本文將以Stable Diffusion WebUI為主要實作平台,透過AnimateDiff外掛模組進行影片生成的實作,說明Stable Diffusion的運作原理、WebUI的安裝與使用,並探討影像生成可能產生的危害與防範措施,藉此掌握AI圖像生成技術的核心架構與應用,也可具備辨識與防禦AI影像濫用的基本概念。
隨著人工智慧的發展逐漸進入大眾生活,從聊天機器人、智慧客服到圖像生成,AI技術已廣泛運用在日常生活中,成為不可或缺的工具,其中Stable Diffusion的出現,更徹底改變了人們對圖像甚至是影像創作的想像,只需要簡單輸入文字描述,AI便能馬上自動生成極具真實感的圖片或影片。在此基礎上,Stable Diffusion WebUI提供圖形化操作介面,讓使用者可快速輸入Prompt、選擇模型並生成結果。
ComfyUI則以節點流程(Node Graph)的方式呈現,支援自訂模組、時間軸設定與多模型整合,成為影片生成的重要平台。結合AnimateDiff的動態模組與CogVideo的時序擴散技術,使用者可從純文字或靜態影像出發,自動生成具連續動態、鏡頭運動與物理一致性的短片。
另一方面,Sora 2的出現代表了生成式AI的另一個里程碑。作為OpenAI推出的新一代文字轉影片(Text-to-Video)模型,Sora 2結合多模態擴散模型與影片生成引擎,能理解三維空間關係與真實世界物理規則,生成高解析度、長時序、具連貫動態的影片內容。與WebUI或ComfyUI等開源系統不同,Sora 2著重於生成品質與真實感的提升,其成果足以應用於電影預視覺化、動畫分鏡與數位廣告製作等專業領域。
由於Stable Diffusion與Sora2可生成幾乎與現實難以區分的圖像,這讓假訊息、偽造證據、影像詐欺等資安風險逐漸浮現,並且充斥在日常生活當中。除此之外,Stable Diffusion模型本身的資料來源若未經過妥善審查,亦可能含有敏感資訊或侵犯他人版權的內容,進而產生隱私或法律方面的爭議。
本文將從Stable Diffusion WebUI的安裝與操作出發,介紹其基本架構與功能,並延伸至AI生成影像的安全議題探討,透過理論與實作並重的方式,讓大家在掌握AI創作技術的同時,也能具備辨識與防禦風險的能力,進一步思考技術便利與倫理安全之間的平衡。
背景知識介紹
在深入了解Stable Diffusion WebUI的實作與應用之前,必須先掌握其背後的運作原理與技術基礎。
Stable Diffusion技術原理
生成式人工智慧(Generative AI)結合了深度學習(Deep Learning)、自編碼器(Autoencoder)以及擴散模型(Diffusion Model)等等多項技術的成果,使電腦不再只是被動的識別資料,而是能主動地生成新內容,Stable Diffusion正是這些技術結合的代表之一。
Stable Diffusion以潛在擴散模型(LDM)為核心,能將人類輸入的語言提示(Prompt)轉換成對應的影像結果,使得任何人只需要輸入文字,就能創造出風格多變、細節逼真的圖像作品,不同於早期的生成對抗網路(GAN),擴散模型能夠產生更加穩定且品質更高的結果,具有更強的可控性,並且將傳統的擴散模型壓縮到潛在空間(Latent Space)中運算,大幅減少資源消耗,使得一般消費級顯示卡也能執行。
這項技術不僅僅是一個圖像生成工具,更是一個複雜的深度學習系統,它涉及了模型訓練、特徵編碼、雜訊還原與條件控制等多層次的機制,而生成式技術的演進不再局限於靜態圖像,透過延伸模組如ControlNet、LoRA(Low-Rank Adaptation)以及AnimateDiff等,讓模型能夠執行風格轉換、結構控制,甚至影片生成等任務,成為了多媒體內容生成的新核心,這不僅拓展了創作應用的範圍,也引出了更多需要關注的議題,例如生成影片中的真實性、倫理與資安風險。
因此,在正式進入Stable Diffusion WebUI的安裝與操作流程之前,必須先理解各種AI工具的技術原理與運作邏輯,包括生成圖片與動畫影片的機制,這樣才能更清楚地看見生成式AI的本質,並在應用與防護之間取得平衡。
擴散模型(Diffusion Model)
擴散模型(Diffusion Model)屬於生成式人工智慧(Generative AI)中一種重要的架構,其核心思想為:先將「真實數據」(例如一張圖像)逐漸加入隨機高斯雜訊(Forward Diffusion),直到圖像變成近似純雜訊;接著模型學習如何從這樣的雜訊中反向去噪(Reverse Diffusion),最終恢復出清晰的圖像(圖1)。在Stable Diffusion中,這樣的過程被用於從「隨機雜訊」生成與「文字描述」相對應的圖像。
 圖1 擴散模型。
圖1 擴散模型。
潛在空間(Latent Space)運作
在早期的影像生成技術中,AI是直接在「像素」層面對圖像進行加噪與去噪,也就是對每一個小小的色塊進行運算。但當圖像尺寸變大、維度增加時,計算與記憶體成本會變得非常龐大。為了解決此問題,Stable Diffusion採用了「潛在擴散模型(LDM)」的方式。
簡單來說,就是先把圖片轉換成一組「簡化後的數據」,也就是所謂的潛在向量,就像把一張高清照片變成縮圖,雖然人眼看不見細節,但AI還是能夠理解畫面的大致形狀、顏色與構圖。接著,就在這個簡化後的空間中進行雜訊擴散與去噪,最後再由解碼器還原成一張完整的圖片。這個壓縮與還原的過程是由一種稱為「變分自編碼器(VAE)」的模型負責,其主要目的是為了節省運算資源、能結合多種條件生成、使一般電腦也能運行(圖2)。
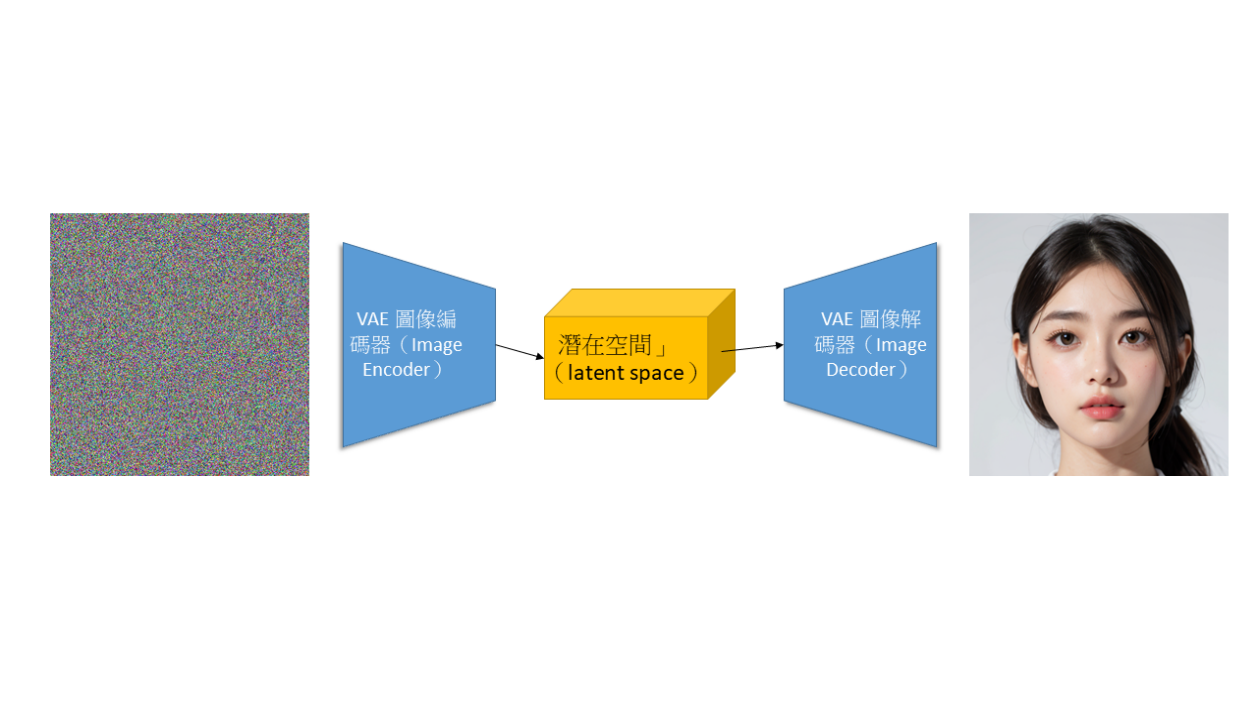 圖2 潛在空間(Latent Space)運作。
圖2 潛在空間(Latent Space)運作。
CLIP文字編碼器如何運作
CLIP(Contrastive Language–Image Pre-training)是由OpenAI訓練的一個雙模態模型,能夠理解「文字」與「圖像」之間的關聯,CLIP的訓練資料包含數億組「圖片+說明文字」配對,文字向量不只有「物體資訊」,還包含「語氣、風格、光線、構圖」等抽象特徵,如表1所示。

在訓練過程中,CLIP的「文字編碼器(Text Encoder)」會學習如何將文字轉換成一組數值(文字向量),而CLIP的「圖像編碼器」也會學習如何把圖片轉換成另一組數值(圖像向量)。然後,模型會學會讓這兩組向量在語意相同時接近、語意不同時遠離。
因此,CLIP學會了:「哪種文字描述對應哪種圖像概念」,例如「A cute corgi sitting under the tree, ultra realistic lighting.」這句話是整個生成過程的起點。模型將依此提示決定最終影像的主題、風格、光影與構圖。文字會被送入CLIP的文字編碼器,而CLIP會將每個詞轉換成語意向量(Text Embedding)。這些向量能描述內容(例如corgi、the tree)與風格(例如ultra realistic)。文字嵌入的輸出是一個高維度矩陣,目的是讓電腦理解文字的語意,而非只是字面字串。
生成影片的原理
接下來,說明生成影片的原理。
Stable Diffusion原本只能生成靜態的影像,然而研究人員與開源社群逐步將其原理延伸至時間序列領域,發展出文字到影片(Text-to-Video)與圖像到影片(Image-to-Video)的應用。其中最具代表性的擴展模組為AnimateDiff,它在不用重新訓練主模型的情況下,透過「運動模組(Motion Module)」與「時間一致性控制(Temporal Consistency)」的設計,使得影像能在多幀之間維持動作連貫。
訓練時,Motion Module會從影片資料集中學習物體運動的潛在模式,例如鏡頭平移、人臉表情變化或角色移動。生成時,它會在潛在空間中調整雜訊的演變方向,使得連續幀的變化符合真實運動邏輯。簡單來說,就是將Stable Diffusion生成出來的多張圖片連貫成一部影片(圖3)。
 圖3 多張圖片連貫成一部影片。
圖3 多張圖片連貫成一部影片。
儘管AnimateDiff顯著擴展了Stable Diffusion的表現力,但目前仍存在以下的限制:訓練影片資料有限,導致特定運動類型生成效果不穩定、長影片生成需要大量VRAM(通常> 10GB),若時間一致性控制不當,容易出現角色閃爍或變形現象,動畫的物理合理性與鏡頭穩定性仍需後處理輔助(如Frame Interpolation或Video Stabilization),但AnimateDiff仍代表生成式AI邁向多媒體創作的重要一步,為未來的虛擬內容製作、遊戲動畫、自動影片生成等領域奠定技術基礎。
CogVideo是一個能「用文字直接生成影片」的AI模型,由清華大學和上海人工智慧實驗室偕同開發。它與AnimateDiff不同,CogVideo是從頭設計、專門為影片打造的模型。簡單來說,它不只是讓圖片動起來,而是AI真的能從一句話,自己想像出連續的影片畫面。它的厲害之處在於能同時思考「畫面裡的東西」和「時間上的變化」。一般AI生成圖片只需要負責每個像素長什麼樣子,但影片的生成多了「連續性」,比如說角色跑步、風在吹、光影在移動,這些都要一格一格對得上,讓影片看起來更自然。
整個生成過程可以想像成先畫草圖、再上色的兩步驟。第一步,CogVideo會先生成一個較粗糙的影片,先確認動作方向、鏡頭移動和主要場景布局;就像先拍出一個低畫質的分鏡影片。第二步,它再幫每一格補上清楚的細節,讓畫面變得更真實、更符合文字內容。舉例來說,如果輸入「一隻貓在路邊伸懶腰」,它會先畫出整體動作,再慢慢補上貓毛的質感、陽光的顏色和路邊的景象。
不過,CogVideo雖然生成效果很強,但也有不少挑戰。首先,它對電腦效能要求較高,須使用像資料中心那種等級的高階顯示卡才能順利生成影片。其次,AI學習影片比學習影像更難,因為影片要兼顧動作、鏡頭、時間等等,所以資料收集不容易,有時生成的內容會產生異常,例如動作不自然或物體會漂浮。再來,它目前只能生成幾秒鐘的短片,對於長時間的連續影片仍有難度。最後,像水流、重力、反射這類物理效果,AI目前還是「看起來像」,不是真正理解,所以有時影片會出現閃爍或不合理的畫面。
相較於AnimateDiff依靠Stable Diffusion主模型並透過Motion Module讓多張圖片產生連續動作,以及CogVideo以大型影片模型生成粗略影片再逐格優化,Sora 2幾乎代表了當前影片生成技術的最先進的方法。Sora 2不是將圖片接起來,也不是先畫草圖再補細節,而是直接在多模態影片空間中生成具備高度物理一致性的完整影片,它能同時理解「畫面內容」、「時間變化」、「物體互動」、「鏡頭語言」與「聲音」,並以逼近現實的方式模擬世界。
訓練上,Sora 2使用了極大量的真實世界影片資料,讓模型能學會物體的動作邏輯,如重力、液體流動與光影變化等,並能維持角色在整段影片中的一致性,避免出現「影片閃爍」或角色變形等常見問題。與AnimateDiff需要依賴靜態模型、CogVideo受限於可生成的影片長度不同,Sora 2可依照使用者的文字描述直接生成具電影感的長片段畫面,並支援精準控制鏡頭角度、焦距、移動軌跡與場景節奏,甚至可一併產生符合情境的環境音或角色對話,使整段影片更具沉浸感。
簡而言之,如果說AnimateDiff是讓圖片動起來、CogVideo能畫出連續短片,那麼Sora 2就像是一個真正的「AI導演」,能理解世界並自行編排完整的視覺敘事,生成出目前最接近真實影片的AI內容。
AnimateDiff、Cogvideo與Sora 2三者之比較,可參考表2的說明。
情境演練
先準備好演練環境所需的工具,再開始動手實作。
環境需求與準備
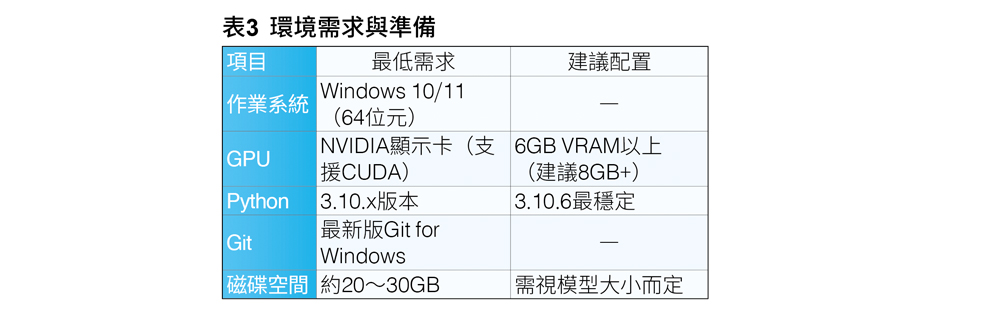
Stable Diffusion WebUI是目前最常用的介面,由Automatic1111維護。它讓使用者可透過網頁介面輸入Prompt生成圖片,並可安裝各種外掛以擴充功能,如ControlNet、AnimateDiff等。接著,以Windows平台為例,說明完整的安裝流程。相關的環境需求與準備,如表3所示。
‧Python 3.10.6:https://www.python.org/downloads/release/python-3106/
‧Git官網:https://gitforwindows.org
‧Automatic1111網頁:https://github.com/AUTOMATIC1111/stable-diffusion-webui
‧Python安裝指令:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Installation-on-Apple-Silicon
開始實作演練
小周是一位社群媒體活躍使用者,最近他在Threads與Instagram上看到許多「AI美女」帳號,並且在這些帳號所發布的影片中,看到了好友泰逸對AI帳號搭訕的留言,並且泰逸深信這些帳號中的照片與影片都是真人拍攝,小周深怕泰逸受到情感詐騙,因此小周決定自己下載WebUI並安裝AnimateDiff模組,嘗試生成一段類似的影片,讓泰逸能夠理解AI影片生成技術,並且能夠辨識AI影片。藉由他的實作歷程,可以從「技術使用」與「資安風險」兩方面進行演練。
首先,下載Stable Diffusion WebUI主程式。開啟命令提示字元(cmd)或PowerShell,輸入以下的指令並執行:
git clone https://github.com/ AUTOMATIC1111/stable-diffusion- webui.git
完成之後,將會出現資料夾「Stable-Diffusion-Webui」。再來,上網選擇模型檔並放置在資料夾中。Stable Diffusion本體模型不包含在WebUI中,須手動放入。可至Hugging Face或Civitai(圖4)下載模型,然後放入models資料夾(依模型版本不同而異)。
 圖4 Civitai網頁。
圖4 Civitai網頁。
接著,將安裝好的stable-diffusion-webui開啟,進行首次啟動與環境自動安裝。在stable-diffusion-webui資料夾內找到webui-user.bat,接著以雙擊方式執行,第一次會自動安裝套件與依賴。安裝過程約需5~10分鐘,依網路速度而異。
安裝完畢後會跳出Stable Diffusion WebUI頁面(圖5),或是出現類似以下的訊息「Running on local URL: http://127.0.0.1:7860」,在瀏覽器中輸入該網址,即可進入WebUI介面,此時就可操作圖片的生成。
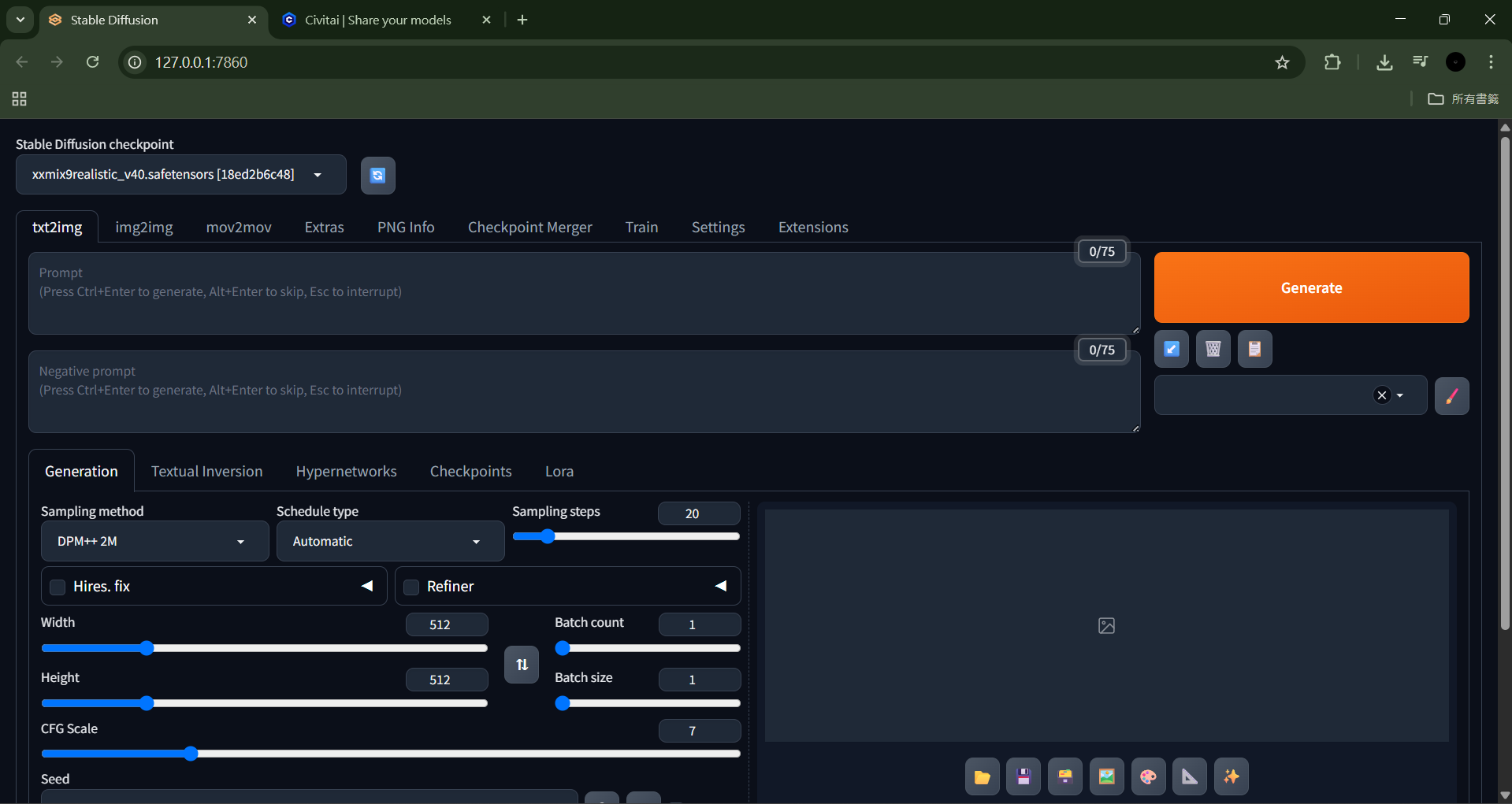 圖5 Stable Diffusion WebUI頁面。
圖5 Stable Diffusion WebUI頁面。
成功開啟Stable Diffusion WebUI頁面後,必須安裝AnimateDiff才能進行影片的生成。先在網頁介面上點選Extensions(擴充)頁籤,便可安裝各式Extension來擴增其能力,如AnimateDiff、ControlNet(最強影像控制工具)、LoRA Loader(輕量化模型載入器)等。接著,點選Install from URL分頁(圖6)。
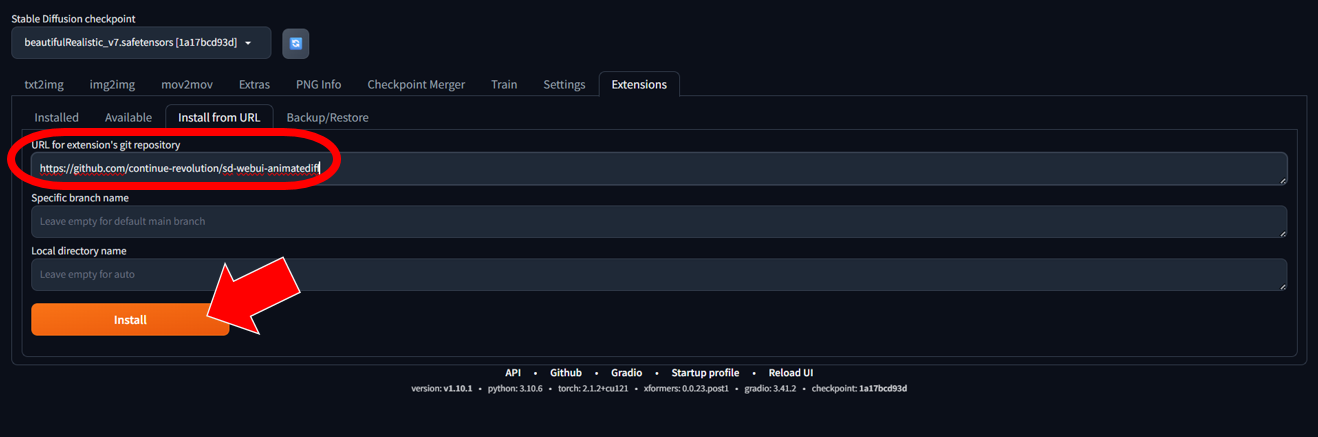 圖6 安裝AnimateDiff。
圖6 安裝AnimateDiff。
然後,在URL欄輸入「https://github.com/continue-revolution/sd-webui-animatediff」,並按下Install。等待安裝完成後,按Apply and restart UI(套用並重啟)。重新啟動WebUI後,介面會自動更新並出現AnimateDiff面板,通常會出現在txt2img與img2img的欄位內(圖7)。
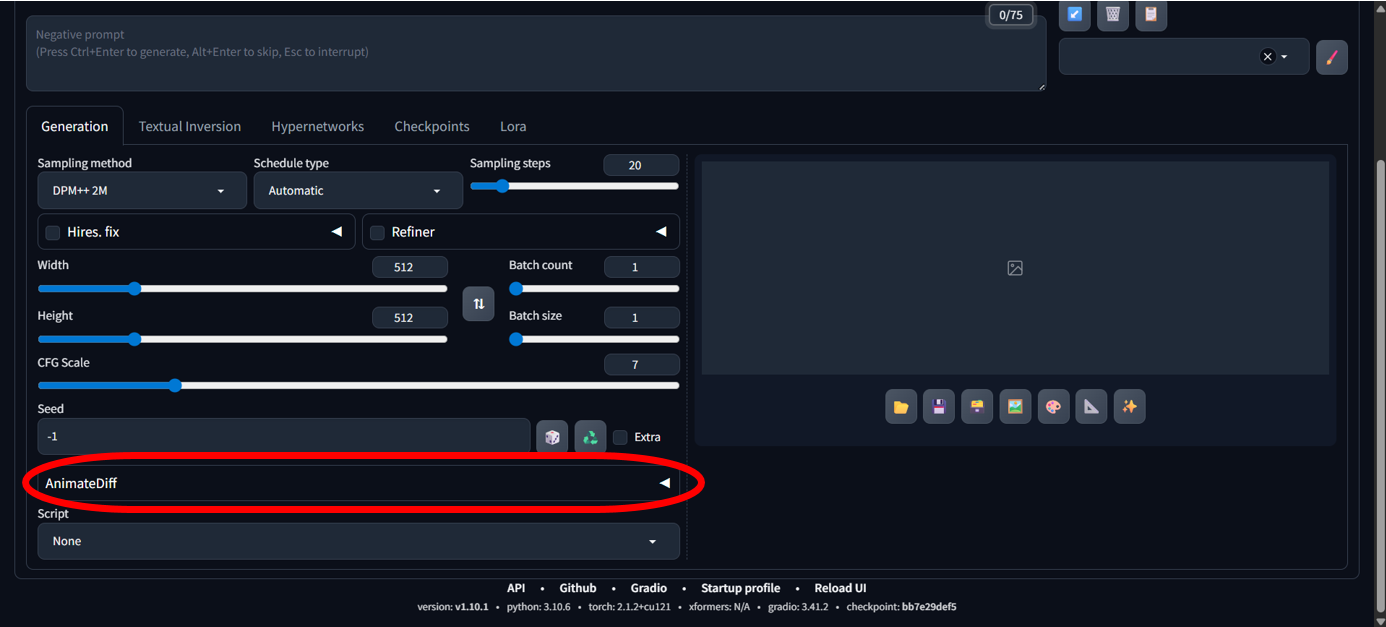 圖7 AnimateDiff欄位位置。
圖7 AnimateDiff欄位位置。
出現AnimateDiff欄位後,接著下載並放置Motion Module。先到Hugging Face下載所需的motion module檔案,例如mm_sd_v15_v2.ckpt。接著,把檔案放到extension指定的資料夾「stable-diffusion-webui/extensions/sd-webui-animatediff/model/」內(或依extension的Settings指定的路徑)。最後,重啟WebUI(若extension已載入,可能需要在設定頁按refresh/reload models)。
此時,就可開始進行影片的生成。首先,在Prompt欄位內輸入想要呈現的畫面及動作,可輸入想要呈現或加強的細節,例如細緻的臉部(Detailed Face)。接著,在Negavite Prompt欄位內輸入不想出現在畫面中的元素,例如多餘的眼睛(Extra Eyes)。若是像小周這樣第一次接觸AI生成影片的初學者,可以下載其他作者已訓練完成的模型檔,並從Civitai網站複製範例的Prompt(圖8)。
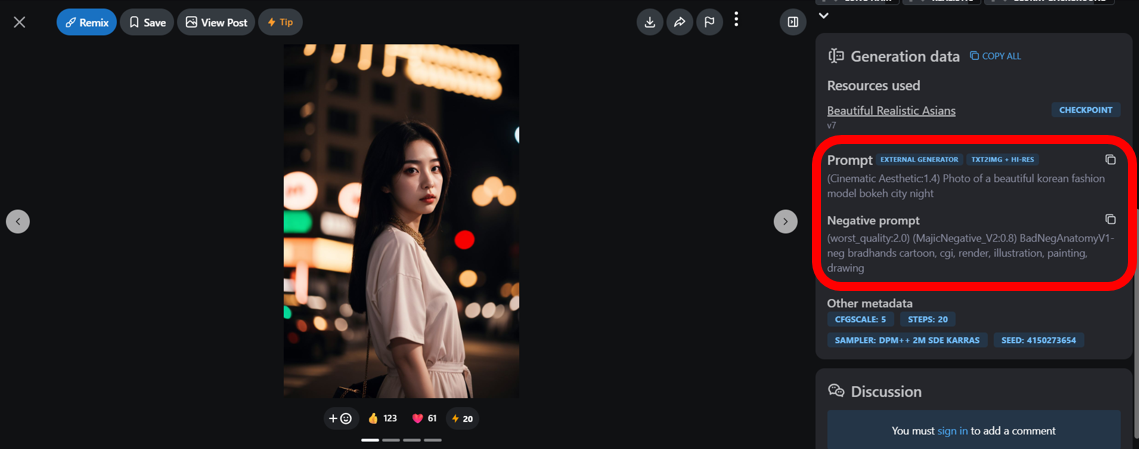 圖8 Civitai網站提示詞範例。
圖8 Civitai網站提示詞範例。
輸入完提示詞後,可以依照自己所需的影片時間、解析度等,進行參數的微調。圖9顯示的是在WebUI中使用AnimateDiff生成影片時會用到的主要設定。以下整理出使用時最需要注意、最會影響影片品質與動作連貫性的參數:
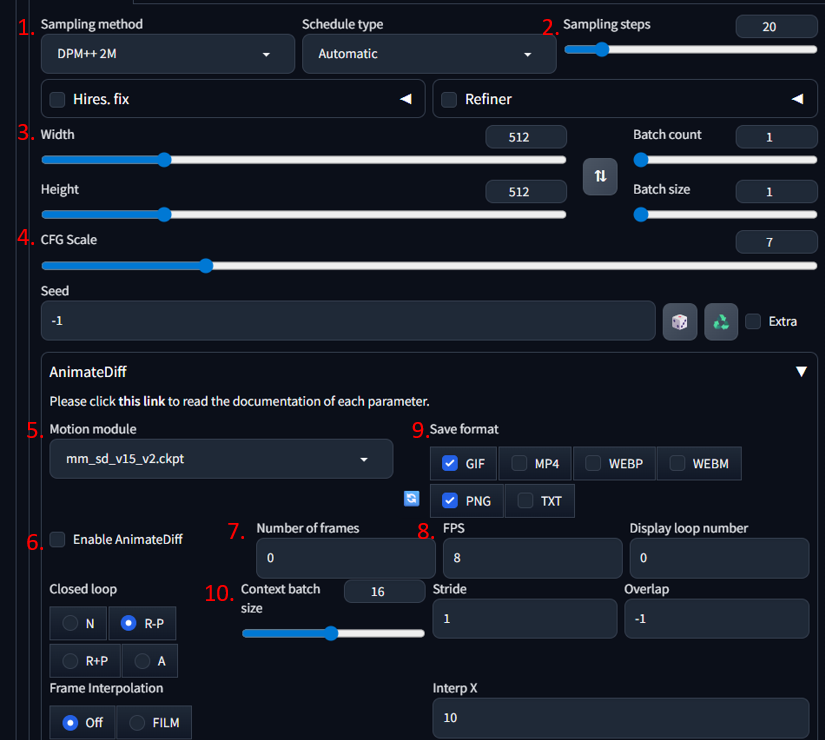 圖9 Stable Diffusion WebUI各項參數介紹。
圖9 Stable Diffusion WebUI各項參數介紹。
‧Sampling method(採樣方式):決定模型如何「去除雜訊、重建影像」,例如DPM++ 2M。使用越高級的採樣器,畫面越乾淨細緻,但速度較慢。
‧Sampling steps(採樣步數):AI生成影像時迭代的次數,例如20。步數越高,畫面越細緻、錯誤更少,步數太低,容易模糊或出現奇怪細節,一般影片建議設為15~30。
‧Width/Height(解析度):決定影格的大小,例如512×512。解析度越大,畫面更清晰,但對顯示卡負擔越重。
‧CFG Scale(提示詞強度):決定模型「服從Prompt的程度」,例如7。越高越符合提示詞,但畫面可能不自然。設定越低,讓模型生成的自由度越高,但可能偏離Prompt,建議範圍為5~9。
‧Motion module(運動模組):這是AnimateDiff的核心,用來「讓畫面動起來」,例如mm_sd_v15_v2.ckpt。不同模組會影響影片的動作流暢度與風格。
‧Enable AnimateDiff(啟用動畫生成):打勾後才會使用AnimateDiff生成影片,而非靜態圖片。
‧Number of frames(影格數):最重要的參數之一,決定影片長度,例如16 frames(搭配8FPS ≈ 2秒)、32 frames(約4秒)。影格越多影片越長,但顯示卡負擔越高。
‧FPS(每秒影格數):影片的流暢度。例如8 FPS(動畫風、跳格)、12~16FPS(較自然)、24 FPS(電影感,但需要更多影格)。
‧Save format(輸出格式):支援GIF(輕量、網頁用)、MP4(最清晰、最常用)、PNG(逐影格匯出)、TXT(Debug用)。一般建議選GIF + MP4 + PNG(影片+靜態影格)
‧Context Batch Size(關聯批次大小):這會影響「時間一致性」(避免角色閃爍與變形),例如16。數字越大,影片越穩定,但耗VRAM。
調整好參數後,按下Generate,便可產生逼真的影片,如圖10所示。
 圖10 透過Stable diffusion產生的影片。
圖10 透過Stable diffusion產生的影片。
結語
理解AI影片生成模型的原理不再只是技術興趣,而是每位使用者、企業與平台必備的防護知識。唯有透過技術透明化、充裕的使用者教育過程、AI內容辨識工具、平台審查與法律制度共同配合,才能在享受AI帶來的便利與創意的同時,降低受到深偽攻擊與資訊操弄的風險。
<本文作者:社團法人台灣E化資安分析管理協會(ESAM, https://www.esam.io/)中央警察大學資訊密碼暨建構實驗室 & 情資安全與鑑識科學實驗室(ICCL and SECFORENSICS)1998年成立,目前由王旭正教授領軍,並致力於資訊安全、情資安全與鑑識科學,資料隱藏與資料快速搜尋之研究,以為人們於網際網路(Internet)世界探索的安全保障(https://hera.secforensics.org/)。>