Deepfake可將影片中人物的臉換成另一人臉的技術,此項技術的問世雖然有實際上的用途,但也伴隨而來許多新問題。本文將就Deepfake技術進行介紹,分析其正面與負面的影響,並透過實作來展示Deepfake技術,整理出相關的防制方法。
近年來電腦科學領域快速的成長,包括人工智慧(Artificial Intelligence)、大數據(Big Data)、機器學習(Machine Learning)、深度學習(Deep Learning)等,這些技術逐漸成為網路上熱門的搜尋關鍵字,也使各國近年來投入大量資金研發,將這些技術運用在各領域上,舉凡物流業、金融業、智慧機器人、電腦視覺、數據分析等,逐步與一般生活結合。
然而,在過程中不免會出現有心人士利用這些技術去做一些侵犯他人權益的事情,例如有心人士將人工智慧技術使用在換臉上,將女明星的臉植入色情片或是不知名的網頁照片中,再把偽造的影片或照片散播到網路上,因而侵犯該女明星的名譽,這種針對影片進行換臉的技術稱之為「Deepfake」。
在Deepfake中又有一項技術叫做puppet-master,此技術是與Deepfake不一樣的是,Deepfake可以將兩個不同人的人臉做對換,然而puppet-master則是控制目標人物的人臉,就跟操縱一個木偶一樣。在目前出現在新聞媒體版面中有關於Deepfake的新聞,多是弊大於利,因此如何防治有心人士濫用並且善用這項技術是目前各國的重要課題。接下來,介紹Deepfake與相關的技術,討論Deepfake所帶來的影響,並展示以puppet-master進行的實驗,最後則提出因應的建議。
認識Deepfake
以下介紹Deepfake的發展源由、所造成的影響,以及與該技術的相關發展背景。
Deepfake發展概況
2017年開始,網路上開始出現一個新名詞Deepfake,這是一個由深度學習(Deep Learning)與偽造(Fake)兩個字所組成的混合詞,利用人工智慧的技術實現原本需要人工合成的影像,而且可以特別只運用在人臉的部分,將一張新的人臉移植到影片中的人臉上,乍看之下,難以分辨出到底是真是假。
Deepfake造成影響
由於Deepfake技術處理過後的效果太好,對現實生活帶來不小的影響,遍及了政治、經濟、社會各個層面等,以下分別說明Deepfake的正面與負面效益。
Deepfake技術應用所造成的正面效益,大致包括以下三項:
1. 教育層面:在教育方面,Deepfake讓老師在授課過程中製作出歷史人物的影像,播放出來直接與學生互動,藉由此種方法讓課程更加生動,增加學生上課的意願,讓學生對課程內容印象更深刻。
2. 影視層面:美國知名電影公司好萊塢運用Deepfake技術,讓已經逝世的電影明星重返大螢幕,除此之外,電影中的替身可以被模擬出來代替本尊,也能夠模擬出許多臨時演員,節省電影中加拍或補拍的成本。
3. 協助犯案調查層面:美國加州一名大學教授,透過僅僅幾張模糊的犯罪車輛照片,利用自製的Deepfake技術,複製出數百萬張的車牌照片進行訓練,因而找出可能的車牌號碼,讓原本無解的案件露出一道曙光。
Deepfake技術帶來的負面影響,大致分成以下幾種:
1. 個人層面:當Deepfake被用於偽造女性裸照或將女性人臉植入色情片當中時,相當於侵犯女性的隱私權。Deepfake可能製造出假的證據,使得被告得以脫罪,又或者讓無罪的人關進監獄,而當諸如此類的事件層出不窮時,每個人的心理會產生恐慌,擔心著會不會成為下一個受害者,進而對社會感到不信任,人與人之間的距離逐漸疏遠,影響社會正常運作。
2. 政治層面:當Deepfake用來偽造政治人物的言行舉止時,將損害民主,增加人民對政治的不信任感,尤其是被運用在選舉抹黑上,例如在選舉的前幾天發布偽造的影片,就算當事人跳出來指正是假的,仍可能無法挽回已經失去的選票,進而影響選舉結果。
3. 國家層面:當有心人士利用Deepfake偽造影片宣稱國家發布緊急動員令,要求人民做出緊急動員指令,將會造成人民恐慌以及人民對政府的不信任,甚至更嚴重可能會造成人民傷亡。
4. 經濟層面:當Deepfake的受害者為一家公司,例如偽造該公司老闆的聲音或影片要求進行轉帳或執行特定交易,輕則損失錢財,重則有損公司名譽。有心人士更可能偽造公司老闆的影片對未來抱持悲觀想法或是宣布重大投資,來影響投資人的股票交易,因而從股票市場賺取不正當利益,如果接連多家上市上櫃公司受影響,將嚴重影響整體經濟發展。
Deepfake技術介紹
以一段影片中的人物來轉換為另一個人物的例子來做說明,簡單來說,可以把Deepfake分成五個過程,如圖1所示,其中兩個核心部分包括「人臉偵測」和「人臉轉換」。
 圖1 人臉轉換原理圖。
圖1 人臉轉換原理圖。
在人臉偵測方式中,含括HOG、68個特徵點、CNN等相關技術。
HOG全名為定向梯度長方圖(Histogram of Oriented Gradient),是一種演算法,將人臉分成眼睛、眉毛、鼻子、嘴巴、下巴五個部分。先抓出圖片中的正樣本(含有人臉的部分),再計算圖像梯度的統計值,之後再找出圖片中的負樣本(不含有人臉的部分),一樣再計算統計值,最後將結果進行分類並調整負樣本。
所謂的68個特徵點,是將人臉定義出68個特徵點,用於計算人臉角度,缺點為只能使用正臉,如出現側臉部分,就必須使用其他的方式協助偵測,也要注意人臉解析度太低將無法進行偵測。
而CNN的正式名稱是「卷積神經網路(Convolutional Neural Network)」,可被用來判斷當人臉出現側臉時所使用的方法,透過名為「卷積(Convolution)」的方法,將像素值進行反覆計算以擷取特徵進行判斷。
在人臉轉換過程的部分,則是採用AutoEncoder的方法。AutoEncoder可分為編碼(Encoder)與解碼(Decoder)兩部分,此過程也可以被理解為資料壓縮加上資料重建的過程。圖2所呈現的就是來源影像經過編碼後,若以不同的特徵來解碼重建,就會產生出相似的偽造影像。
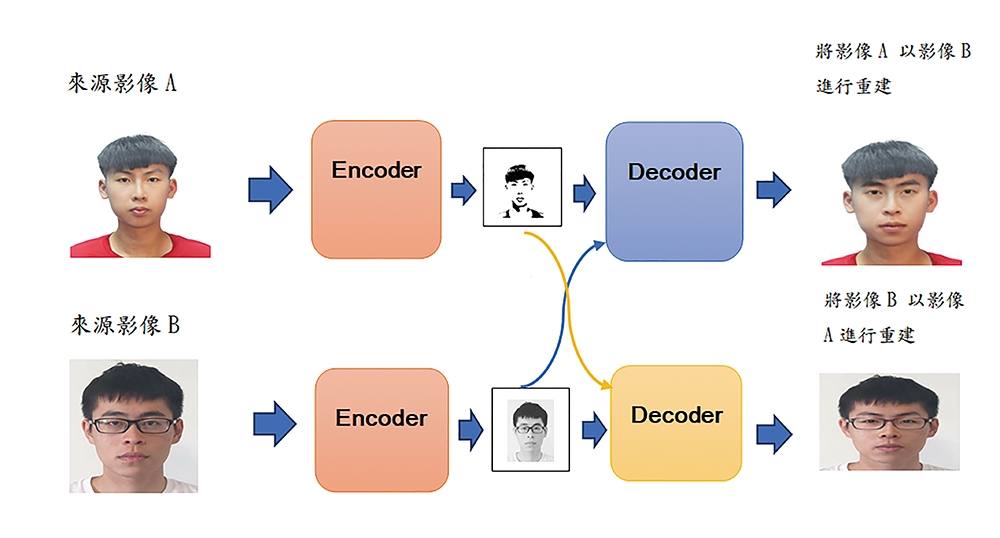 圖2 AutoEncoder運作流程圖。
圖2 AutoEncoder運作流程圖。
進行實際測試
介紹過Deepfake技術之後,就來實際測試一下。
使用環境及軟體
為了呈現Deepfake中像是puppet-master的效果,這裡以Dat Tran在GitHub上的face2face-demo程式來做介紹,程式碼來源為「https://github.com/datitran/face2face-demo」。本項實驗必須先安裝以下的軟體並且設定運作環境,程式碼才可以順利地運行。
OpenCV(Open Source Computer Vision Library)是一個跨平台的電腦視覺庫,並開放商業及研究領域使用,OpenCV應用於即時的圖像處理、電腦視覺及圖形識別程式。在此所要安裝的是OpenCV 4.1.1.26版,可透過Python套件管理工具進行安裝,相關指令內容如下:
Pip install opencv-python== 4.1.1.26
TensorFlow
TensorFlow是一個開源的函式庫,最初是由Google大腦團隊進行開發,用於研究Google生產與開發,現今廣泛應用於各種感知和語言的機器學習。目前TensorFlow已經來到2.0版,但由於版本之間的差異頗大,所以在此所要安裝的是舊有的TensorFlow 1.9.0版本,安裝指令如下:
Pip install tensorflow==1.9.0
Dlib是一個函式庫工具包,包括機器學習演算法及工具,內含了建立好的人臉68個特徵等其他模型,可開放免費使用。本次所要安裝的是Dlib 19.8.1版,安裝指令如下:
Pip install dlib==19.8.1
執行程式碼
第一步,需要產生訓練資料,先執行如下的指令:
python generate_train_data.py --file angela_merkel_speech.mp4 --num 400 --landmark-model shape_ predictor_68_face_landmarks.dat
這裡是利用OpenCV和Dlib技術,將影片中包含有人臉的片段(Frame)擷取出來,有人臉的話,就用68個特徵點進行記錄,如圖3所示。
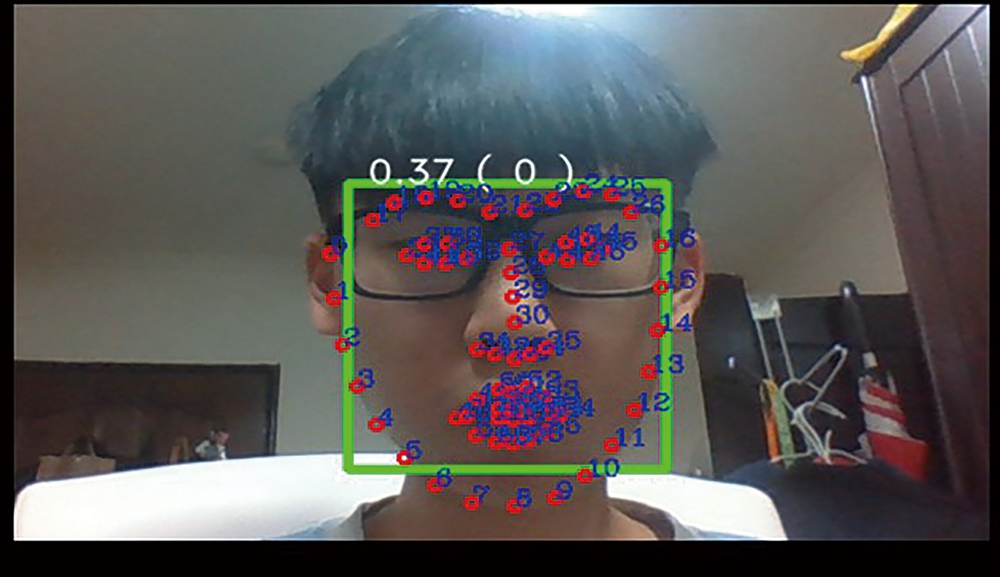 圖3 68個特徵點圖。
圖3 68個特徵點圖。
本例所使用的測試影片為德國總理梅克爾在公開場合演說,檔名為angela_merkel_speech.mp4。如圖4所示,當偵測到人臉的時候,便會擷取出來,並且利用68個特徵點描繪成圖5的特徵點圖,這些被擷取出的特徵點圖會被拿來當作訓練的資料。
 圖4 以德國總理梅克爾演說影片來做示範。
圖4 以德國總理梅克爾演說影片來做示範。
 圖5 根據68個特徵點描繪出的人臉。
圖5 根據68個特徵點描繪出的人臉。
圖6的程式碼片段來自generate_train_data.py,從中可見到所運用的即是68個特徵點在人臉上做描繪。這些特徵點可以分成九個部分,每個部分都有各自不同的編號,例如左眼眉毛是點22~27、右眼眉毛是27~31、左眼為42~48、右眼為36~42等等。
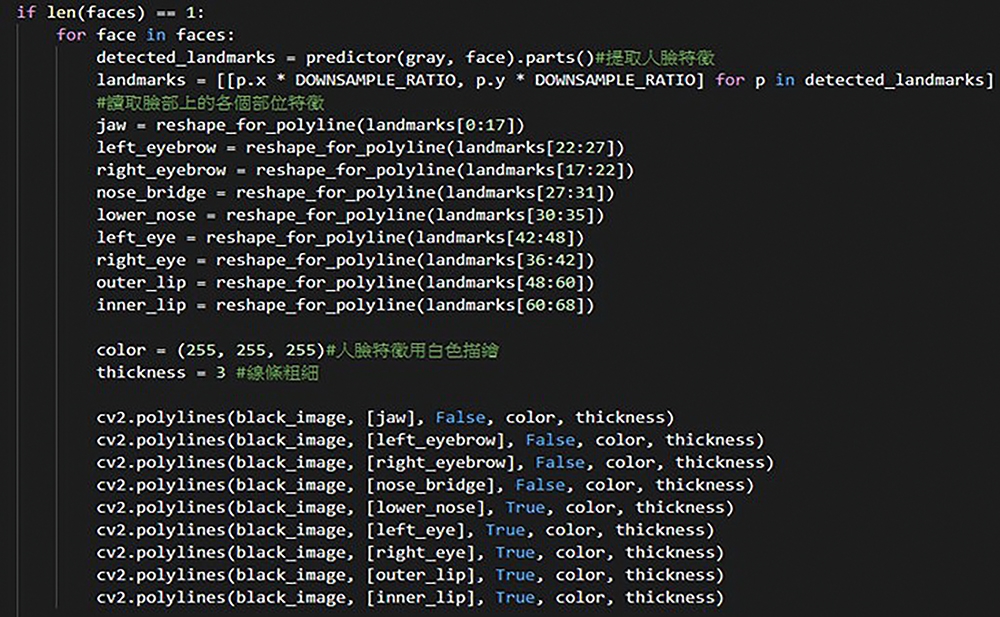 圖6 generate_train_data.py程式碼片段。
圖6 generate_train_data.py程式碼片段。
接著,使用pix2pix程式進行訓練。以pix2pix程式搭配卷積神經網路(CNN)進行訓練,將梅克爾影片中擷取出的特徵圖與包含人臉的相片做結合,並透過訓練200次來建立所需模型,詳細操作方式如圖7所示。
 圖7 訓練模型所需的參數。
圖7 訓練模型所需的參數。
透過pix2pix產生後的「face2face-model」目錄下相關資料相當大(約975MB),所以接下來執行「reduce_model.py」縮減訓練出的Model,把與訓練過程和操作無關的東西去除掉,然後放到「face2face-redueced-model」目錄內。最後,執行「freeze_model.py」,把縮減完成的部分包裝成一個「frozen_model.pb」檔以方便使用,相關執行指令如下所示:
#縮減訓練model python reduce_model.py --model- input face2face-model --model- output face2face-reduced-model #包裝成pb檔 python freeze_model.py --model- folder face2face-reduced-model
檢視訓練後的成果時,就可執行run_webcam.py程式,運用訓練出來的模型frozen_model.pb與電腦上的視訊鏡頭,執行指令如下:
python run_webcam.py --source 0 --show 0 --landmark-model shape_ predictor_68_face_landmarks.dat --tf-model face2face-reduced- model/frozen_model.pb
測試結果如圖8所示,左邊為作者的照片,右邊則是德國總理梅克爾從影片中擷取出的人臉部分,執行這個「run_webcam.py」程式期間,可以看到右圖人物的表情與動作會跟左圖的人物一致,達到類似操縱木偶的結果。
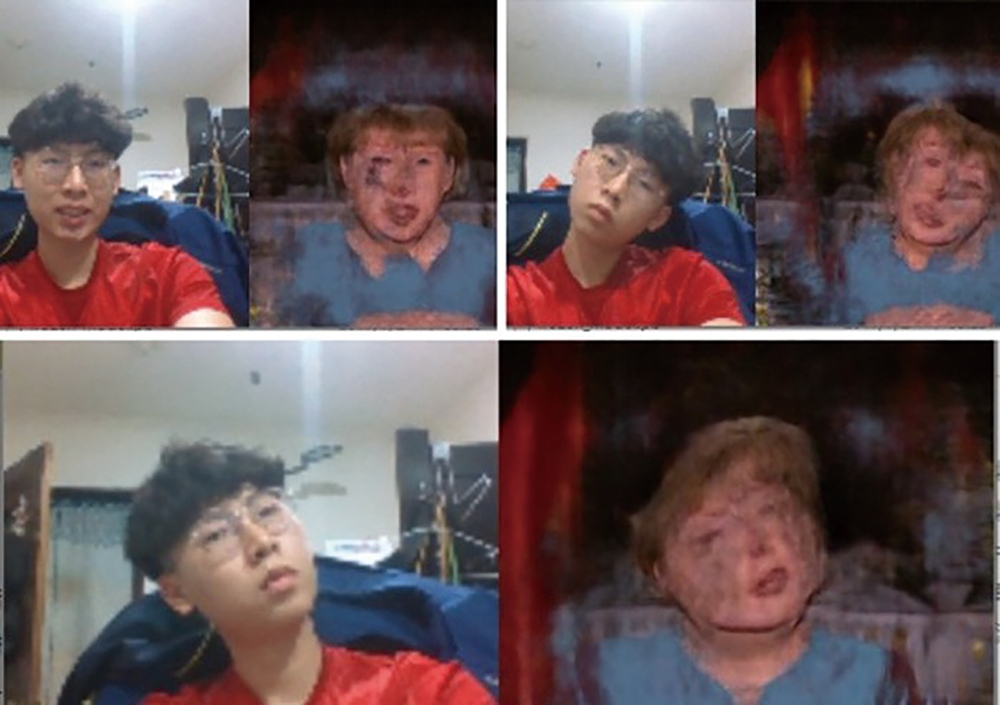 圖8 執行結果出爐。
圖8 執行結果出爐。
不過,由於實驗所用的電腦計算能力不夠,所以會有破圖的情況發生。
實際案例模擬
話說科技大廠台達公司最近流傳一段影片,此影片的內容為公司的董事長宣稱近期營運不佳將大舉裁員,台連公司的投資人也都接收到此部影片,在投資人大賣公司的股票之後,公司才發現到有惡意人士使用Deepfake來發布偽造影片,企圖影響台達公司在股價上的波動,以賺取其中的不法利益。
為了解決這次的風波,公司第一步採取的辦法是尋求法律協助,先禁止偽造影片的流傳。接下來,請公司資訊部門的工程師進行鑑識,發現偽造出來的影片中人物的嘴型與聲音並不一致,並且仔細觀察偽造出的影片,可以發現人臉和背景的交界處與真的影片有明顯的差異,因此可以證實這部宣稱老闆將大舉裁員的影片是經過偽造的。
圖9為使用戴眼鏡人的人臉轉移到沒戴眼鏡人臉上,乍看之下,跟真的照片沒有差別,若將偽造的圖片放大來檢視,就會發現眼睛周圍的像素呈現較為模糊,如圖10所示。
 圖9 合成照片的過程。
圖9 合成照片的過程。
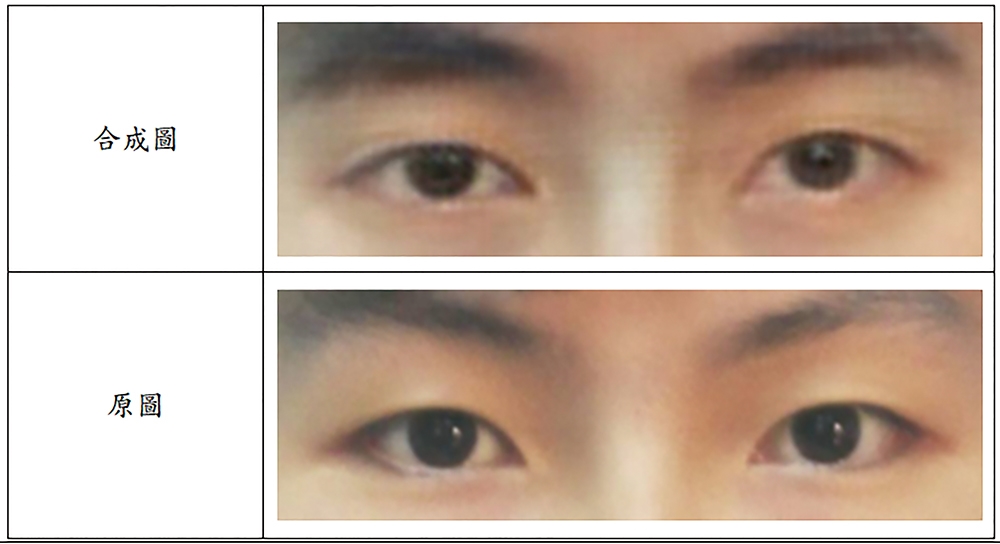 圖10 合成跟真實的人臉做對比。
圖10 合成跟真實的人臉做對比。
如何應對Deepfake
Deepfake所引起的爭議與可能的應對方式,可分成法律與技術兩方面,內容整理如表1所示。

結語
Deepfake這一項新技術的出現,使得在網路上所看到的每一張照片或是一部影片中出現的人物,都不一定是真實存在的。本文分析了Deepfake所可能影響的層面,並介紹Deepfake的相關技術,發現這並非是完全新創的技術,而是透過整合不同的技術所偽造。本文內所實驗的puppet-master技術,則是與換臉有所不同的技術,如同操作木偶般的方法,若是再加上結合聲音偽造,就容易讓人產生混淆。對抗Deepfake的方法,最主要的是透過法律途徑與科技技術,制定並宣導法律來避免有人使用Deepfake惡作劇或是進行詐騙行為;同時,透過科技技術協助判斷是否為Deepfake影片。截至目前為止,仍在持續強化與制定相關規範,好讓Deepfake能夠朝正向來運用,為科技發展帶來實質價值。
<本文作者:社團法人台灣E化資安分析管理協會(ESAM, http://esam.nctu.me/esam/)2018年創立,從事E化資訊安全的分析管理與學術研究,並與政府、產學及國際資安機構交流與合作,推廣資訊安全應用與發展,協助企業、產業評估資安分析與風險為宗旨。國立屏東大學多媒體實驗室(Multimedia Lab)2018年創立,由楊政興教授率領成員們致力數位多媒體應用與研究,其領域包含但不限於互動媒體設計、多媒體安全、資料庫安全、數據分析及影像處理。>