生成式AI的出現導致了更多以假亂真的內容充斥在網路世界中,進而使生成式AI可能變成駭客發動各式攻擊的武器。本文將帶領大家認識神奇的Stable Diffusion技術,並從資安角度檢視這項技術可能為人們生活中帶來的應用與潛在的資安隱患。
人工智慧(AI)是近年來非常火熱的話題,帶來了許多不同的科技應用。其實,AI是一個非常廣泛的概念,只要讓機器做到模擬像是人類做到的事,都可以歸納在廣義的AI當中,然而,在探討到較為細微的AI時,通常將其再分為機器學習與深度學習兩個子領域,主要的概念是經由人類透過非常大量的數據讓電腦進行學習特定任務,讓機器學習與模擬本來只有人類才能做得到的事情,幫助人們解決了大量高重複性的任務而提升效率與增加產能。
但隨著近期的發展趨勢,有一些需要人們的長時間累積的創意與智慧結晶的任務,像是寫作創作、寫歌,甚至是作畫都難不倒AI,而且作品極其逼真,幾乎可與人類作品平分秋色。那麼至今,AI究竟會成為人類的生產力工具呢?還是成為對人們生活以及各大產業造成衝擊的浪潮?
除此之外,在人們不易分辨出真實與虛假的基礎之下,這項技術是否可能落入駭客手中成為發動攻擊的輔助工具?在本文中,將介紹神奇的AI繪圖神器Stable Diffusion,了解AI是如何在繪畫與創作的世界中大展身手,同時以資安的角度切入這項技術可能帶來的濫用與資安隱憂,資訊接收者又該如何辨別真偽,避免淪為新科技之下的受害者。
認識Stable Diffusion與AI繪圖創作
在2022年發表的Stable Diffusion是一項基於AI的影像生成技術,該技術由StabilityAI公司(https://stability.ai)所開發。Stable Diffusion主要功能包含文字生成圖片(txt2img)以及圖片生成圖片(img2img),讓使用者能夠輸入提示詞(Prompt)與負面提示詞(Negative Prompt),AI便能根據使用者所輸入的提示詞內容來產生影像,與透過負面提示詞避免產生出一些非預期的內容,又或者能夠透過一張圖片作為基本參考,讓使用者另外輸入提示詞對其進行調整與客製化。
透過文字來產生影像這件事聽起來非常不可思議,如今卻已成為當今非常熱門且日漸普及的應用,更猶如童話故事般,只要向神燈精靈描述自己的願望與需求,神燈精靈就能如願地實現願望。可以試著猜猜看,在圖1中有哪些是真實照片或是由手工繪製而成,又有哪些圖片是透過Stable Diffusion而產生出來的成品呢?
 圖1 由Stable Diffusion產生的圖片。
圖1 由Stable Diffusion產生的圖片。
事實上,前述所提及的全部圖片都是由Stable Diffusion所產生。透過Stable Diffusion,可以快速地根據使用者的需求來產生圖片,無論是想要真實世界風格的畫作、卡通風格、動畫與漫畫風格的作品都能於短時間製作出來,並且栩栩如生,品質非常細緻,已經不易透過肉眼來分辨哪些是真實圖片,哪些是AI的產物。
AI繪圖在近年來掀起熱潮,無論是Stability AI的Stable Diffusion或是OpenAI的DALL-E,都將在各項產業中帶來各式不同的應用,目前也在不少社群平台中受到廣泛討論。除了Stable Diffusion外,也有許多平台提供AI繪圖的功能,像是Midjourney、Bing、Tersor.art、Civitai以及Microsoft的Copilot等等,為使用者帶來更多的選擇性。
目前大部分的AI繪圖功能已經陸續在不同的平台中登場,或是整合到繪圖與後製軟體中,如Adobe Firefly、DreamStudio等等,但由於透過AI繪圖需要大量的圖形運算資源,因此諸多網站的AI繪圖服務在不付費的情況下都有使用量的限制,同時所產生的作品受限於道德限制與法律規範,避免產生出包含違法、帶有偏見或歧視性等不適當的內容出現。
AI繪圖技術的產業應用
接著,探討AI繪圖技術在產業上的各種應用。
‧遊戲產業:在遊戲產業中,Stable Diffusion等AI繪圖技術可以用來生成虛擬角色樣貌、遊戲中地圖與場景圖或生成其他素材。遊戲開發廠商能夠在更低的成本與更高的效率之下製造高品質且細緻的素材,以提升美術效果與遊戲品質。
‧廣告設計廠商:對於廣告廠商而言,運用Stable Diffusion能夠幫助他們快速進行廣告設計,得以減少設計師進行思考與構圖的時間成本,並能夠藉由Stable Diffusion快速地產生出草稿圖與產生出多種素材,設計師可以再根據草稿圖進行修改與調整,以符合真正的廣告需求。
‧電影和動畫產業:Stable Diffusion除了能夠針對靜態影像進行產生之外,也可以用於製作動畫與特效。在早期,製作數十秒的電影特效就有可能花上電影製作人與動畫師數天、數禮拜甚至數月的時間。利用Stable Diffusion等AI生成技術,就能夠大幅度降低時間成本,並製作出極為逼真與細緻的電影特效。除此之外,透過AI繪圖與生成技術,在未來包括電影場景、角色樣貌、服裝、道具等素材都不須透過實物就能達成,為電影產業帶來巨大的影響,並創造了更多可能性。
‧時尚與服裝產業:透過Stable Diffusion與AI繪圖生成技術,對於購買服裝的顧客能夠更加快速模擬出自己穿上服裝後的模樣,並且在不實際碰到衣物的情況下針對不同種類的服裝進行選擇與試穿;對於設計師而言,可以在更短的時間內產生出新的服裝設計,設計師便能結合自己的智慧結晶進行風格調整,以增加產能。
AI繪圖技術帶來資安隱憂
AI繪圖技術除了替產業帶來相關應用外,卻也潛藏著不少的資安隱憂。
製作DeepFake深度造假內容
運用Stable Diffusion等AI繪圖技術,能夠在短時間內產生出逼真的影像或影片內容,且不易透過人類肉眼進行辨認,因此可能遭到駭客將其應用於製作誤導性的內容。除此之外,這項技術也可能濫用於DeepFake內容的製作,偽造特定對象的身分並從事不適當或違法行為,或是假造其身分並說出從未說過的言論。
著作權的侵犯
由於作品製作的過程中是經由AI自動產生,因此所產生的作品包含一定程度的隨機性,當將這些作品商業使用時,這些作品可能在無意間模仿當今現有的藝術作品,或是非常雷同於某些設計師的作品風格,進而發生侵犯著作權的問題。
加劇社交工程威脅
由於Stable Diffusion或其他AI繪圖技術能夠產生非常逼真且細緻的人物、景物內容,因此惡意使用者或駭客可能利用AI繪圖技術偽造人物或合成場景,讓受害者認為真有其人或煞有其事。在早期,駭客時常透過釣魚郵件、釣魚網站來發動社交工程攻擊,如今攻擊者便有可能透過AI繪圖技術在短時間製作合成的圖片或影片輔助其攻擊行為,進而提升攻擊成功機率。舉例來說,駭客組織可能透過AI繪圖技術生成大量英俊或貌美的人物照片作為社群平台的大頭貼,並加以誘騙其他使用者交出錢財或造成綁架事件。
另外,目前在許多社群媒體如X(前Twitter)、Instagram等各式平台中,已經出現許多以AI生成圖片作為大頭貼,或是將AI人物做為一個虛擬身分在經營的帳號並吸引大批粉絲,甚至能夠販售AI人物寫真來營利經營。據觀察後發現,有諸多使用者因為不了解相關技術,在不知情人物是虛擬的情況下對這些AI繪圖人物獻殷勤或積極追求。
道德與偏見問題
Stable Diffusion等AI繪圖技術的訓練資料來自網路上各式各樣的內容,同時也開放讓使用者透過自訂資料來訓練模型,因此產生的影像中可能會無意間包含偏見或是歧視性內容,所產生出的內容可能會冒犯到部分族群而造成負面影響。
假新聞與假消息的威脅
透過生成式AI製作這些極為逼真的造假文字內容、圖片、影片,在這個時代背景之下已經成為不費吹灰之力之事,使得大量生成式AI的產物充斥網路世界中。當這項技術被應用於造假內容與假消息的散播時,由於人們認知的速度逐漸趕不上科技發展的速度,人們得花上更高的時間成本辨別真實性。生成式AI技術的出現對於一般使用者而言,具備與培養辨認網路世界中內容真假的能力變得更加困難,同時也更加重要。
尤其資訊在網路傳播的速度非常迅速,早期所說的「一傳十、十傳百」可能已成為過去式。在這個每個人只須點點手指就可以把訊息傳遞出去的時代之下,可能已是「一傳百、百傳萬」,又甚至更多。而俗話說「當真相還在穿鞋時,謊言已走遍半個世界」,正呼應了人們在這個時代下可能更不容易接收到準確真實的資訊。
如何辨別AI技術產生的合成內容
在當前的AI繪圖技術中,雖然能夠產生極為逼真的圖片或繪畫,不過若是在產生圖像時沒有妥當配置好參數,或是使用到效果不佳的預訓練模型,就有可能在產生出的結果中出現破綻或是異常之處,而身為科技使用者的我們,就必須培養與具備辨識生成內容的能力,因此能夠藉由一些細節來協助判斷這些內容是否有可能是經由生成式AI所建立的內容,判斷特徵方式與範例如表1與圖2所示。

 圖2 具有明顯異常的AI繪圖作品。
圖2 具有明顯異常的AI繪圖作品。
另外,若不易透過肉眼的方式直接判別是否為AI繪圖的作品,也可以利用AIorNot平台(https://www.aiornot.com/)平台來幫助偵測圖片是否為生成式AI所產生,如圖3所示。因此,當接收到一張不確定是否為生成式AI所產生的圖片時,便可以將圖片上傳至平台來協助判斷。除了偵測生成影像外,AIorNot的平台中也提供偵測生成式的音檔。
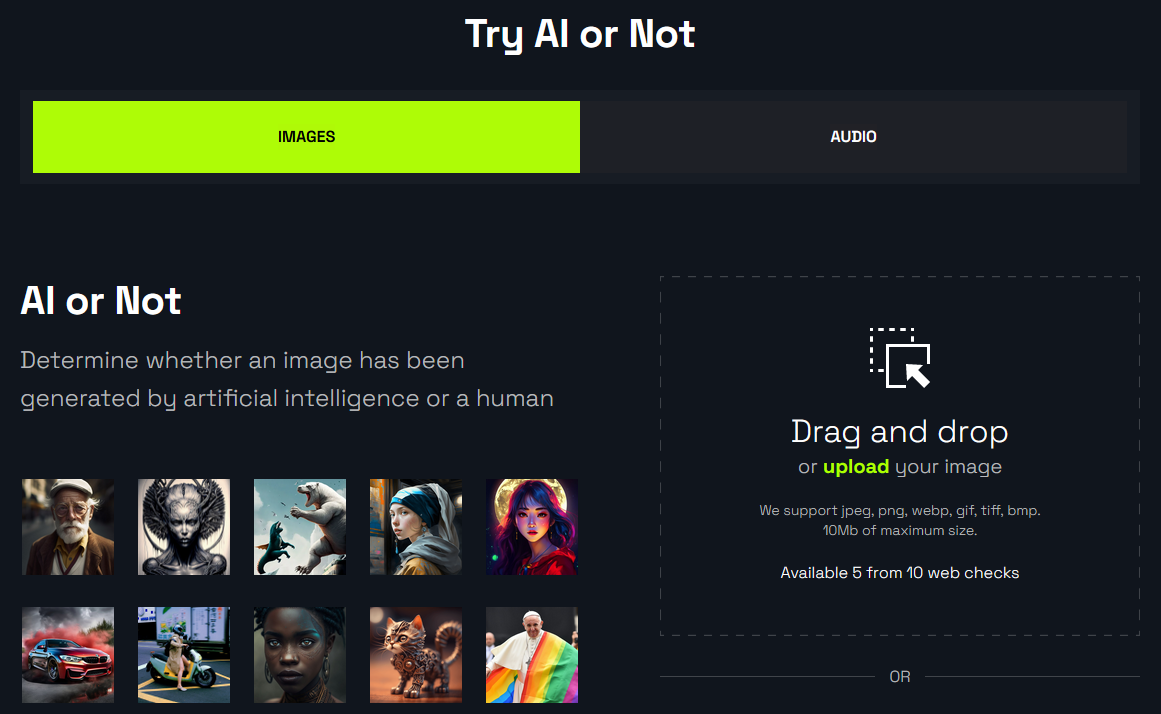 圖3 AIorNot平台。
圖3 AIorNot平台。
使用AIorNot平台時,只須將指定的圖片拖曳至「Drag and drop or upload your image」區塊,即可將本機中的圖片上傳進行判別。在圖3的左側顯示了一些平台所提供的範例AI生成影像來進行測試,測試結果如圖4所示。
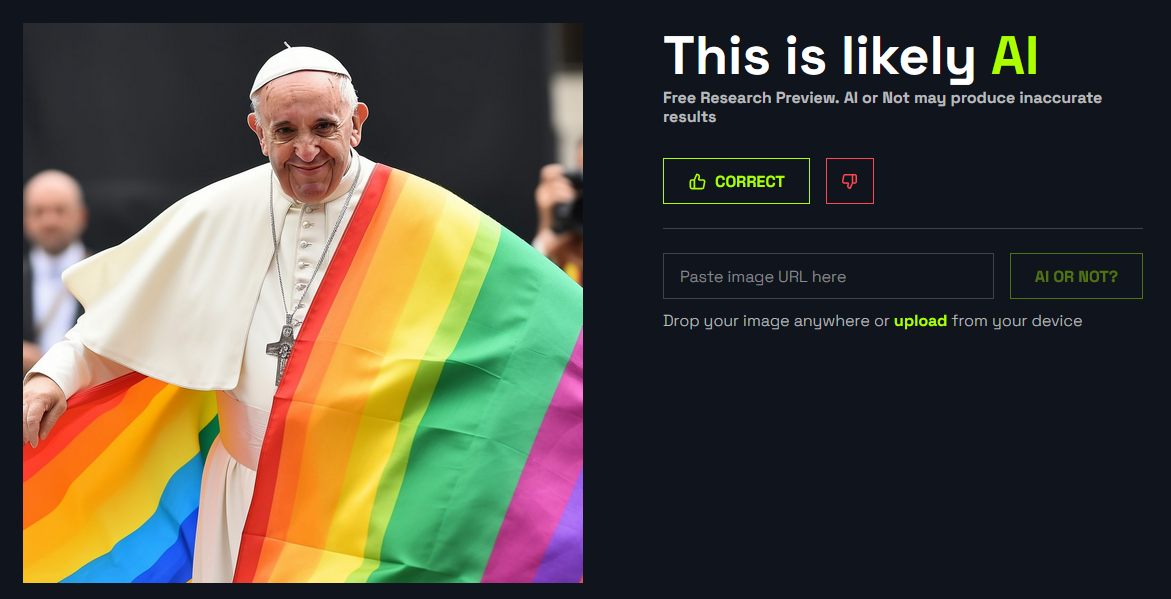 圖4 AIorNot平台檢測結果。
圖4 AIorNot平台檢測結果。
不過,檢測工具也並非百分之百完全準確地偵測出結果,當測試完畢,可以點選「Correct」或是「倒讚」圖示,將偵測結果回饋給平台,以作為平台修正與調整偵測模型的依據。須注意的是,在使用AiorNot平台來檢測時,不建議將包含個人隱私資訊的圖片上傳,以避免洩漏個人的重要資訊。
此外,為了避免AI技術以假亂真造成混淆,全球最大的影音平台YouTube也在2024年3月19日發布新的官方政策,要求影音創作者若發布透過AI產生的作品,必須明確揭露作品由AI製作而成,將影片加上AI內容標籤,否則影片可能遭到下架等其他處置,以遏止AI生成作品的濫用。
AI繪圖的概念與基礎原理
幾乎目前所有的AI繪圖技術都藉由人工智慧中的深度學習技術所達成,但背後運作的原理可能略有不同,而其相同的部分就是都需要非常巨量的資料進行模型訓練,讓機器學習如何產生這些影像。這些基礎大型模型訓練的任務大多數已經由Stability.AI等其他發展AI繪圖技術的機構或組織訓練完成,而目前已有不少的預訓練模型釋出讓一般使用者存取使用。可以基於這些預訓練模型直接運用,也能夠針對各自的需求進行模型的微調(Fine-Tuning),便能在少量資料量的情況下訓練出符合需求的作品,目前在網路平台上也有不少使用者釋出自己的微調模型供大家下載使用,引起熱烈迴響。
在本文中,將針對幾個較為指標性的深度神經網路(Deep Neural Network)架構進行介紹,了解AI繪圖背後的原理以及其機器是如何學習與生成這些影像,以下介紹的神經網路架構包含生成對抗網路(GAN)與擴散模型(Diffusion Model)。
生成對抗網路
生成對抗網路(Generative Adversarial Network,GAN)是一種深度學習的神經網路架構,也是當前許多生成式AI技術應用的基礎。其架構主要由兩個神經網路所組成,包含生成網路(Generator)和鑑別網路(Discriminator)。其名稱來自於這兩個神經網路為彼此互相競爭對抗的關係,其架構如圖5所示。
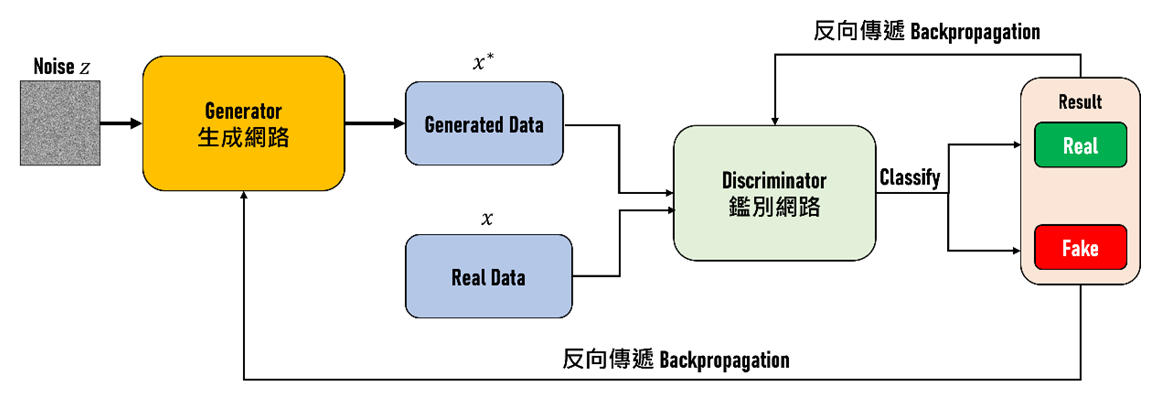 圖5 生成對抗網路架構。
圖5 生成對抗網路架構。
在GAN的架構中,生成網路的任務是將隨機的雜訊進行採樣並輸入至生成網路中,並經由神經網路的權重計算而輸出接近真實資料的結果,接著同時將生成網路產生出的仿真資料與真實資料輸入至鑑別網路中讓其進行判別。在訓練的過程中是由生成網路與鑑別網路互相對抗,透過反向傳播演算法(Backpropagation)將判別結果回饋給生成網路與鑑別網路以調整權重,使生成資料與真實資料能夠愈來愈相近,同時讓鑑別網路也具備辨識真假資料的能力,在經過多輪的訓練與切磋之下,最後就能得到一組具備產生真實資料的生成網路,以及具備判別資料真偽的鑑別網路。
因為這個特性,讓GAN能夠學習如何產生各式不同風格的圖片或是不同的物件,無論是寫實風格的人物、動畫風格的人物、風景圖等等,都可以按照使用者的想法再進行模型微調來滿足需求,目前已有許多開源之預訓練的模型公開釋出,大幅降低了使用者的使用門檻。
擴散模型
擴散模型(Diffusion Model)是有別於GAN的另一種神經網路架構,可將其視為生成式模型的新成員,而本文所介紹的Stable Diffusion就是基於擴散模型技術所達成。擴散模型架構如圖6所示。
 圖6 Diffusion Model擴散模型架構。
圖6 Diffusion Model擴散模型架構。
在擴散模型的訓練過程中,包含正向擴散過程(Forward Diffusion Process)與反向去噪過程(Reverse Denoising Process)。在正向擴散過程中,會將輸入影像不斷地加入高斯雜訊(Gaussian Noise)至影像中,而最終成為一個完全都是雜訊的影像;在反向去噪過程中,則是不斷地對雜訊影像進行去噪(Denoising)的處理,使其逐漸恢復成原始圖片,而神經網路在這邊所扮演的角色就是學習真實圖片與雜訊圖片之間的轉換關係,讓神經網路學習到如何從雜訊中生成這些栩栩如生的圖片。
Stable Diffusion之所以能讓機器理解文字,同時也須透過深度學習領域中的自然語言處理(NLP)技術,將人類的文字內容透過文字編碼器轉換成對應的文字嵌入(Token Embeddings),得以文字轉換成機器能夠理解且可以運算的型態,其利用了由OpenAI所提出的Connecting Text and Images(CLIP)技術,用以關聯文字與圖片之間的關係,也因此才能透過輸入提示詞的方式,讓機器理解文字內容並予以產生相關的圖片,這也是Stable Diffusion的奇妙之處。
情境模擬與實作演練
在認識Stable Diffusion與了解其基本概念後,接著透過情境模擬來實際動手操作Stable Diffusion。在這之前,可以先在自己的設備中準備好以下的相關環境設定。
環境準備
1. Python 3.10(https://www.python.org/)
2. Git(https://git-scm.com/)
3. Stable Diffusion(https://github.com/AUTOMATIC1111/stable-diffusion-webui)
4. 範例預訓練模型
‧基礎模型:https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
‧精煉調整模型:https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main
‧VAE微調模型:https://huggingface.co/stabilityai/sdxl-vae/tree/main
實作演練說明
菲克紐斯(FakerNews)集團是一個惡名昭彰的國際犯罪集團,時常研究和利用最新穎的科技與技術發展出各式不同的手法來欺騙民眾,或是製造假訊息來造成社會動亂。身為調查小組的PONY則深入投入研究菲克紐斯的作惡手法,並決定將這些手法公諸於世,避免造成更多人受害,並藉此提醒民眾們需要多加小心。
PONY提到近年來AI繪圖與合成技術的發展飛快,透過生成式AI能夠在短時間內生成極為真實的照片,而且不易透過人眼直接進行判別,而菲克紐斯集團就是看準了這個特性,而利用Stable Diffusion或其他AI繪圖技術產出這些照片進行濫用。
為了讓大家能夠更加深入了解他們的作惡手法,PONY決定親手展示菲克紐斯集團是如何透過Stable Diffusion技術來產生這些栩栩如生的照片。首先,PONY將相關的軟體環境與預訓練模型進行下載,接著從命令提示字元中輸入以下的git指令,將Stable Diffusion安裝至自己的本機中:
git clone https://github.com/ AUTOMATIC1111/stable-diffusion- webui.git
接著,PONY將剛安裝好的stable-diffusion-webui目錄開啟,針對webui-user.bat文件先透過記事本開啟進行參數配置。若電腦配置的顯示卡記憶體高於8GB,則保持原樣無須其他設定;若小於等於8GB,則在「COMMANDLINE-ARGS=」的參數後面加上「-medvram」或是「-lowvram」,以適配對應的顯示卡記憶體配置,操作如圖7所示。
 圖7 GPU記憶體配置設定。
圖7 GPU記憶體配置設定。
當配置設定完畢,PONY接著將對應的預訓練模型放置到對應的目錄下儲存,得以在啟動系統時順利讀取預訓練的生成模型。首先開啟「stable-diffusion-webui/model」目錄,並按照表2說明將對應的模型類型放置至指定的目錄內。

除了於上述連結提供的模型外,在諸多AI繪圖的網站中提供了許多使用者訓練出的生成模型與微調模型供其他使用者下載,只須按照上述相同步驟放置到指定目錄內便可以使用。
當模型檔案放置完成後,接著PONY開啟webui.bat在本地端啟用Stable Diffusion伺服器,系統就會自動將服務啟動在127.0.0.1:7860,如圖8所示。
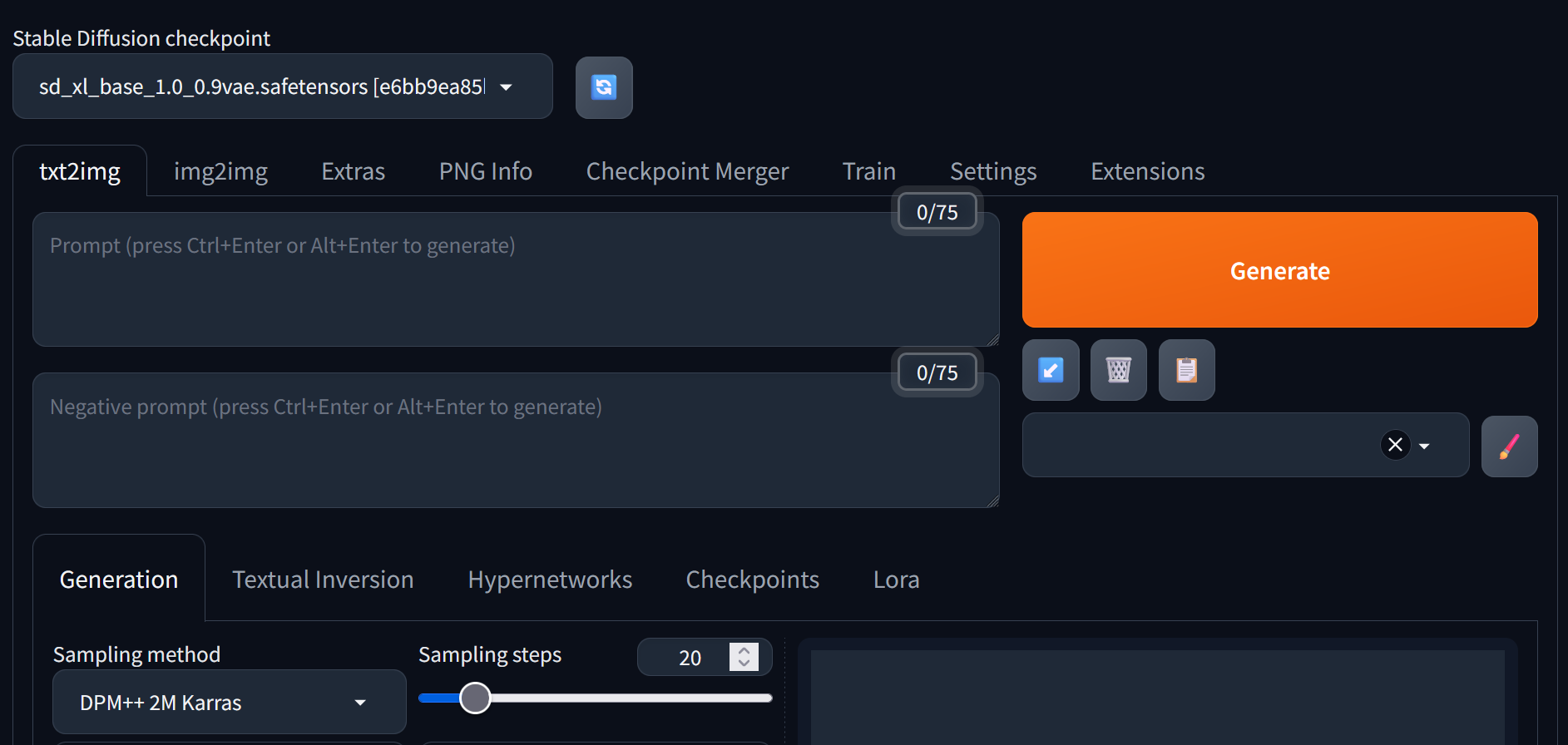 圖8 Stable Diffusion WebUI介面。
圖8 Stable Diffusion WebUI介面。
在Stable Diffusion中,包含了文字生成影像(txt2img)、影像生成影像(img2img)以及模型訓練等其他功能。在操作介面中,主要包含提示詞(Prompt)與負面提示詞(Negative Prompt)的輸入欄位,使用者可以針對想要生成的圖片給予提示詞進行描述,也可透過負面提示詞來避免產生出一些預期之外的成果。
在許多著名的AI繪圖作品平台,如「https://civitai.com/」或「https://tensor.art/」等網站平台中,能夠從中找到「提示詞」的範本,又或者透過ChatGPT或其他語言模型幫助產生提示詞,便能根據這些範本提示詞進行微調,產生出預期的作品。
舉例來說,若想透過Stable Diffusion產生大頭貼相片,可以根據想要的需求下達正向提示詞與負向提示詞,如表3範例所示。PONY在對應的正向提示詞欄位輸入「1girl(一個女孩)、Hair with bangs(有瀏海的髮型)、black long dress(黑色長裙)、portraits(肖像)」,以及在負面提示詞欄位中輸入「low resolution(低解析度)、low quality(低品質)、blurry(模糊的)等其他負面提示詞……」。就如同向阿拉丁神燈許願一般,只需要透過文字內容便能夠引導程式來產生內容。

在相關參數進行設定的部分,包含採樣方法(Sampling Method)、採樣步數(Sampling Steps)、生成圖片尺寸(Size)、提示詞相關性(CFG Scale)、批次數量(Batch count)、隨機種子碼(Seed)、預訓練模型(Checkpoints)等其他設定,其設定如圖9所示,不同的參數設定也將會影響到產生出的圖片成果,參數設定細節可見專案文件(https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki)。
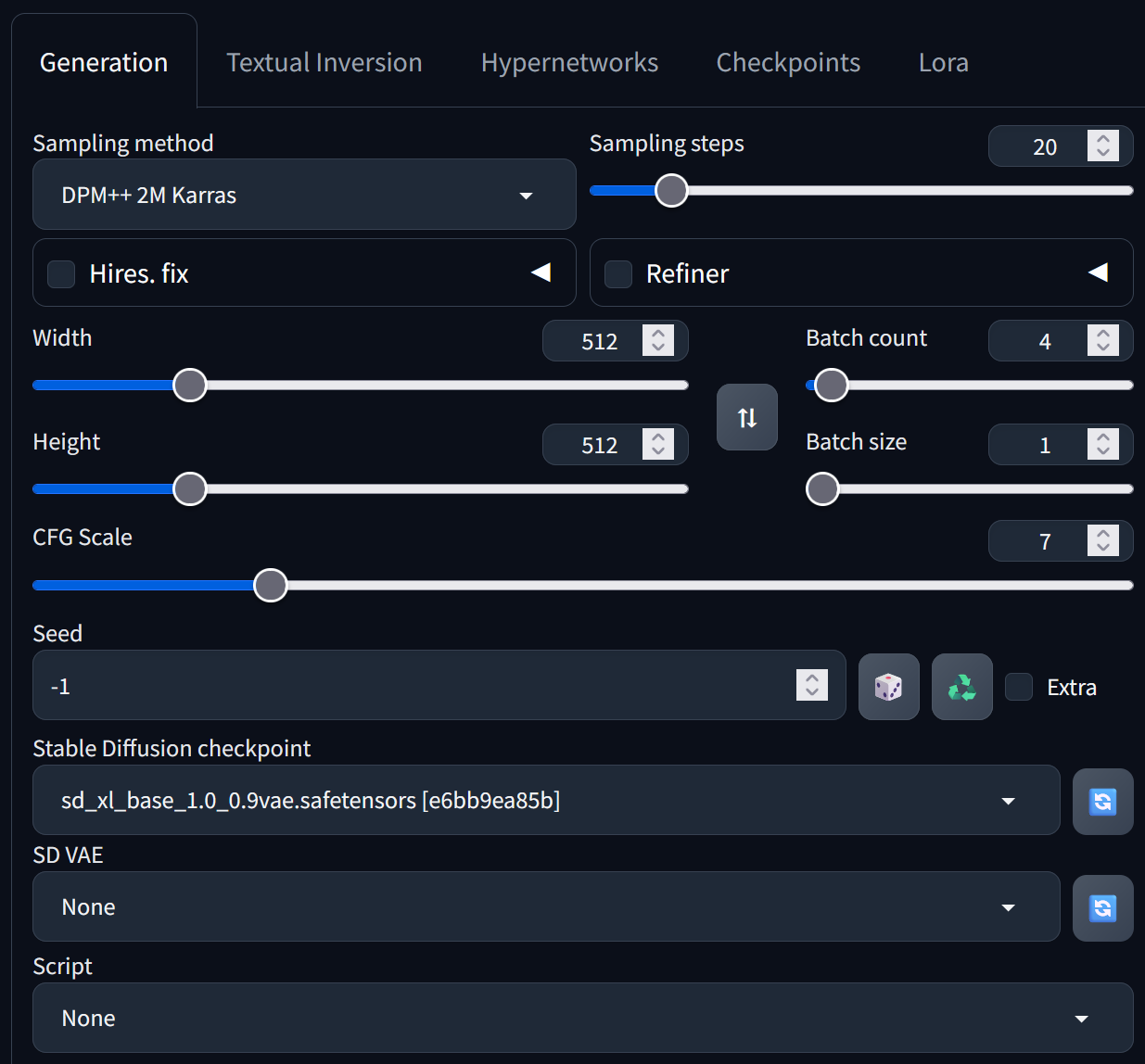 圖9 Stable Diffusion參數設定介面。
圖9 Stable Diffusion參數設定介面。
在相關的參數設定完成後,PONY按下〔Generate〕按鈕便開始產生圖片,不用幾分鐘,栩栩如生的大頭貼就如同向阿拉丁神燈許願般出現,經由Stable Diffusion產生出的圖片如圖10所示。
 圖10 透過Stable Diffusion產生的肖像照。
圖10 透過Stable Diffusion產生的肖像照。
PONY接著說道,菲克紐斯集團時常透過Stable Diffusion來產生貌美或俊帥的大頭貼相片,並套用於大量註冊的假社群帳號來發動社交工程攻擊,有諸多民眾則容易因為對技術不了解,進而與這些假社群帳號進行互動,甚至將自己的錢財、重要隱私與個資都洩露出去。除此之外,菲克紐斯集團更喜歡製作一些造假的網站平台,並在網頁中嵌入包含釣魚連結的橫幅式詐騙廣告,如圖11所示。
 圖11 將Stable Diffusion產出的圖片做為橫幅式詐騙廣告或釣魚連結。
圖11 將Stable Diffusion產出的圖片做為橫幅式詐騙廣告或釣魚連結。
另外,這些透過AI生成的照片也遭到菲克紐斯用於發布假新聞或假訊息,舉例來說,菲克紐斯集團透過Stable Diffusion技術生成一張「正在偷車的鬼祟男子」的監視器畫面,用於栽贓特定人士。除了產生照片之外,他們還能夠利用ChatGPT等其他的大型語言模型(LMM)產生造假的新聞內容,再將這些造假的畫面與新聞內容發布至網路平台中。造假畫面與假新聞網站平台如圖12所示。
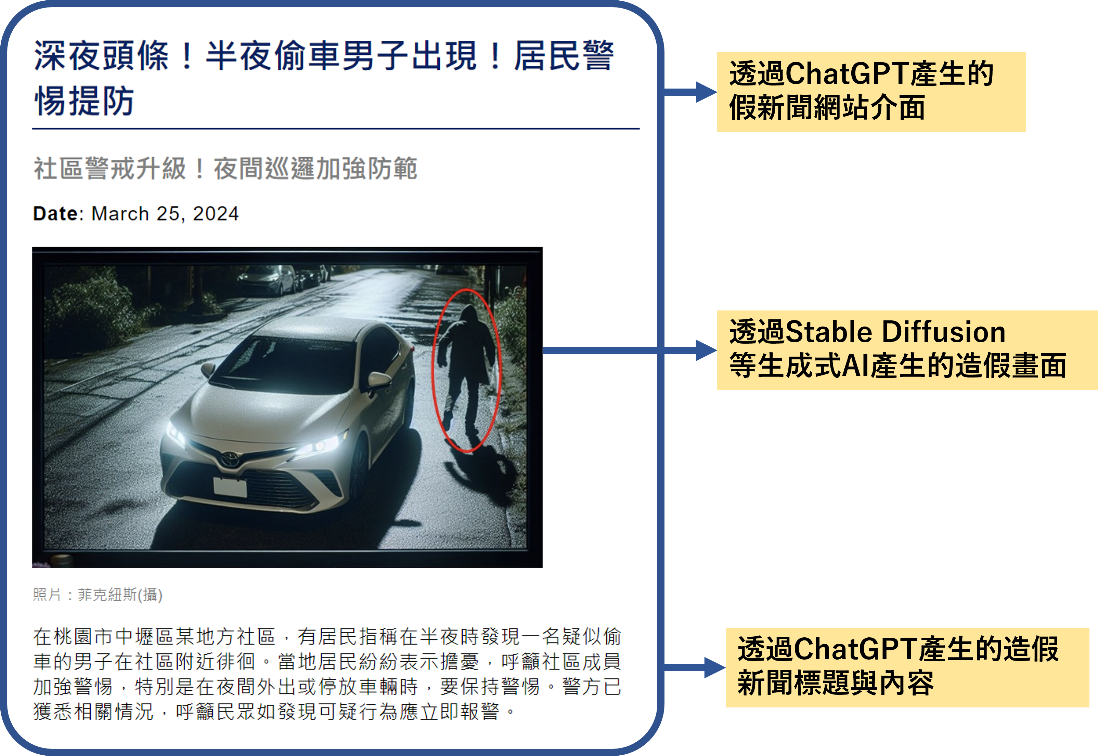 圖12 同時利用Stable Diffusion與ChatGPT產生造假畫面、文案與新聞網頁介面。
圖12 同時利用Stable Diffusion與ChatGPT產生造假畫面、文案與新聞網頁介面。
當這些假新聞被發布時,就很容易經由社群軟體轉傳而散播出去,若一般民眾沒有加以查證,就很可能會因為錯誤造假內容而導致民眾恐慌與人心惶惶,或是延伸出更多的錯誤訊息與謠言,如圖13所示的範例中所提及的陳先生就很有可能被誤認為可疑人士,並且影響附近鄰居對陳先生的觀感。
在識破菲克紐斯集團的伎倆之後,PONY與調查小組的成員們也在不久的時間後逮捕到集團首腦,並且將他們繩之以法。
此事件帶來資安與人工智慧結合的憂患∕認知意識,在未來的網路世界上,將會充斥著更多生成式AI的產物,網際網路的使用者更需要具備辨識真偽的能力,也須善用一些判別工具來協助辨識這些生成的內容,以避免遭到誤導而成為受害者。同時,當接收到這類有疑慮的圖片與資訊內容時,必須養成查證的習慣,並且不隨意轉傳,以避免讓有心人士的如意算盤得逞,而造成更多人受害。
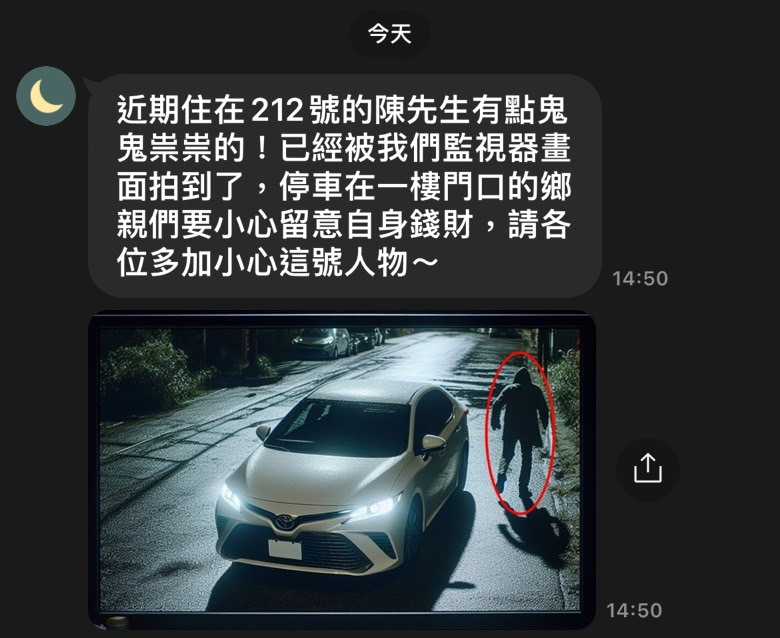 圖13 經轉傳的假訊息可能造成特定對象的名譽受損。
圖13 經轉傳的假訊息可能造成特定對象的名譽受損。
結語
資訊科技的發展為人們解決了許多生活中會碰到的問題,也在許多方面上為人們的生活提升了便利性,但伴隨其來的隱憂是需要去解決的,更必須有一些適當的配套來確保新科技的正面發展與避免其遭到濫用。本文從資安的角度檢視新科技可能帶來的資安隱憂,並透過一些鑑定工具來辨識AI生成內容的真假性,得以強化自我防護意識與因應機制。
<本文作者:社團法人台灣E化資安分析管理協會(ESAM, https://www.esam.io/)中央警察大學資訊密碼暨建構實驗室 & 情資安全與鑑識科學實驗室(ICCL & CFORENSICS)1998年12月成立,目前由王旭正教授領軍,並致力於資訊安全、情資安全與鑑識科學、資料隱藏與資料快速搜尋之研究,以為人們於網際網路(Internet)世界探索的安全保障(https://hera.secforensics.org)>