本文將探討文字生成圖像技術,說明目前的AI圖像生成技術,並以情境模擬方式來說明並非所有的AI圖像都是沒有破綻。一旦AI圖像被發現破綻時,圖像生成技術是有問題的,且圖像真實性有待商榷,甚至當發生著作權爭論時,圖像真實性就必須經得起考驗。
生成式AI影像技術近年來已有顯著的發展,迅速成為人工智慧領域最引人注目的研究方向之一。而且,隨著深度學習和運算能力的提升,生成式AI不僅能夠產生高品質的影像,也能夠在藝術創作、廣告設計、醫學影像等多個領域展現出巨大的應用潛力。這項技術不僅改變了大家對影像生成和處理的理解,也為藝術創作帶來了前所未有的衝擊。
當2014年AlphaGo的誕生對圍棋界所帶來的影響,一般而言,當時的人們一直深信人工智慧技術無法在圍棋的領域中打敗人類。但因AlphaGo成功打破了這項認知,後來甚至還能更進一步不斷地繼續進化技術,當時人們曾想過人類是否在圍棋上已經沒有探究的必要,然而事實上則是AlphaGo為圍棋界帶來了新的思路方向,這也讓想要學習圍棋的棋士們可以利用AI棋譜做為學習的工具,讓自己也能跟著進步。
近年來,生成式AI影像技術變得成熟,也逐漸冒出一種聲音,就是有許多的工作將會被消失。就像是未來畫師們是否將會被AI取代,如同工業革命時代蒸汽機的發明,一度也有人力將被機械取代導致工作機會減少的恐慌,事實上,其結果是產能大幅提升,工人有了新的工作機會。
社會即將面對AI時代的來臨,也許民眾也應該轉念思考,將AI視做一種帶來變革的工具,它雖然帶來衝擊,卻也帶來了新的可能性,如何活用這項新穎的工具為藝術帶來另一種創造性,將會是民眾所能思考的方向。
本文旨在探討這些生成式AI文字生成圖像技術是如何運作,其背後的原理以及如何有技巧地輸入敘述文字(一般稱為Prompt)來生成理想的影像。
除了透過文字生成圖像外,其實這種生成模型也具備其他的能力,像是透過一張概略的草稿圖來生成資訊更豐富的圖像,又或者擷取某影像的局部範圍,加入額外條件後進行影像的修補或生成,其中又以Stable Diffusion Model(穩定擴散模型)這項開源的生成模型最為知名,因為其強大的功能性以及豐富的開源資源讓使用者便於學習,本文將會以Stable Diffusion做為範例說明。
儘管生成式AI影像技術帶來了許多機遇,但同時也伴隨著一些挑戰和倫理問題。例如,產生的圖像可能被用於不當用途,如偽造證據、製造虛假資訊等等。因此,在推動AI技術發展的同時,如何制定和遵守相關的倫理規範,防止技術被濫用,也是國民、企業和政府機關需共同關注的重要議題。
背景知識介紹
以下針對目前AI生成圖像技術與文字生成圖像技術,先做一些簡單的技術描述與技術的優劣性比較。
AI生成影像原理
AI生成圖像技術的發展大概可以從三種面向來探究:變分自編碼器(Variational Autoencoder,VAE)、對抗式生成網路(Generative Adversarial Network,GAN)以及擴散模型(Diffusion Model,DM),而擴散模型是目前最為主流且效果最好的方法。
變分自編碼器是一種典型的生成模型,用於生成新資料,這些新資料類似於訓練集中的資料。如圖1所示,VAE訓練過程可想像成分為編碼器(Encoder)與解碼器(Decoder)兩個部分。編碼器將原始影像轉換成向量型態,解碼器則嘗試將該向量型態還原成原始影像,也是模型訓練完成後主要生成影像的部分。編碼器除了影像像素資訊外,還會包含該影像的文字標記(一般稱為Caption),因此會存在相同Caption中對映出不同影像的情況,因此在大量資料訓練下,Caption在還原影像時會呈現常態分布,用機率性的方式來產出結果。
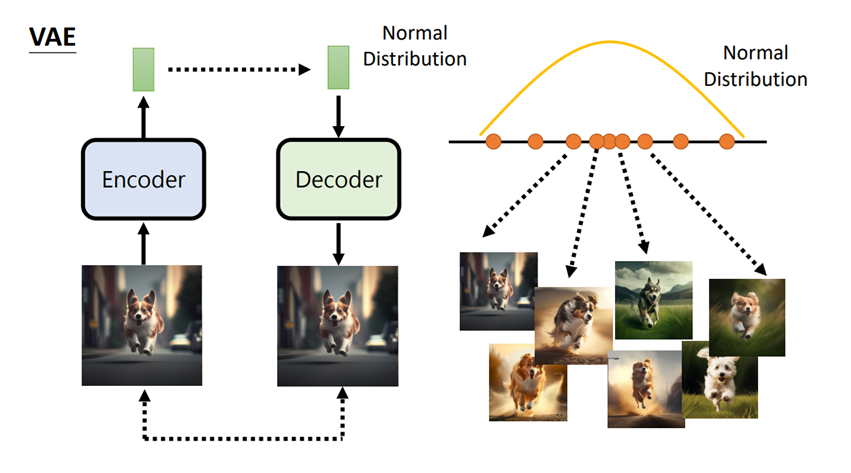 圖1 VAE架構示意圖,參考資料:李宏毅教授-「生成式AI」速覽圖像生成常見模型 https://www.youtube.com/watch?v=z83Edfvgd9g)
圖1 VAE架構示意圖,參考資料:李宏毅教授-「生成式AI」速覽圖像生成常見模型 https://www.youtube.com/watch?v=z83Edfvgd9g)
對抗式生成網路是一種結合對抗與調適的生成模型,由Ian Goodfellow等人於2014年提出,如圖2所示。GAN在AI生成影像的應用可以想像成當訓練好一個解碼器來生成影像後,會需要一個辨識器(Discriminator)去分辨這個生成影像是不是真實的。GAN由生成器(Generator)和辨識器(Discriminator)兩個網路組成。生成器負責生成偽造資料,判別器負責判別資料的真實性。這兩個網路在對抗過程中相互學習與改進,讓生成器能夠生成越來越逼真的資料,也讓直到辨識器無法辨別出生成影像為虛假時,該生成模型就算是訓練完成。
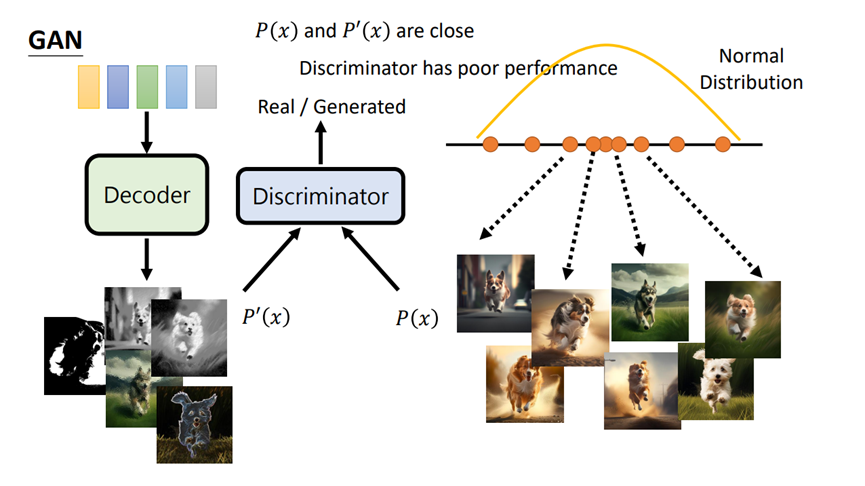 圖2 GAN架構示意圖,參考資料:李宏毅教授-「生成式AI」速覽圖像生成常見模型 https://www.youtube.com/watch?v=z83Edfvgd9g)
圖2 GAN架構示意圖,參考資料:李宏毅教授-「生成式AI」速覽圖像生成常見模型 https://www.youtube.com/watch?v=z83Edfvgd9g)
擴散模型是一種非常嶄新的生成模型,其主要技術是透過一系列漸進的資料變換,將簡單的分布(如高斯雜訊)轉變為訓練資料的分布。如圖3所示,DM在訓練過程可想像成將一原始影像逐步加入雜訊(Noise),一直到整張影像充滿無法辨識的雜訊為止。接著,需要一個解碼器,這個解碼器要做的事就是預測這張具雜訊影像倒數前一步的雜訊可能是什麼樣子,再將那一步的雜訊進行去除(Denoise)動作,也就是說解碼器要逐步地預測倒數加入的雜訊形式後再進行去除,最後就能還原成原始影像,因此DM生成影像的特色是會看到一張充滿雜訊的影像,經過去除雜訊的操作,逐步變成一張清晰的影像。
 圖3 Diffusion Model架構示意圖,參考資料:李宏毅教授-「生成式AI」速覽圖像生成常見模型 https://www.youtube.com/watch?v=z83Edfvgd9g)
圖3 Diffusion Model架構示意圖,參考資料:李宏毅教授-「生成式AI」速覽圖像生成常見模型 https://www.youtube.com/watch?v=z83Edfvgd9g)
對於DM生成模型的概念有一個很美妙的說法,米開朗基羅曾說過他雕刻的形體本來就存在於大理石中,他只是把不需要的部分去除而已,最終必能得到作品。相同的理論,一張充滿雜訊的影像其實也早已藏著某種形體,DM只是透過去雜訊的過程將影像還原。這些模型在圖像生成、圖像修復和超分辨率等任務中表現出色。
穩定擴散模型(SD)
本文以穩定擴散模型(Stable Diffusion,SD)模型為主要參考對象。穩定擴散模型是一種特定的擴散模型,應用於高解析圖像的生成。穩定擴散模型使用逐步去雜訊的方式將簡單的隨機雜訊轉換為逼真的圖像。這些模型通常包括一個訓練好的去雜訊自編碼器(Denoising Autoencoder),在每一步中學習去除雜訊。談到文字生成圖像時,文字敘述自然是很重要的部分,如同下咒語一樣的行為通常稱之為Prompt,以給定Prompt的技巧會以SD為主,但大致上概念都能使用於其他的生成模型。
圖4所示為SD的核心架構,可以理解為更進一步改良DM模型的方法,主要是將去雜訊的步驟進行最佳化。傳統DM的方法是針對整張圖像進行去雜訊,這將會耗費大量的運算資源和時間,SD將圖像轉換為潛在向量空間(Latent Space),可想像成將資料做壓縮再處理,之後在潛在向量空間進行去雜訊,再把去雜訊後的向量還原成圖像。得到的結果不但品質不會下降,更重要的是大幅度地減少運算資源和時間。
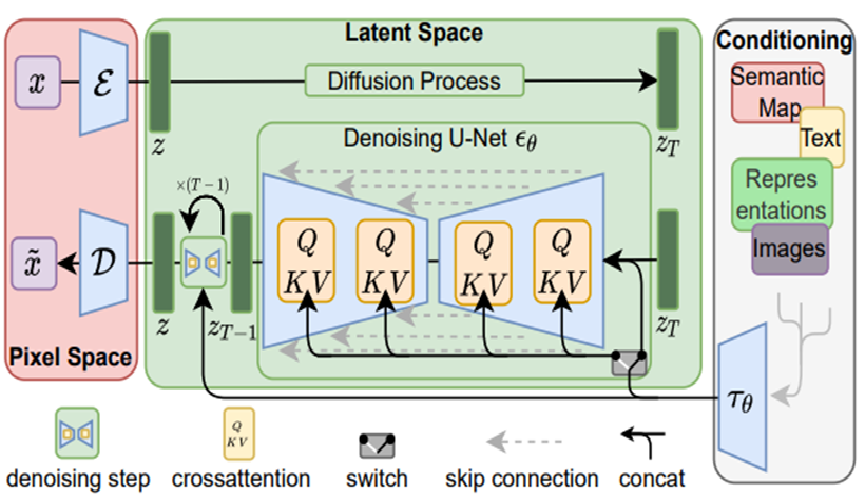 圖4 Stable Diffusion架構示意圖,參考資料:High-Resolution Image Synthesis with Latent Diffusion Models, Rombach et al., CVPR 2022)
圖4 Stable Diffusion架構示意圖,參考資料:High-Resolution Image Synthesis with Latent Diffusion Models, Rombach et al., CVPR 2022)
一般在設定Prompt時,可分為主體(Body)和細節(Detail),然後可以再賦予該影像某種風格(Style)。所謂的主體即描述該影像存在哪些物件和背景;而細節可以拿來補充描述該物件的狀態或背景屬性;風格則是影響整體影像的呈現,可以是真實系的照片,也可能是一幅油畫或是卡通形式。
通常這類生成模型只支援英文輸入,其他語言效果都將會大打折扣,不過關於這點可借助於更加成熟的大型語言模型來輔助產生Prompt咒語。例如,假設想產生一個「一隻快樂的在月球漫步的哈士奇」,以真實照片形式,透過ChatGPT-4o可翻譯成「A realistic photo of a husky happily walking on the moon」。
以上述的AI生成圖像技術與文字生成圖像技術做比較,表1說明了二種不同方法的差異性。
情境模擬
阿哲在網路上看見某個知名企業正在舉辦「鐵道」攝影競賽,參賽作品若能入選將獲得豐富的獎品,甚至通過決選可獲取高額獎金。有高額獎金的誘因,讓阿哲心中燃起躍躍欲試的念頭,只要能取得參賽作品,就有機會能獲獎。但阿哲本身沒有攝影的設備與經驗,於是從網路上找到一張電腦生成的圖像(圖5),阿哲小心翼翼查看圖像的內容,發現圖像中沒有奇怪的地方,就把這張圖像作為參賽作品。
 圖5 阿哲的參賽作品
圖5 阿哲的參賽作品
經過幾周後,阿哲收到主辦單位的通知,告知其作品目前己通過入選的標準。收到通知後,阿哲欣喜雀躍,按照主辦單位的要求,須再提供一些相關的資訊,確認作品的真實性後,作品就進入決選階段。
在決選階段,評審團對於決選作品以高標準的方式來檢視作品內容與真實性。經過進一步確認後,發現阿哲的作品中,有些不合理的區域,如圖6(a)所示,圖像疑似造假情事,評審團更指出不合理的區域有兩個地方。
 圖6 標記圖像造假區域:(a)圖像標記造假區域、(b)造假區域放大顯示-火車、(c)造假區域放大顯示-軌道警示燈。
圖6 標記圖像造假區域:(a)圖像標記造假區域、(b)造假區域放大顯示-火車、(c)造假區域放大顯示-軌道警示燈。
第一,經圖像放大後,如圖6(b)所示,在火車的玻璃處呈現非對稱的效果,例如雨刷和玻璃的分割視角;第二,如圖6(c)所示,軌道的警示燈是用來指揮與警示鐵道上火車的行駛情況,因此警示燈的方向應朝向鐵軌的火車。
有鑑於圖像中有兩處不合理的圖像內容,最終,主辦單位及評審依循競賽作業標準與規範,確保比賽的真實性與公平性,評審團決定取消阿哲的參賽者的資格,並限制阿哲3年內不得再參加知名企業所舉辦的攝影競賽。有此可見,人工智慧對資安的威脅已成為科技在工作與生活裡真假判讀的必要議題之一。
結語
在生成式AI領域當中,文字生成圖像技術正迅速成為科技與藝術創作領域結合的一大亮點。
從本文的討論中可以看到,在最先進的擴散模型(Diffusion Model)應用中展現出了極高的潛力和廣泛的適用性。而Stable Diffusion作為目前最受歡迎的生成模型之一,其強大的功能性和開源性成為使用者學習應用文字生成圖像的首選工具。文字生成圖像技術的核心在於其高度可控性和靈活性,使用者可以透過輸入精確的描述性文字,生成符合特定需求和風格的圖像。
然而,隨著生成式AI技術的不斷進步,倫理和法律問題也日益突顯。生成圖像可能被用於偽造證據、製造虛假資訊等不當用途,另外訓練模型的影像資料來源也可能存在者著作權使用的問題,這對社會帶來了潛在的風險。因此在技術發展的同時,如何制定和遵守相應的倫理規範,防止技術被濫用也是必須重視的課題。
<本文作者:社團法人台灣E化資安分析管理協會(ESAM, https://www.esam.io/)國立嘉義大學多媒體應用實驗室(MALAB)創立於2023年8月,目前由資訊工程學系翁麒耀教授領軍,實驗室的研究領域除了致力於圖像安全、資訊安全與數位影像處理與版權保護外,也涵蓋AI生成式圖像、物件追蹤、醫學影像等研究領域。>