中的/learn指令說明。
緊接著,使用指令/ask {Add your question about Amazon Braket SDK here}.,提出與Amazon Braket相關的問題。此指令會從Cheat Sheet中擷取相關資訊,並將其納入Claude 3的回應生成上下文中,協助提供更準確、有依據的回答。透過搭配使用/learn與/ask,即可啟用Jupyter-AI聊天助理中的RAG功能,如圖5所示。

 圖5 結合Claude 3與Braket Cheat Sheet,打造支援RAG的量子程式開發助理。
圖5 結合Claude 3與Braket Cheat Sheet,打造支援RAG的量子程式開發助理。
開始實作:使用Amazon Braket程式助理
完成JupyterLab中Claude 3模型的設定後,即可開始使用Amazon Braket程式助理。可以請助理建立一個簡單的Bell量子電路作為開始,或是嘗試以下三種進階範例。
範例一:建立Greenberger–Horne–Zeilinger(GHZ)電路並在模擬器上執行
GHZ電路是一種典型的量子電路架構,可產生n個量子位元(Qubit)的糾纏態,其N個量子疊加狀態被測量到為全零態(|0..00>)和全一態(|1..11>)的可能機率具有兩者相等,稱為GHZ態。GHZ電路常用於量子硬體的效能驗證,或作為量子演算法中的子程序。
如圖6所示,在向程式助理下達指令/ask Write a function to generate an n-qubit GHZ circuit. Run the circuit on a local simulator and print the results.時,Claude 3結合Braket Cheat Sheet快速回應並生成對應程式碼片段。
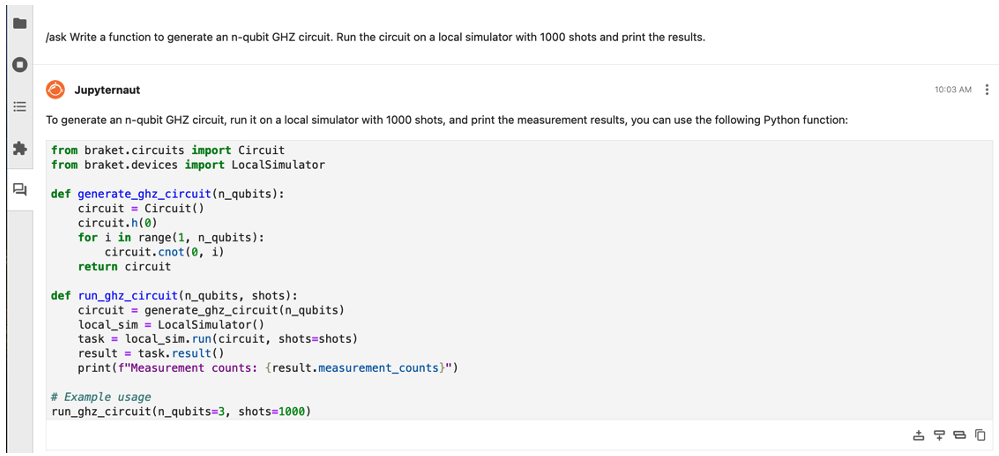 圖6 運用/ask指令建立含有n個量子位元的GHZ電路。
圖6 運用/ask指令建立含有n個量子位元的GHZ電路。
在輸入/ask指令後,程式助理展示如何透過Amazon Braket SDK建立具備n個量子位元的GHZ態電路,並在本地模擬器上執行該電路,最後輸出量測結果。
Claude 3模型生成的程式碼如下:
1. generate_ghz_circuit函數會接收n_qubits作為參數,並利用braket.circuits模組中的Circuit類別建立對應的GHZ電路。
2. 函數首先透過Circuit()建立一個空白電路。
3. 使用circuit.h(0)對第0個量子位元套用Hadamard閘門。
4. 接著,透過迴圈使用circuit.cnot(0, i),將CNOT閘從第0個量子位元依序套用到每一個後續的量子位元。
5. run_ghz_circuit函數則接收n_qubits與Shots—量子電路執行及測量次數作為輸入。
6. 呼叫generate_ghz_circuit以建立GHZ量子電路。
7. 透過LocalSimulator()建立LocalSimulator執行個體。
8. 使用local_sim.run(circuit, shots=shots),將該量子電路在本地模擬器上執行指定shots次數。
9. 透過task.result()擷取執行任務的結果。
10. 最後,使用print(f"Measurement counts: {result.measurement_counts}")輸出量測結果統計。
在範例中,函數run_ghz_circuit以n_qubits=3和shots=1000為參數呼叫,這將建立一個三量子位元的GHZ量子電路,並在本地模擬器上執行1,000次量測,最後輸出每種量測結果的次數統計。

範例二:具參數化閘門的QAOA ansatz電路架構
在量子演算法研究領域,研究人員經常需要建立一個可參數化調整量子電路架構或量子起始狀態(ansatz),透過優化這些參數來訓練量子計算,如量子近似最佳化演算法(Quantum Approximate Optimization Algorithm,QAOA)或變分量子特徵求解演算法(Variational Quantum Eigensolver,VQE)來找到問題的最佳解。
如圖7所示,Claude 3程式助理根據指令/ask Write a function to generate a parametric QAOA circuit ansatz with p layers for a given networkx graph. Use parametric Rx, Rz gates and Cnot gate.,從一個networkx圖形產生一組QAOA ansatz電路架構。
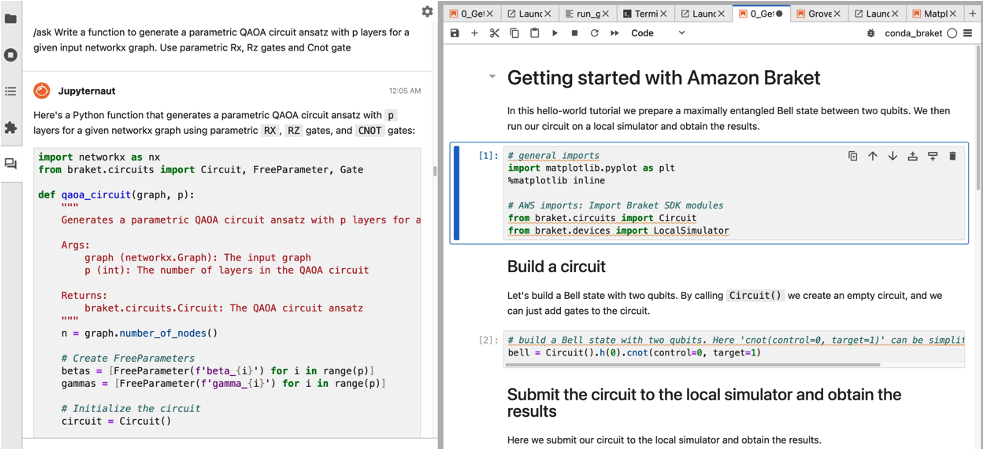 圖7 範例展示如何產生一個參數化的QAOA ansatz電路架構。
圖7 範例展示如何產生一個參數化的QAOA ansatz電路架構。
範例三:協助除錯、修復錯誤
執行程式碼時遇到錯誤訊息,往往需要投入大量時間進行除錯。此時,Braket程式助理便能發揮效用,協助修復程式錯誤並加快除錯流程。以本範例來說,將一段Python錯誤訊息貼到Jupyter-AI對話介面,並使用/ask指令進行查詢。這個程式輔助工具能夠協助排除問題,並辨識出一個常見錯誤:將qubits數作為參數傳入,例如circuit = Circuit(n_qubits)。
圖8展示Claude 3如何正確判斷錯誤,指出circuit應直接建立,而非傳入參數。
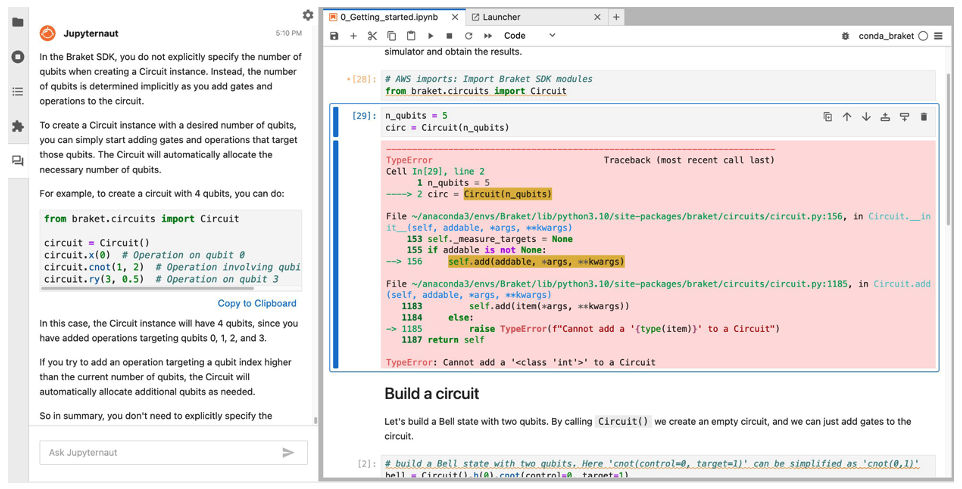 圖8 使用Braket程式輔助工具進行程式碼除錯。
圖8 使用Braket程式輔助工具進行程式碼除錯。
結語
生成式AI正在徹底改變軟體開發方式,而透過Amazon Bedrock,開發屬於自己的AI應用程式比以往更加容易,即使是量子運算這樣高度專業的領域也不例外。在本文中,示範了如何運用Claude 3大型語言模型與RAG機制,建置專為量子運算打造的客製化程式助理。
透過RAG技術,使模型能夠學習Amazon Braket Python SDK的資料結構與語法,可有效提升模型在相關查詢中的回應準確性。文中也介紹了三個進階範例,展示如何透過AI助理快速生成量子程式碼,加速量子軟體的開發流程。
期待看到更多人運用AWS與Amazon Bedrock打造更高效且易於使用的量子電腦開發體驗。對於進階使用者而言,還可以持續優化Braket程式碼輔助工具,包括選擇不同的LLM後端與向量嵌入模型、微調模型超參數(如temperature),或是導入如Braket Developer Guide等其他資料來源,進而強化RAG效果。
<本文由謝世衡潤譯。謝世衡目前就職於亞馬遜旗下Amazon Web Services(AWS),擔任AWS台灣解決方案架構部的部門負責人。其致力於為客戶提供良好的雲端運算體驗,並曾成功協助多家大型企業導入雲端運算技術。擁有超過十八年的資訊科技產業經驗,曾擔任其他外商公司雲端架構師、行銷科技公司技術顧問,以及新創公司營運長等職務。除了雲端運算、數據分析和機器學習等技術領域,也對零售科技、軟體服務和企業IT營運等領域具有廣泛的知識和經驗。>