全新打造的vSphere 7基礎架構,有了許多不同以往的亮眼新功能,不僅僅能夠幫助企業和組織加速前往DevOps的步調,在管理方面還可以同時滿足Dev開發人員和Ops維運人員的需求。本文將深入剖析諸多革新之處,並進行實作演練。
醞釀已久的全新vSphere 7解決方案,終於在2020年3月10日由VMware官方正式發佈,同時VMware CEO Pat Gelsinger更在線上會議中表示,全新推出的vSphere 7擁抱並且內建Kubernetes。因此,管理人員無須再費心要如何建構Kubernetes叢集和高可用性環境,因為vSphere 7即可直接部署和管理Kubernetes叢集。

簡單來說,當企業組織採用vSphere 7建構虛擬化基礎架構時,便能同時打造具備VM虛擬主機和Kubernetes叢集的高可用性環境,如圖1所示,因為在vSphere 7當中已經將Kubernetes API直接原生整合至vSphere API內,幫助企業內的Dev開發人員透過Kubernetes API部署和管理容器,而Ops管理人員仍然可以採用過去管理VM虛擬主機的方式,來直接管理Kubernetes叢集和容器。
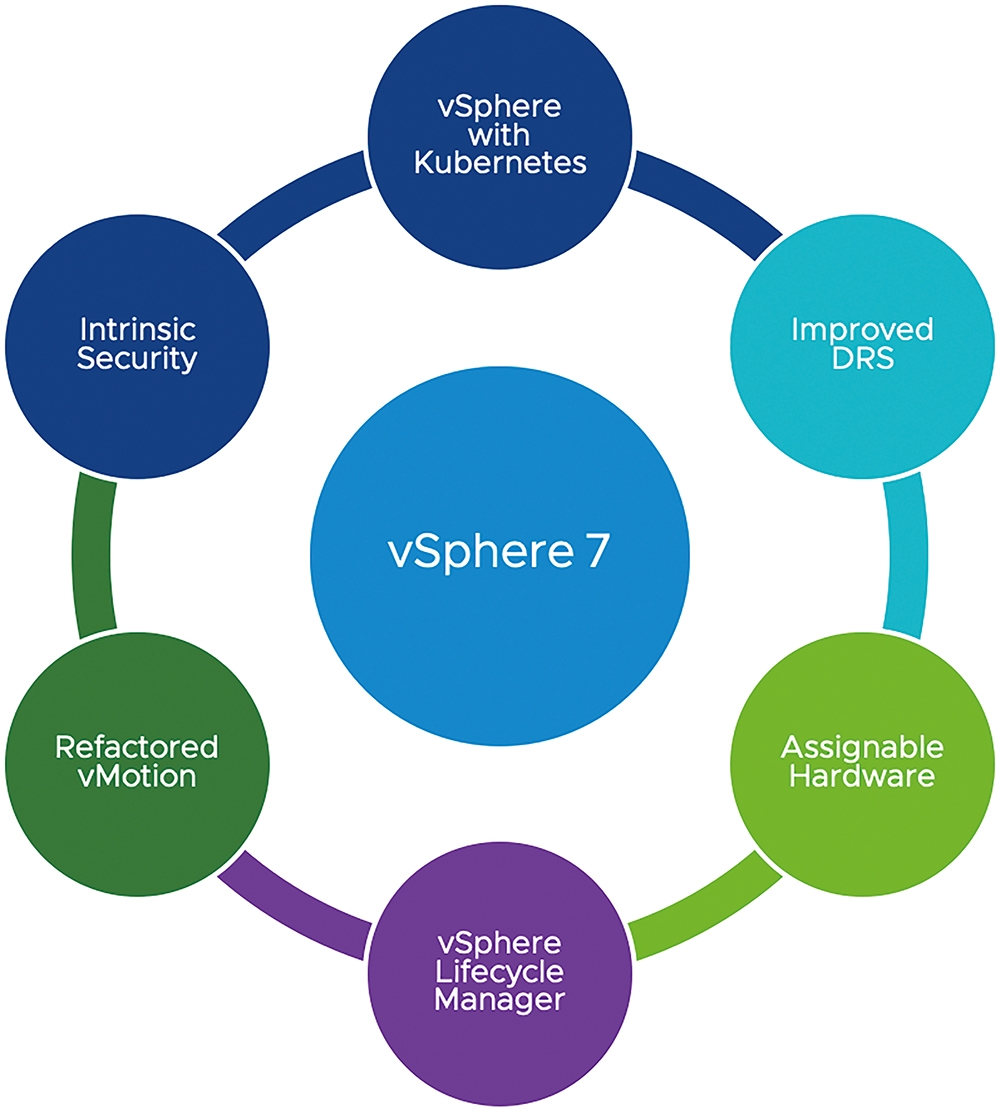 圖1 vSphere 7新增亮眼特色功能示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
圖1 vSphere 7新增亮眼特色功能示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
vSphere 7亮眼特色功能介紹
相較於前一個版本,vSphere 7的改進之處頗多,以下就來說明其中五項亮眼的新增功能。
vSphere整合並內建Kubernetes
過去的vSphere解決方案,對於管理人員說,是圍繞在以VM虛擬主機工作負載為中心,透過vCenter Server管理平台調度運作於ESXi虛擬化平台中不同工作任務與屬性的VM虛擬主機資源,確保營運服務高可用性。然而,新興的應用模式已經改為以「容器」(Container)為主,並且搭配大勢所趨的Kubernetes容器調度管理平台。
雖然傳統的vSphere基礎架構也支援運作各種Kubernetes解決方案和容器等工作負載,但是企業原有的Ops營運團隊和管理工具,卻無法妥善且快速地處理各種容器應用上的疑難雜症。而全新打造的vSphere 7除了將Kubernetes內建之外,更將vSphere 7建構成能夠承載及調度任何工作負載的基礎架構,無論是傳統的VM虛擬主機、HA高可用性機制等等,或是新興的Container、Pod、Namespace、Persistent Volume等等都是如此。
因此,企業組織內的Dev開發人員和Ops管理人員可以在vSphere基礎架構中看到相同的運作環境,並且各自進行管理及部署作業加速協同運作邁向DevOps。舉例來說,Dev開發人員可以採用YAML檔案,透過Kubernetes API管理及調度容器的生命週期,Ops管理人員也能夠採用YAML檔案,透過vSphere API管理和調度VM虛擬主機的生命週期,確保大家採用相同的YAML檔案格式和API進行管理和部署作業。
目前在vSphere 7運作架構中,管理人員可以透過Kubernetes內的「Namespace」機制,同時管理及部署舊有以VM虛擬主機為主的應用程式和服務,以及新興以容器為主的應用程式和服務,如圖2所示。在一個新增的Namespace當中,同時承載傳統應用程式的VM虛擬主機,以及由多台VM虛擬主機組成的資料庫叢集,並且以容器方式運作的現代化應用程式,搭配無伺服器架構的Serverless服務,而管理人員能夠輕鬆針對整個Namespace進行管控,例如硬體資源的使用率、網路資料傳輸安全性、工作負載可用性、機敏資料存取管控等等。
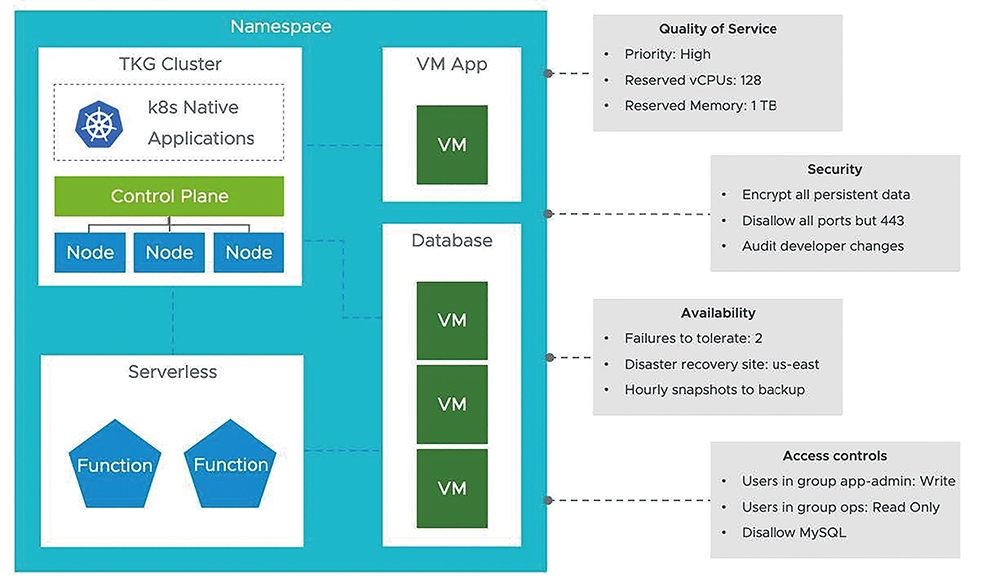 圖2 透過Namespace機制打造以應用程式為中心的示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
圖2 透過Namespace機制打造以應用程式為中心的示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)

DRS自動化調度機制再升級
在傳統的vSphere虛擬化基礎架構中,vSphere DRS(Distributed Resource Scheduler)自動化調度機制,主要用於調度VM虛擬主機工作負載。現在全新推出的vSphere 7基礎架構,不僅運行VM虛擬主機,也同時運作許多Pods和容器,所以VMware針對DRS自動化調度機制進行功能增強,以便最佳化調度VM虛擬主機和容器等工作負載。
過去的vSphere DRS機制是透過「整體叢集標準差模型」(Cluster-wide standard deviation model)機制,針對vSphere叢集中ESXi成員主機之間的工作負載進行資源的負載平衡作業。而現在增強後的vSphere DRS機制,不再將資源負載平衡的重點放在「ESXi成員主機」上,而是將焦點放在「VM虛擬主機」身上,當vSphere叢集啟用vSphere DRS機制後,將會「每分鐘」計算ESXi成員主機上運作的VM虛擬主機得分「VM DRS Score」,如圖3所示,再判斷透過vMotion機制遷移VM虛擬主機後,對於其他VM虛擬主機的影響為何,以達成更細緻更優化的資源使用率。
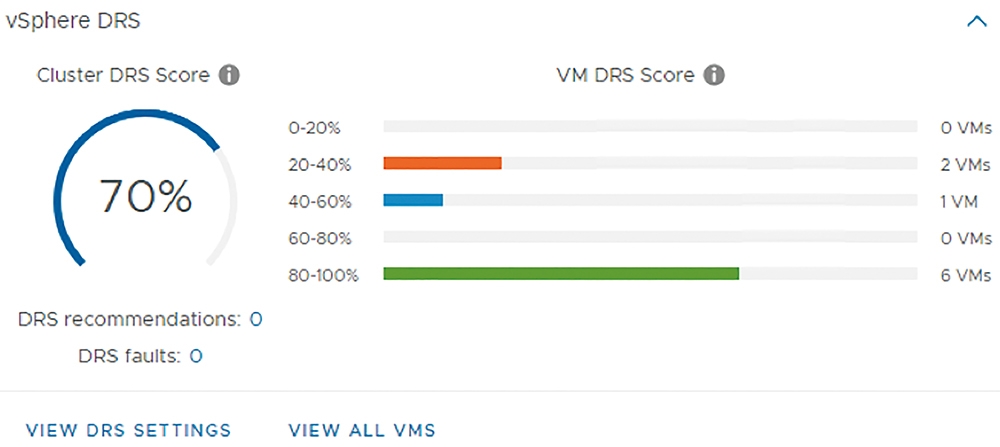 圖3 新版vSphere DRS自動化調度機制示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
圖3 新版vSphere DRS自動化調度機制示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
更彈性的硬體直通機制
在過去的vSphere基礎架構中,當ESXi主機配置支援硬體卸載機制時,可以透過DirectPath I/O硬體直通機制,如圖4所示,指派給VM虛擬主機並寫入.vmx組態設定檔案內以便獲得最佳效能。然而,啟用DirectPath I/O機制的VM虛擬主機,雖然獲得硬體最佳使用效能,但是對於VM虛擬主機的彈性則有所影響,例如無法透過vSphere DRS進行自動化調度,不能夠受到vSphere HA高可用性機制的保護。
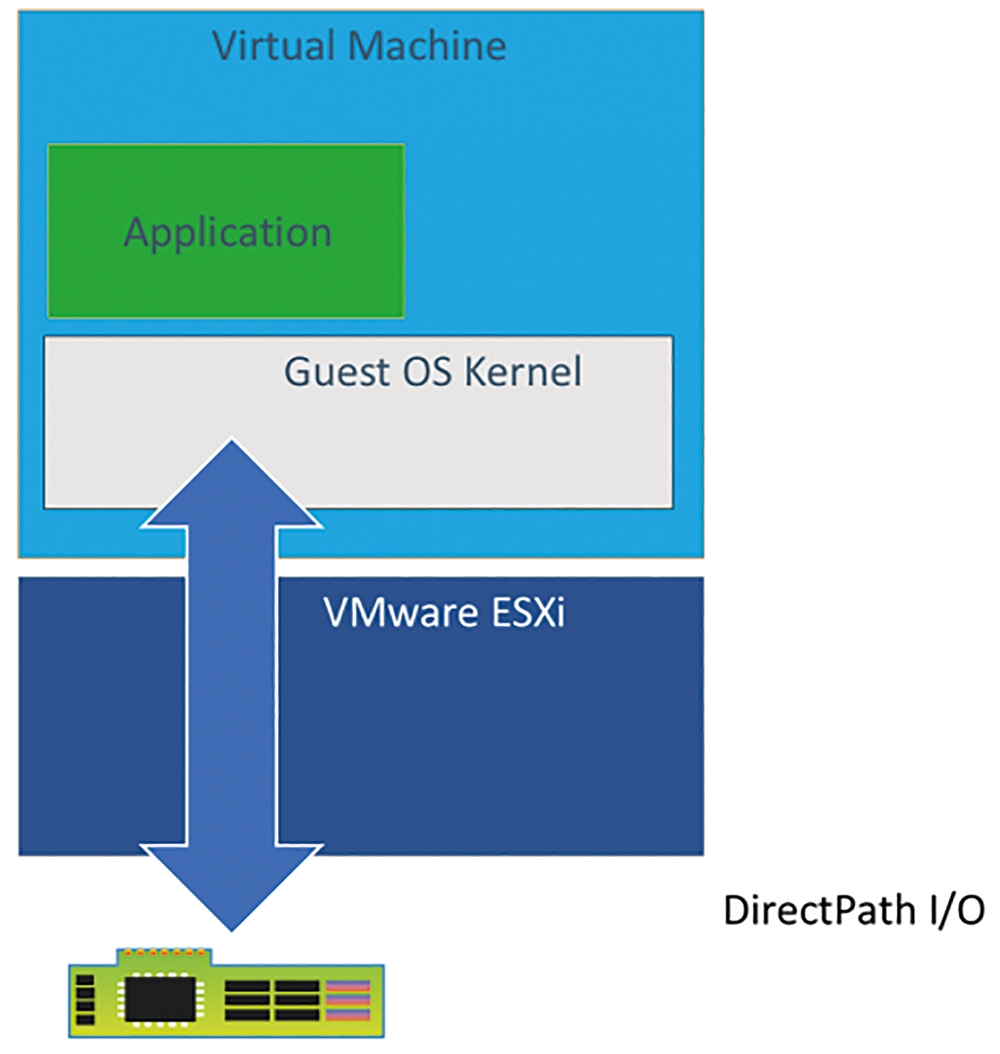 圖4 DirectPath I/O硬體直通機制示意圖。 (圖片來源:VMware Blogs - Using GPUs with Virtual Machines on vSphere - Part 2: VMDirectPath I/O)
圖4 DirectPath I/O硬體直通機制示意圖。 (圖片來源:VMware Blogs - Using GPUs with Virtual Machines on vSphere - Part 2: VMDirectPath I/O)
雖然從vSphere 6.7 Update 1版本開始,支援採用vGPU技術的VM虛擬主機能夠執行vMotion遷移和快照功能,如圖5所示,但仍無法支援vSphere DRS自動化調度機制,以及vSphere HA高可用性機制。
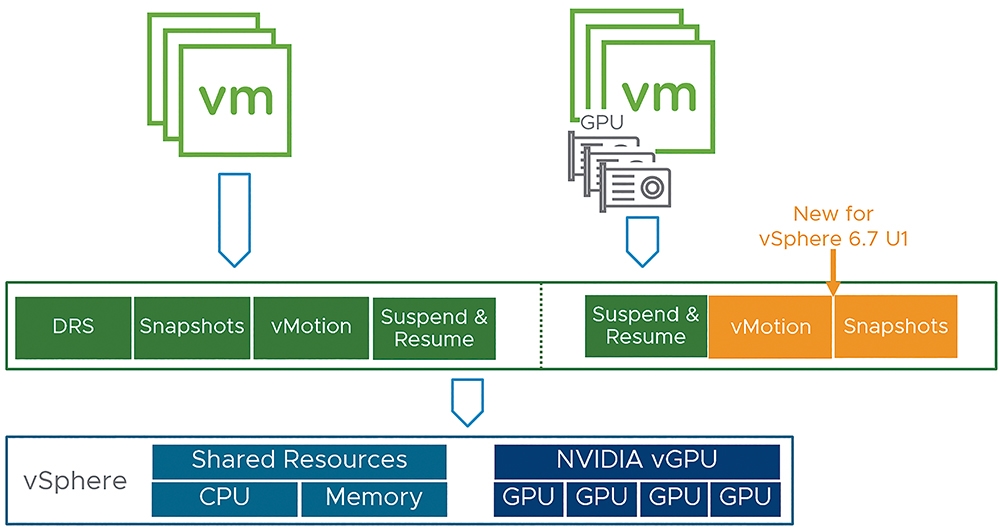 圖5 vSphere 6.7 Update 1版本開始支援vGPU虛擬主機vMotion和快照。 (圖片來源:VMware 繁體中文部落格 - vSphere 6.7 Update 1 新功能)
圖5 vSphere 6.7 Update 1版本開始支援vGPU虛擬主機vMotion和快照。 (圖片來源:VMware 繁體中文部落格 - vSphere 6.7 Update 1 新功能)
全新vSphere 7運作架構中,則採用新式機制稱為「可指派硬體」(Assignable Hardware)。簡單來說,採用新式Dynamic DirectPath I/O機制,不再鎖定只能運作於特定ESXi主機上。例如,在vSphere叢集中共有100台NVIDIA V100 GPU的虛擬主機,當啟用vSphere DRS機制並啟動使用vGPU的VM虛擬主機時,將會自動尋找可提供GPU資源的ESXi成員主機,然後將VM虛擬主機進行註冊並使用的動作,即便ESXi成員主機發生故障觸發vSphere HA高可用性機制,也會自動尋找其他可用GPU資源的ESXi成員主機,將受影響的VM虛擬主機重新啟動並繼續使用vGPU資源。

重構vSphere vMotion即時遷移機制
與前面提到的vSphere DRS調度機制一樣,為了確保vSphere vMotion即時遷移機制能夠更適合新興的應用方式,VMware官方整個重構vSphere vMotion即時遷移機制。
舉例來說,對於SAP HANA和Oracle資料庫這種大型規模的VM虛擬主機,透過傳統的vSphere vMotion即時遷移機制進行搬移,由於大型規模VM虛擬主機龐大的vCPU和記憶體空間,並且「頁面追蹤」(Page Tracing)機制是套用在所有vCPU,如圖6所示,並採用「4KB Pages」小型資料區塊傳輸vRAM虛擬記憶體空間,因此除了容易造成vMotion遷移時間過長的情況,也有可能影響應用程式的運作。
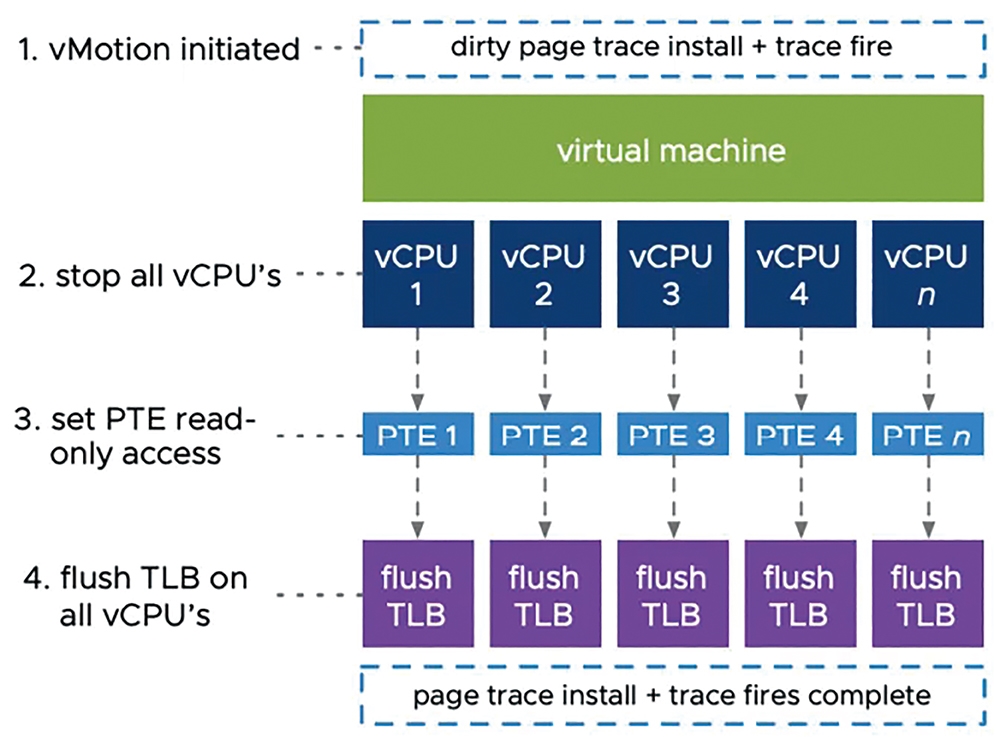 圖6 傳統vSphere vMotion即時遷移頁面追蹤技術示意圖。 (圖片來源:VMware vSphere Youtube – vMotion Improvements in vSphere 7)
圖6 傳統vSphere vMotion即時遷移頁面追蹤技術示意圖。 (圖片來源:VMware vSphere Youtube – vMotion Improvements in vSphere 7)
而全新的vSphere 7運作架構採用了重構後的vSphere vMotion機制,有效解決大型規模VM虛擬主機即時遷移的難題。首先,在vCPU虛擬處理器運算資源遷移的部分採用「專用」(Dedicated)的頁面追蹤機制,確保進行vMotion遷移時不會影響應用程式的運作,如圖7所示。
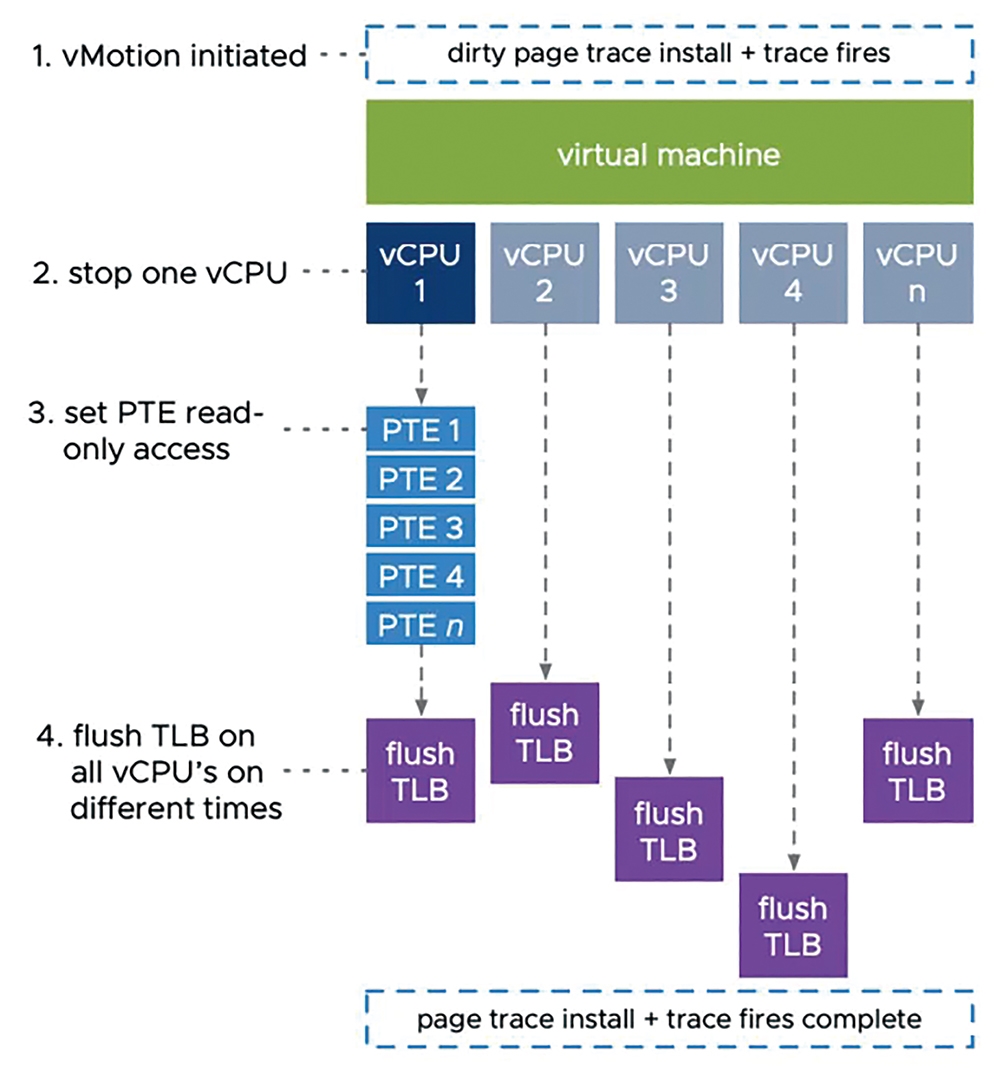 圖7 重構後的vSphere vMotion即時遷移頁面追蹤技術示意圖。 (圖片來源:VMware vSphere Youtube – vMotion Improvements in vSphere 7)
圖7 重構後的vSphere vMotion即時遷移頁面追蹤技術示意圖。 (圖片來源:VMware vSphere Youtube – vMotion Improvements in vSphere 7)
另外,在vRAM虛擬記憶體遷移方面,改為採用「1GB Pages」資料區塊進行傳輸並搭配其他最佳化機制,例如Memory Pre-Copy、Switchover等等。例如,在過去舊版的vSphere環境中,遷移24TB vRAM虛擬記憶體空間需要768MB Bitmap,預計遷移時間需要花費「2秒鐘」,重構後的vSphere vMotion則僅需要「175毫秒」即可完成,如圖8所示,確保大型規模VM虛擬主機切換至不同ESXi主機時,能夠由幾秒鐘的時間縮短至幾毫秒。
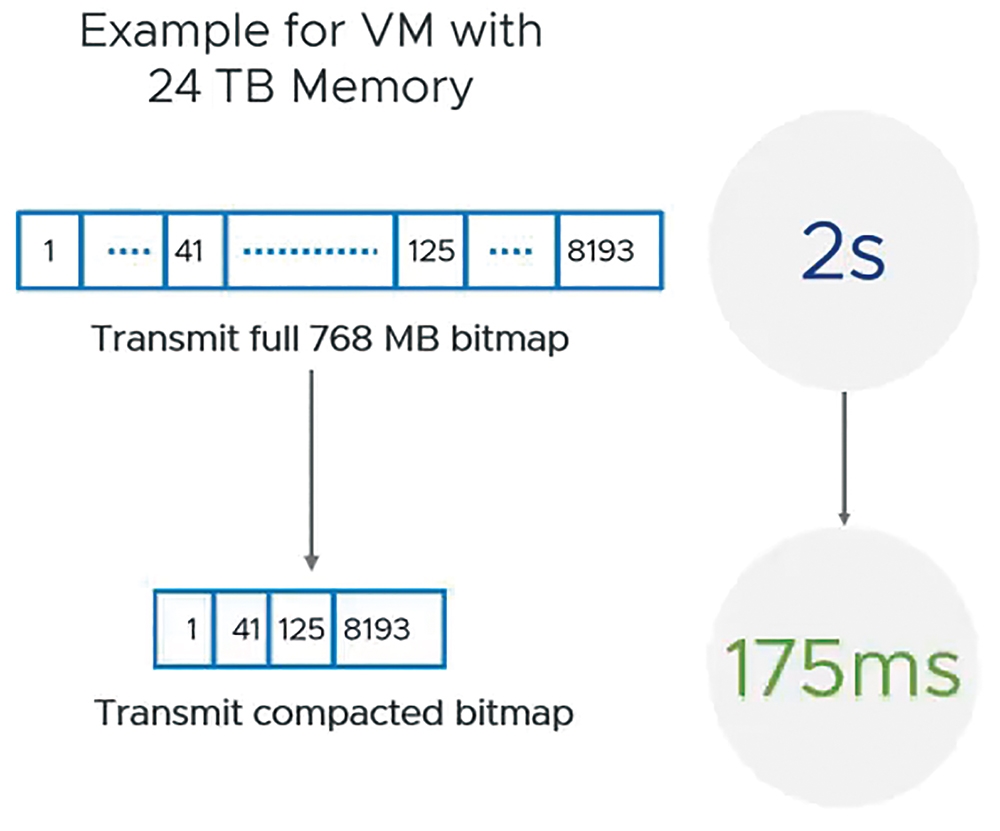 圖8 重構後的vSphere vMotion切換ESXi主機時間由幾秒鐘縮短至幾毫秒。 (圖片來源:VMware vSphere Youtube – vMotion Improvements in vSphere 7)
圖8 重構後的vSphere vMotion切換ESXi主機時間由幾秒鐘縮短至幾毫秒。 (圖片來源:VMware vSphere Youtube – vMotion Improvements in vSphere 7)
在VMware官方測試結果中,採用安裝Oracle資料庫的VM虛擬主機,並配置「72 vCPU和512GB vRAM」大型規模虛擬硬體資源,然後採用傳統vSphere vMotion和重構後的vSphere vMotion遷移Oracle虛擬主機,並在遷移期間透過Hammer DB進行工作負載模擬。簡單來說,重構後的vSphere vMotion除了更快速完成遷移外,在遷移期間Oracle資料庫的Commits數量相較於舊版vMotion也高出許多,如圖9所示。
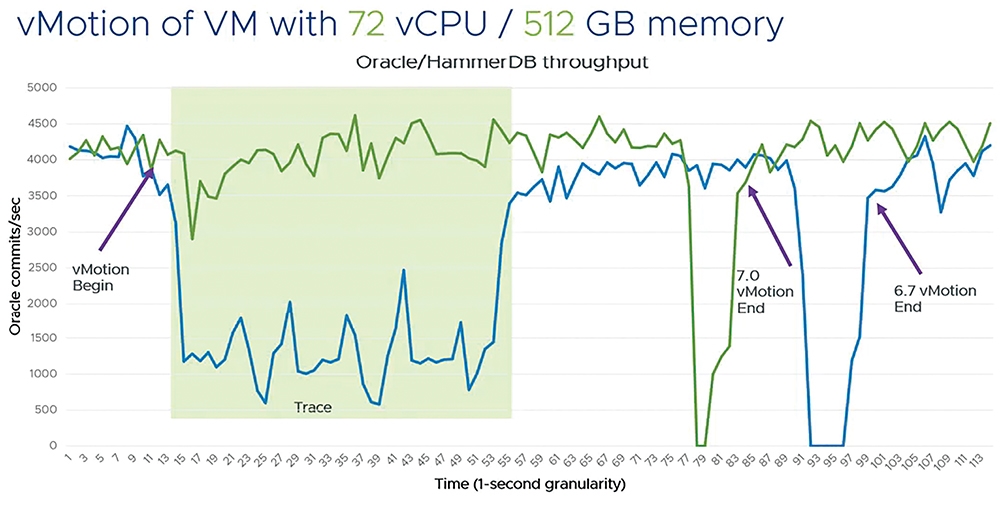 圖9 傳統和重構後的vSphere vMotion遷移大型VM虛擬主機測試結果。 (圖片來源:VMware vSphere Youtube – vMotion Improvements in vSphere 7)
圖9 傳統和重構後的vSphere vMotion遷移大型VM虛擬主機測試結果。 (圖片來源:VMware vSphere Youtube – vMotion Improvements in vSphere 7)
支援多重因素身分驗證機制
對於提升使用者身分驗證機制安全性來說,最簡單的方式就是在良好的密碼原則之外,再搭配「多重因素身分驗證」(MultiFactor Authentication,MFA),但是目前能實作MFA多重因素身分驗證的方法太多,無法將所有MFA實作方式整合至vCenter Server。
因此,VMware針對MFA多重因素身分驗證的解決方案是,支援開放式身分驗證和授權標準,例如OAuth2、OIDC等等。在vSphere 7運作環境中,透過「識別身分同盟」(Identity Federation),如圖10所示,讓vCenter Server管理平台能夠和使用者身分驗證機制供應商進行溝通,達到簡化vSphere管理人員法規審核範圍,同時也支援更多不同的MFA多重因素身分驗證,例如熱門的ADFS(Active Directory Federation Services)。
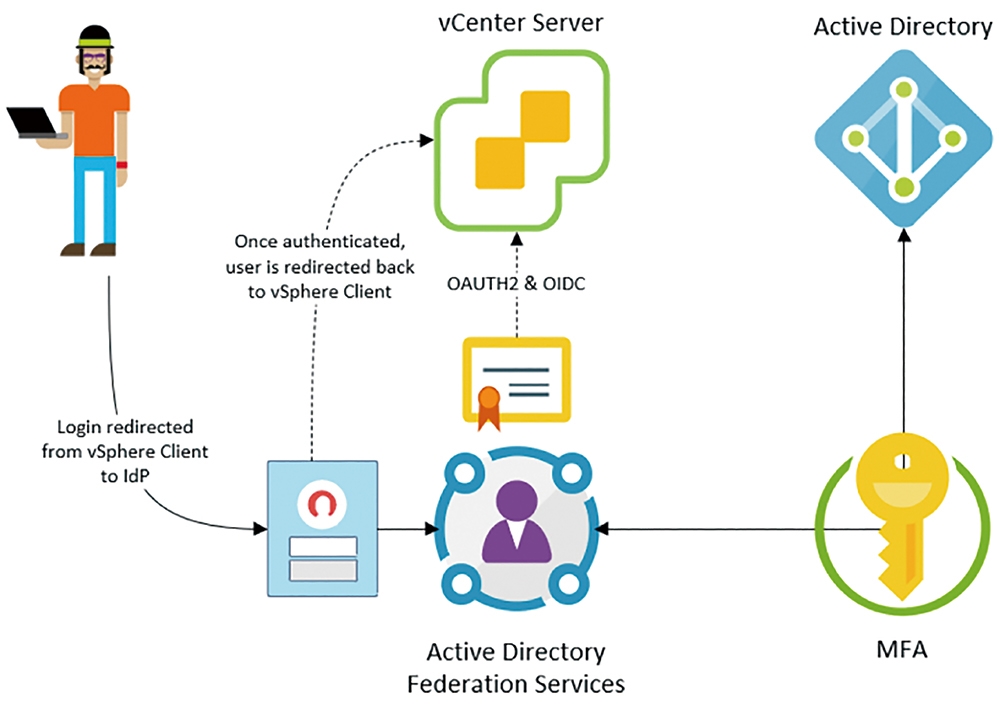 圖10 vCenter Server支援MFA多重因素身分驗證流程示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
圖10 vCenter Server支援MFA多重因素身分驗證流程示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
除此之外,在vSphere 7運作環境中,還新增「vTA(vSphere Trust Authority)」信任授權機制,透過單獨管理的小型vSphere叢集建立硬體式根授權,當ESXi主機底層x86伺服器透過UEFI安全性機制啟動時,搭配「信賴平台模組」(Trusted Platform Module,TPM)進行驗證,確保x86伺服器採用正確且通過驗證程序的軟體,如圖11所示。
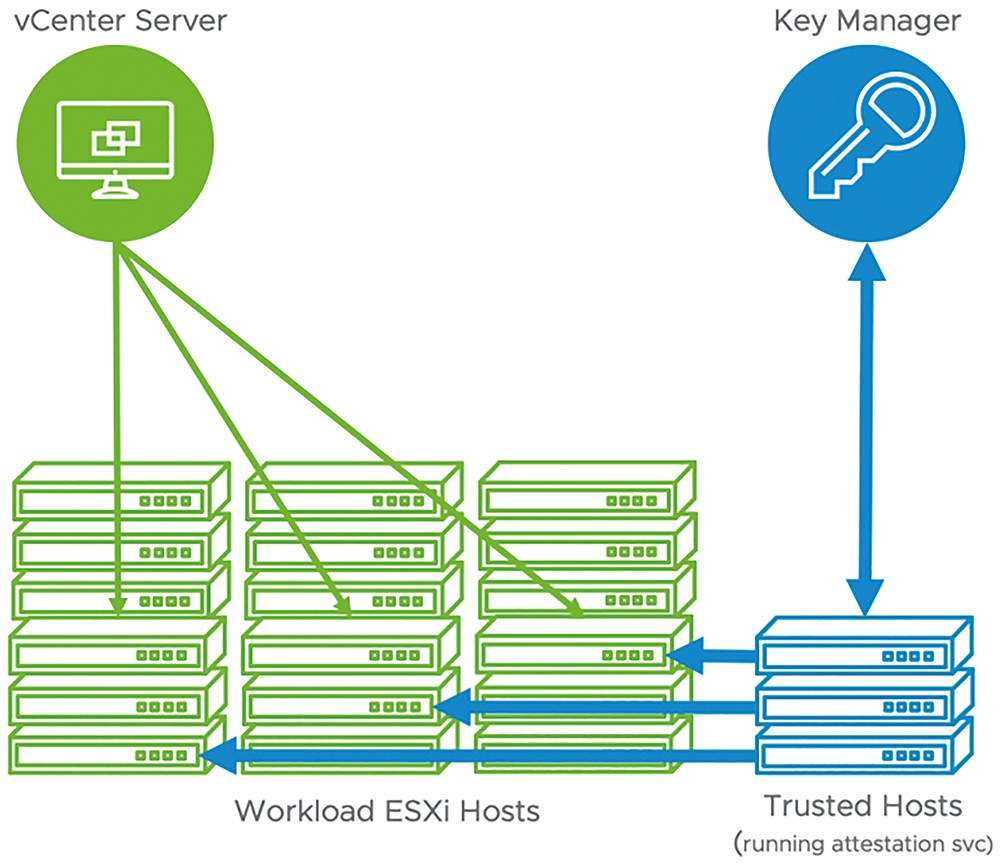 圖11 vTA(vSphere Trust Authority)信任授權機制運作架構示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
圖11 vTA(vSphere Trust Authority)信任授權機制運作架構示意圖。 (圖片來源:VMware vSphere Blog - Introducing vSphere 7: Features & Technology for the Hybrid Cloud)
一旦ESXi虛擬化平台順利啟動後,便能夠運作加密VM虛擬主機,確保VM虛擬主機內的機敏資料不會外洩,並且透過REST API用於從VMCA(VMware Certificate Authority)執行憑證自動續訂的動作,簡化ESXi管理憑證的麻煩。
實作演練vSphere 7 withKubernetes
由於在撰寫本文時官方正式的vSphere ESXi 7.0和vCenter Server 7.0鏡像檔仍未釋出,但是有興趣的Ops管理人員和Dev開發人員仍然可以透過VMware HOL(Hands-on-Labs)進行vSphere 7 with Kubernetes實作演練,如圖12所示。
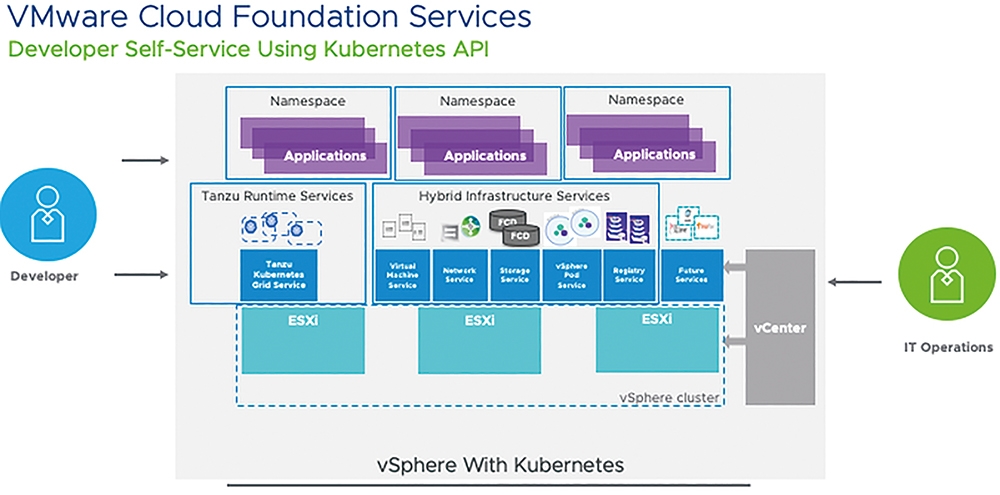 圖12 vSphere with Kubernetes運作架構示意圖。 (圖片來源:VMware Hands-on Labs – vSphere 7 with Kubernetes)
圖12 vSphere with Kubernetes運作架構示意圖。 (圖片來源:VMware Hands-on Labs – vSphere 7 with Kubernetes)

在開始實作演練之前,必須先了解vSphere 7新世代的叢集架構「Supervisor Kubernetes Cluster」,以便後續進行實作時能夠有更深入的體驗。簡單來說,在vSphere 7中的Supervisor Kubernetes叢集,由於已經原生整合至ESXi虛擬化平台中,所以不像傳統由Linux所建構的Kubernetes叢集採用Kubelet指令進行管理作業,而是在ESXi虛擬化平台中除了原有的hostd服務之外,還會常駐「Spherelet」來管理其上運作的Pod和容器。
此外,在Supervisor Kubernetes叢集中,每個在ESXi主機內運作之Pod及Pod內的容器,都會在個別的「CRX虛擬主機」內運作,以便達到不同的Pod和容器的最大隔離性,有效減少運作的容器因為資安問題,而導致ESXi或其他VM虛擬主機直接遭受攻擊。

管理人員可能會有疑惑,採用CRX虛擬主機的方式運作單一Pod和容器的話,那麼每台ESXi主機能夠承載多少台CRX虛擬主機?在VMware官方測試結果中,每台CRX虛擬主機可以在100毫秒內啟動Pod和容器,並且單一ESXi主機能夠運作超過1,000個Pods,而整個Supervisor Kubernetes叢集能夠運作多達8,000個Pods。

對於Supervisor Kubernetes叢集有基本的了解之後,那麼就開始實作演練如何在vSphere 7基礎架構中建立Supervisor Kubernetes叢集運作環境。
部署Supervisor Kubernetes叢集
登入vCenter Server 7管理平台後,在vSphere HTML 5 Client管理介面中,先依序點選「Menu > Workload Platform」,然後在Getting started with Workload Platform頁面中,捲動至最下方並按下〔I'M READY〕按鈕。
此時,系統將彈出Select a Cluster視窗,在列出的傳統vSphere叢集清單中,點選要轉換成新式Supervisor Kubernetes叢集的vSphere叢集。值得注意的是,vSphere叢集必須啟動vSphere HA和vSphere DRS特色功能,才能轉換為新式Supervisor Kubernetes叢集,因此在Compatible頁籤中選擇適合的vSphere叢集後,按下〔OK〕按鈕進入下一個Supervisor Kubernetes叢集組態設定流程,如圖13所示。
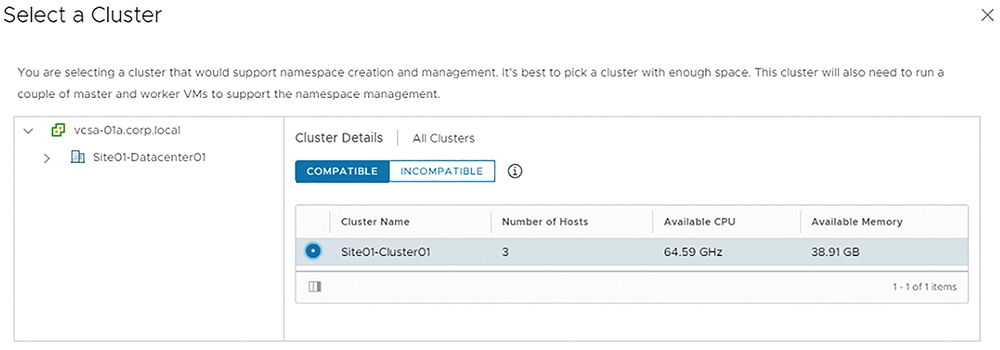 圖13 選擇已啟用vSphere HA和DRS的叢集,轉換為新式Supervisor Kubernetes叢集。
圖13 選擇已啟用vSphere HA和DRS的叢集,轉換為新式Supervisor Kubernetes叢集。
在轉換叢集類型步驟1中,首先選擇屆時Supervisor Kubernetes叢集的運作規模,因為當vSphere叢集轉換為Supervisor Kubernetes叢集之後,除了部署Kubernetes控制平台至叢集之外,還會部署高可用性和多重Master運作架構的etcd和Kubernetes API堆疊,在Supervisor Kubernetes叢集中的每一台ESXi成員主機內,因此確保了屆時可用運作的Pod和容器數量,以及挑選相對應的Supervisor Kubernetes叢集規模大小。
在本次實作環境中,由於是POC概念驗證環境,所以選擇運作規模最小的「Tiny」 Size,預估屆時將會耗損每台ESXi成員主機2 CPU、8GB記憶體、16GB儲存空間等硬體資源,最多可運作1,000個Pods和容器,如圖14所示。
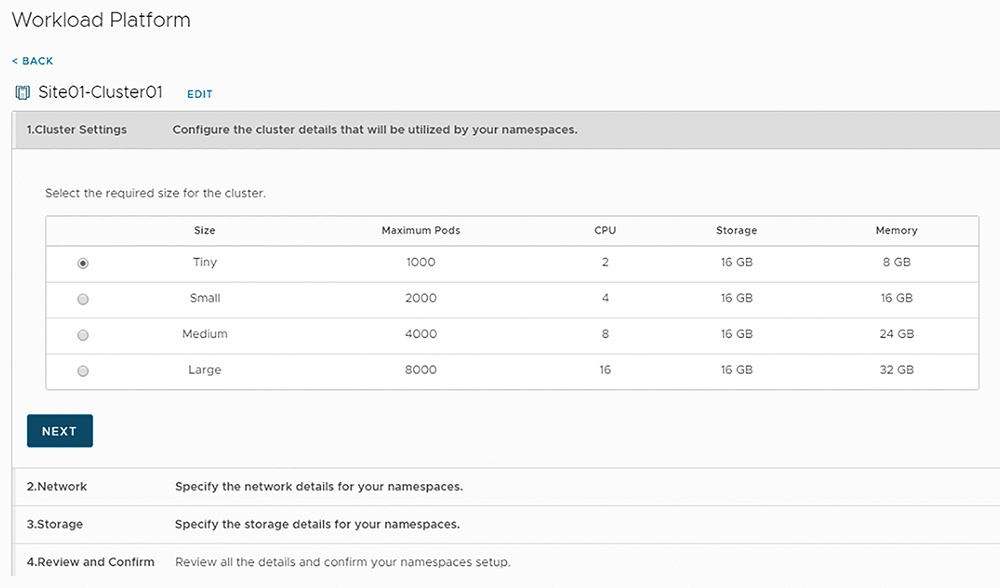 圖14 選擇Supervisor Kubernetes叢集規模大小。
圖14 選擇Supervisor Kubernetes叢集規模大小。
在轉換叢集類型步驟2中,管理人員必須為「控制平面」(Control Plane)組態設定網路資訊。首先,為Supervisor Kubernetes叢集中每一台ESXi成員主機,組態設定「管理網路」(Management Network)資訊,以便屆時叢集類型轉換完畢,vCenter Server管理平台仍然能夠管理每台ESXi成員主機,如圖15所示。
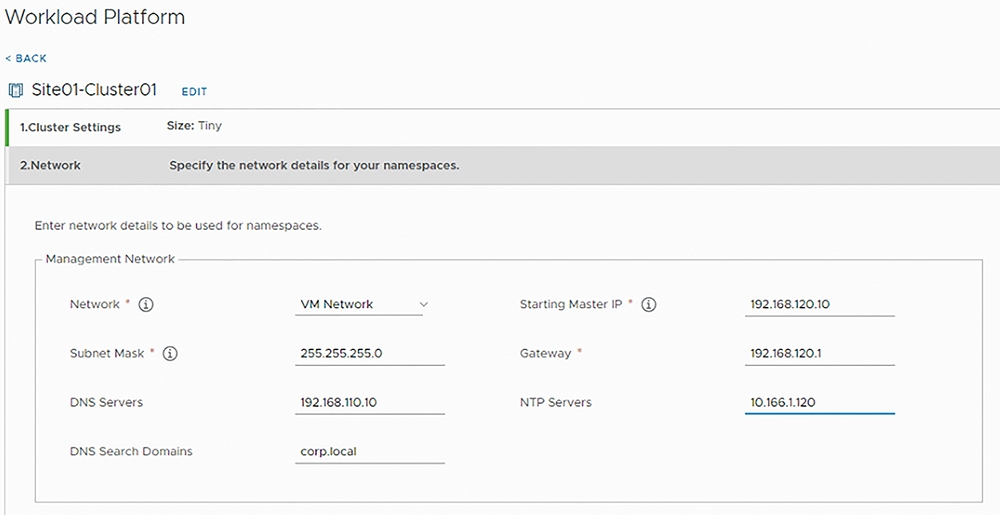 圖15 組態設定Supervisor Kubernetes叢集中每台ESXi成員主機管理網路資訊。
圖15 組態設定Supervisor Kubernetes叢集中每台ESXi成員主機管理網路資訊。
接著,組態設定「名稱空間網路」(Namespace Network)資訊,選擇採用的NSX Distributed Switch和Edge叢集,並且指定採用的DNS伺服器IP位址、屆時Pods運作的網段資訊,以及執行網路流量進入和流出的網段資訊,如圖16所示,以便到時候Supervisor Kubernetes叢集中每台ESXi成員主機和運行的Pods,能夠透過Kubernetes API進行互動和溝通。
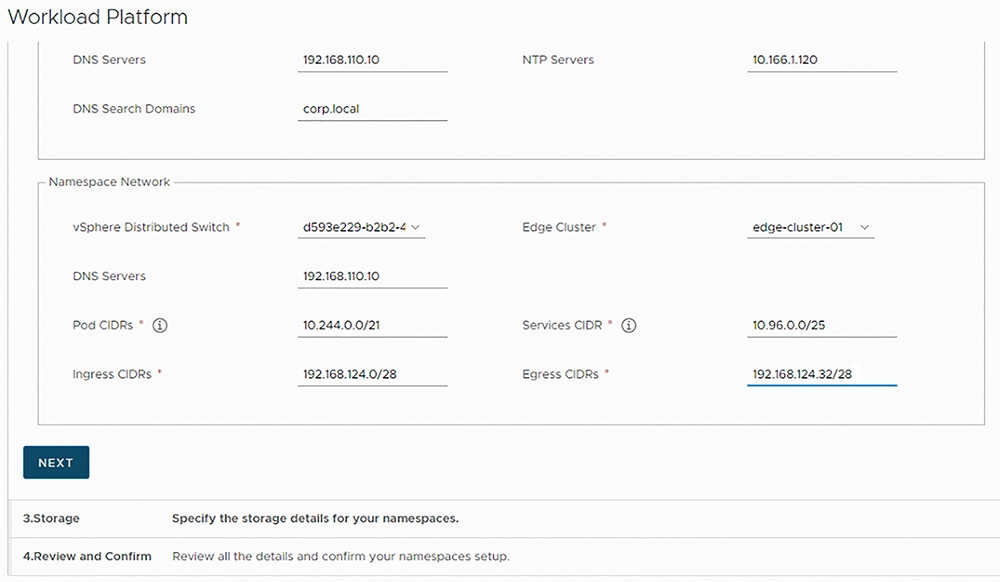 圖16 組態設定Supervisor Kubernetes叢集中每台ESXi成員主機名稱空間網路資訊。
圖16 組態設定Supervisor Kubernetes叢集中每台ESXi成員主機名稱空間網路資訊。

在轉換叢集類型步驟3中,首先選擇屆時套用於「Master Node」的儲存原則,接著是「暫存磁碟」(Ephemeral Disks)部分,則選擇屆時ESXi成員主機運行Pods時使用的暫存儲存資源,最後的「鏡像檔快取」(Image Cache),因為屆時運行在Pods內容器所採用的容器映像檔,將會採用內部的Harbor Container Registry,所以必須選擇容器映像檔所要使用的儲存資源,如圖17所示。
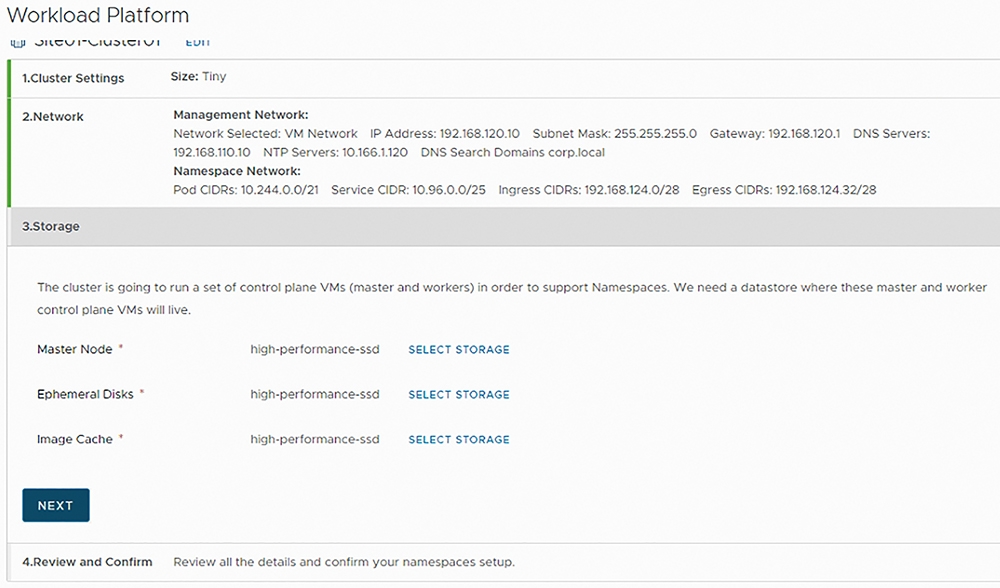 圖17 組態設定Supervisor Kubernetes叢集中每台ESXi成員主機所需儲存資源。
圖17 組態設定Supervisor Kubernetes叢集中每台ESXi成員主機所需儲存資源。

在轉換叢集類型最後的步驟4當中,管理人員再次檢視Supervisor Kubernetes叢集的各項組態設定,確認無誤後按下〔FINISH〕按鈕,當vSphere HTML 5 Client管理介面下方Recent Tasks工作項目欄位中,組態設定Supervisor Kubernetes叢集的工作任務執行完成後,在Workload Platform頁面中的「Clusters」頁籤內,便會出現成功轉換為Supervisor Kubernetes叢集的叢集相關資訊,如圖18所示。
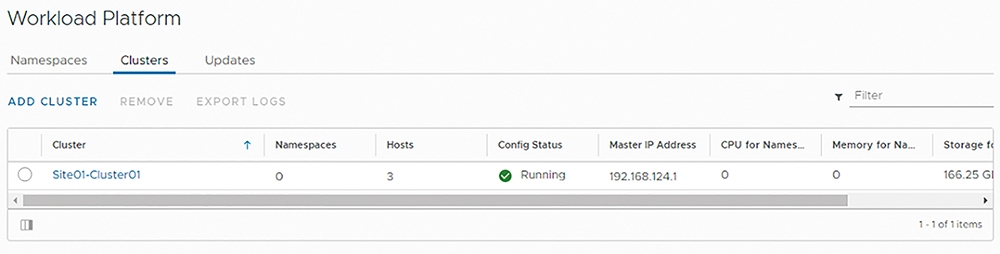 圖18 傳統vSphere叢集成功轉換為Supervisor Kubernetes叢集。
圖18 傳統vSphere叢集成功轉換為Supervisor Kubernetes叢集。
部署和管理名稱空間
在管理介面中,依序點選「Menu > Workload Platform > Namespaces > Create Namespace」,隨後在系統彈出建立名稱空間視窗內,先選擇欲建立名稱空間的Supervisor Kubernetes叢集,再鍵入名稱空間的名稱和描述並且按下〔Create〕按鈕,如圖19所示。
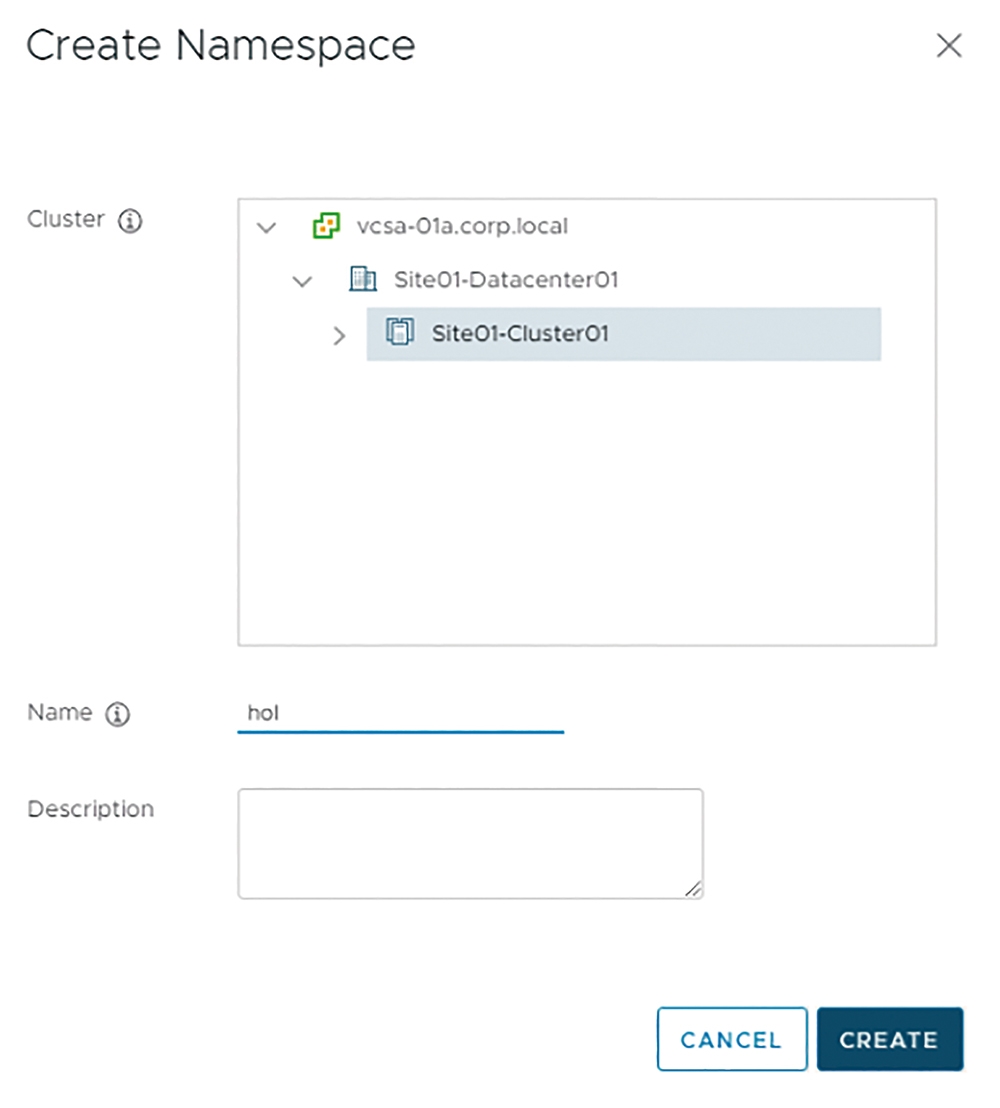 圖19 在Supervisor Kubernetes叢集中建立名稱空間。
圖19 在Supervisor Kubernetes叢集中建立名稱空間。
當建立名稱空間的工作任務完成之後,點選「Menu > Host and Clusters > Namespaces」項目後,管理人員即可看到剛才建立用於開發人員用途的名稱空間概要資訊。現在透過整合vSphere SSO(Single Sign-On)身分驗證機制,指派開發團隊中名稱為「Fred」的使用者帳號具備編輯名稱空間的權限。
在hol名稱空間中,依序點選「Summary > Permissions > Add Permissions」項目,在彈出的Add Permissions視窗中,於Identity source欄位選擇採用的vSphere SSO網域名稱,在User/Group欄位中,則鍵入指派的fred使用者帳號,最後在Role欄位內指派權限為「Can edit」並按下〔OK〕按鈕,如圖20所示。
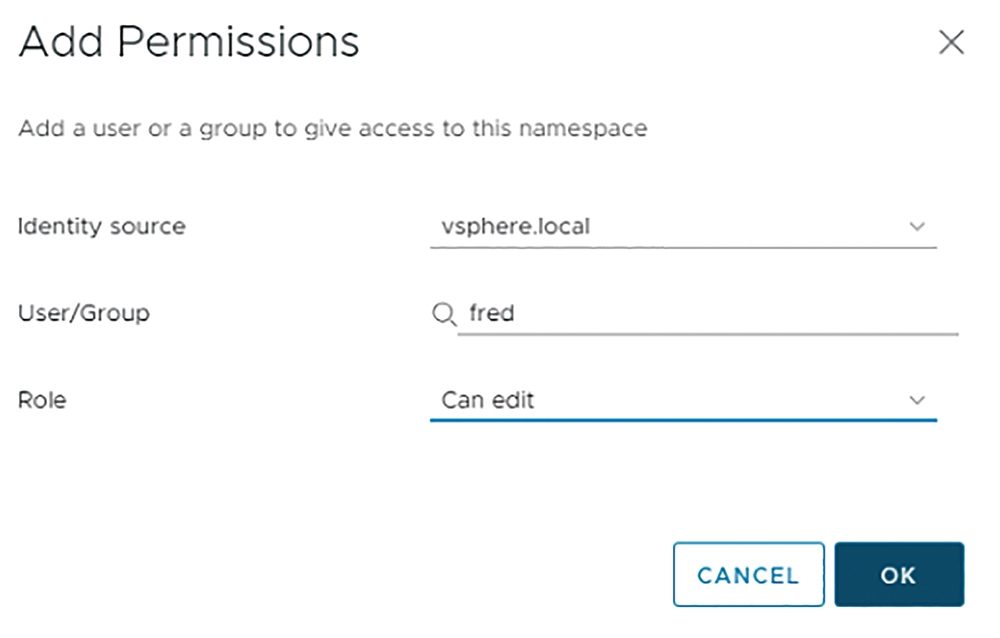 圖20 指派Fred使用者帳號具備管理hol名稱空間的權限。
圖20 指派Fred使用者帳號具備管理hol名稱空間的權限。
接著,在hol名稱空間中的Storage區塊內按下〔Add Storage〕按鈕,然後在系統彈出的Edit Storage Poilcies視窗中選擇要套用到名稱空間的儲存原則,本文實作選擇「high-performance-ssd」,最後按下〔OK〕按鈕即可,如圖21所示。
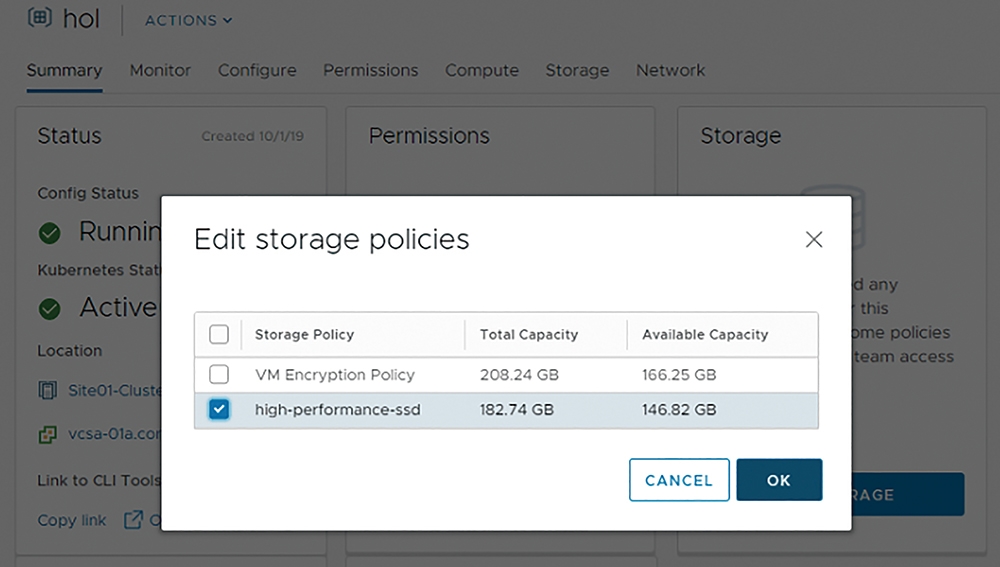 圖21 組態設定名稱空間所要套用的vSphere儲存原則。
圖21 組態設定名稱空間所要套用的vSphere儲存原則。

最後,管理人員可以針對hol名稱空間的硬體資源使用率進行限制,依序點選「Configure > Resource Limits > Edit」項目,然後在彈出的Resource Limits視窗中,組態設定針對名稱空間的硬體資源限制設定值,例如限制僅能使用「3GHz」CPU運算資源、「1GB」Memory運算資源、「2GB」的儲存資源,如圖22所示。
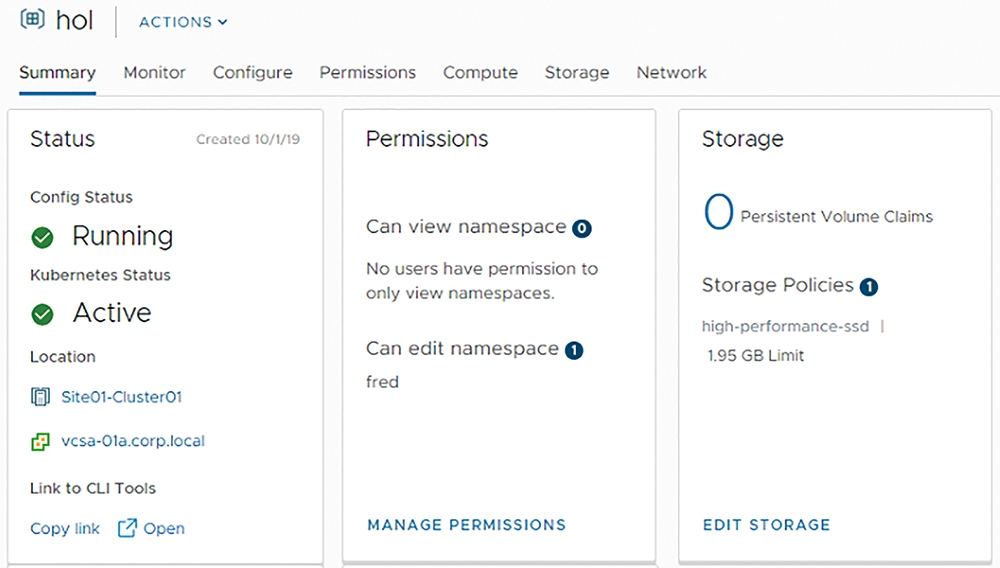 圖22 組態設定名稱空間的硬體資源使用率,限制使用2GB儲存資源。
圖22 組態設定名稱空間的硬體資源使用率,限制使用2GB儲存資源。
<本文作者:王偉任,Microsoft MVP及VMware vExpert。早期主要研究Linux/FreeBSD各項整合應用,目前則專注於Microsoft及VMware虛擬化技術及混合雲運作架構,部落格weithenn.org。>