資料探勘運用科學方法,可從大量的資料中找出有價值的資訊。本文將介紹資料探勘方法,並採用Weka軟體來運用資料探勘分群技術來分析棒球賽資料。最後就分群結果進行討論,期能透過本文的資料探勘過程來運用與分析資料,得窺大數據的奧秘。
我們生活在一個資訊爆炸的年代中,這是現在常常聽到的說法。然而,我們確實是生活在大量資料的年代中。每天從商業、社會、工程科學以及日常生活中,都有著大量的資料流動於網際網路中,資料會呈現如此爆炸性成長的主要因素就在於網際網路的普及。全球的商業活動產生巨大的資料流,包括銷售交易、股票交易紀錄、廣告推播、營運數據以及顧客回饋等等。
然而,商業活動只是日常生活其中的一塊領域,還有其他許許多多無法被清點的資料數量分散在各行各業各領域中。身處資料爆炸的時代,這些大量的資料可稱為大數據(Big Data)。
大數據也被視為新時代的金礦,大家都想從這些資料中挖掘出有用的資訊,並且將資訊轉換為有系統的知識,這項需求促使資料探勘(Data Mining)技術的誕生。
在本文中,將介紹資料探勘與其運作的原理、分析資料探勘在生活中的應用,並以開放資料來源作為實作資料的來源,利用Weka軟體進行實作來協助快速進入資料探勘的世界。
何謂資料探勘
什麼是資料探勘,先從基本觀念說起,然後說明資料探勘如何應用在一般生活之中。
背景知識說明
大數據與資料探勘有著密不可分的關係,大數據就好比是資料探勘的基底,原因在於資料探勘的目的就是要從大數據中挖掘潛藏在資料內的未知發展機會。以下內容將講解大數據以及資料探勘的相關背景知識。
大數據如其名,就是大筆的資料量組合。依據EMC數位世界研究報告,預計至2020年全世界的資料量大約是44ZB。對於在如此龐大的數據,IBM公司提出了對於龐大數據的五大特點,也就是5V:
‧Volume(大量):大數據儲存或計算的量都十分的巨大,起始的單位計算量都是以PB(1,000個TB)或甚至EB(100萬個TB)開始計算。
‧Variety(多樣):資料種類非常多元,包括結構或非結構化資料,也因為種類之多,因此處理這些資料也是一個重要流程。
‧Value(價值):大數據雖然接收到的訊息量巨大,不過也因為過多的資訊,資訊中有價值的訊息會隨之減少,因此透過演算法來找出其中有價值的訊息是大數據要解決的問題。
‧Velocity(高速):數據量增長快,處理速度也必須隨之加快,時效性也十分重要,資料更新速度超越以往的水平。
‧Veracity(真實):數據的真實性及可信賴度會隨著數據量的暴增而降低,眾多訊息中可能存在假消息,所以數據的質量也相當重要。
舉凡是醫療、政府、教育、經濟、人文或是其他各個方面,都有龐大的資料量,然而,在處理這些龐大的資料量時,經常需要借助分析技術來找尋藏在這些資料中的規則,而這個過程就被稱為「資料探勘」。
「資料探勘」這個詞彙是在20世紀90年代從資料庫領域發展出來的,一開始其實是叫做「知識發掘」(Knowledge-discovery in Database,KDD),如知名的學術論壇ACM SIGKDD(Special Interest Group on Knowledge Discovery and Data Mining)都是以KDD結尾命名,因此當時就在討論是否將KDD替換成Data Mining,最後決定是將兩個名稱都保留,因為兩者皆分別在學術研究領域及應用於企業界有著舉足輕重的地位。資料探勘其原文的含意是「Mining from Data」,意思是從資料中挖取金礦,也就是從大量的資料中找出有價值的資訊,這也說明了在現今大數據時代中,巨量的資料給予了資料探勘發展的機會,善用資料探勘技術可以把以前看似不可能的事情化為可能。
應用資料探勘於生活中
資料探勘與我們的距離並不遙遠,雖然一般人並不會特別地去接觸這一塊領域。但是,資料探勘帶給人們的影響可以貼切地反應在日常生活中。因此,以下條列出在生活中資料探勘的一些案例。
在刷信用卡或是現在流行的手機支付時,系統會判斷是否為盜刷的卡片,判斷是基於刷卡時間、地點、金額大小、商品名稱等等,例如刷卡時間在半夜時間,跟平日在白天刷卡的習慣不一樣,或是再加上刷卡金額過大,此時就很有可能被判定為盜刷,然而,這些資料來源都是每一次刷卡的時候留下的紀錄,因此久而久之便累積大量資料,就可以透過資料探勘協助判斷是否為盜刷卡片,有效地先在第一線預判是否為交易詐欺的行為。
在常見的商業銀行中,不管是哪間銀行,共通點都是具有大量的客戶,每個客戶到銀行處理事情的行為有相似及相異之處。因此,透過資料探勘分析交易紀錄,可以深入了解每個客戶的需求,針對不同的客群提供不同的服務。
在2008年,Google的研究人員利用使用者在網路上搜尋的關鍵詞,Google這套系統真正做的是針對搜尋字眼的搜尋頻率,找出與流感傳播的時間、地區有沒有統計上的相關性(Correlation),在同一年也開發出Google流感預測系統(Google Flu Trends),宣稱其預測結果與美國疾病管制預防中心(CDC)的預測相近,且預測結果是幾乎同步掌握,Google的研究人員也把這個過程寫成一篇論文發表在知名的《Nature》期刊。
2018年時的熱門新聞之一就是劍橋分析(Cambridge Analytica)事件。這家公司透過取得許多個人資料,尤其是透過一款臉書的心理測驗App來取得許多臉書使用者的資料,透過資料探勘進行大數據分析,就能針對不同的對象來散播假消息,甚至進一步試圖影響美國大選選情。
資料探勘技術流程與分析方法
以下說明資料探勘技術的相關流程,及其分析方法。
資料探勘技術的流程
在進行資料探勘時,建立出預測模型是首要任務,建立模型同時也是在找尋規則,圖1所示為建立模型的流程。
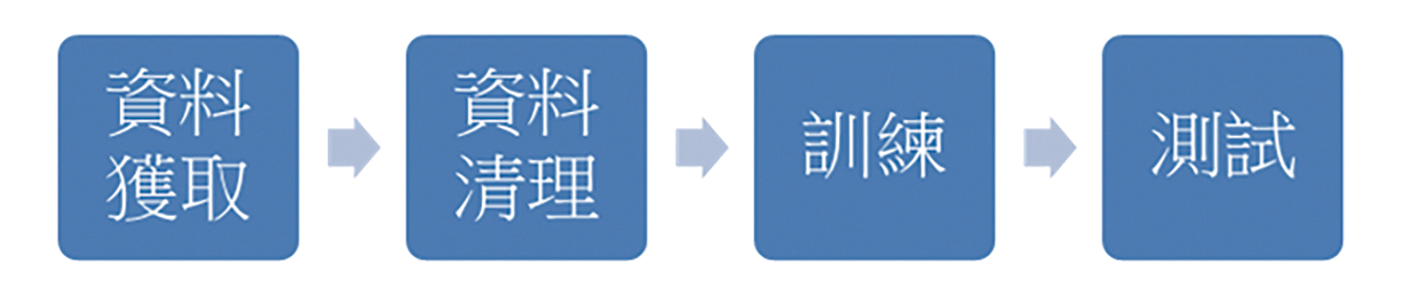 圖1 資料探勘流程圖。
圖1 資料探勘流程圖。
‧資料獲取:取得資料供建立模型。對資料探勘而言,最重要的東西當然就是大量的資料,如果只是極少的資料,挖掘出來的結果就可能欠缺參考價值。資料獲取的來源有很多種,例如公開資料平台、公司產品銷售紀錄、系統本身記錄的資料、使用網頁爬蟲獲得的資料等等,都可以是資料的來源。
‧資料清理:整理與清理大量的資料。藉由各種方式蒐集到大量的資料之後,資料常常是雜亂無章。因此,必須進行資料清理,檢查資料中是否有錯誤或異常,並進行轉化成結構化資料,方便進行資料探勘使用。
‧訓練:用來建立資料模型(Model)。會把所得到的資料分為訓練集(Training Set)與測試集(Testing Set),所佔的比重大約是6:4。使用訓練集及演算法從訓練資料中篩選出需要用到的資料,並且找尋資料的規則與相互間的關聯,透過這些規則建立起對應的模型。
‧測試:檢驗模型的泛化(Generalization)能力,也就是模型是否適用於未知的資料。當從訓練集中建立初步的模型後,下一步就是要透過測試集測試模型精確度。測試集與訓練集有著相同的格式,但不同的點是,測試集是針對從訓練集建立的模型進行驗證,評估差異程度,差異越小與現實情況就越接近,表示此從訓練集訓練出來的模型越有效。反之,如果差異程度太大,就必須回頭再重新調整模型。
資料探勘技術的方法
根據不同的目的,會使用不同方法建立需要的資料模型,常見的幾種建立模型方法可以分為:1.分類分析(Classification)、2.分群分析(Clustering)、3.關聯分析(Association)、4.迴歸分析(Regression)、5.時間序列分析(Time Series Forecasting),在此以2.分群分析為主進行介紹。
分群分析,簡稱為分群,是將資料分割成不同子集合的一個程序,在透過分群演算法分群之後,相似的資料會被分在同一群。而被分在不同群之間的資料,彼此之間的相似度就會比較低。此分析方式非常適合用於挖掘在同一資料集合內還未被發現的群組結構,在生活日常中,分群已經被廣泛地運用在各式各樣的應用上,常聽到的例如生物科學與資訊安全、網頁搜尋或商業智慧等等。在商業智慧上,分群技術可以將大量的顧客資料做分群,建立市場區隔,用此方式幫助企業管理顧客關係,同時也增進企業的發展。
情境案例分析
在此採用Weka這套軟體進行實作。Weka為一個資料探勘工作平台(https://www.cs.waikato.ac.nz/ml/weka/),由紐西蘭的團隊以Java為基礎所開發,集合了大量能執行資料探勘任務的演算法,包含常用的分類、分群、關聯、迴歸等,對於不熟悉程式開發的使用者,也能透過這套軟體來實現資料探勘。
在本文中,將以Weka這套軟體中提供之分群分析方法中的演算法「K-means」進行實作,透過Weka軟體,在操作「K-means」演算法時,只需要設定資料要被分成多少群,就可以輕鬆地得到分析出來的結果。
接下來,分成三個部分說明,首先是資料說明,再來就是整個操作流程,最後則是說明分析結果。
資料說明
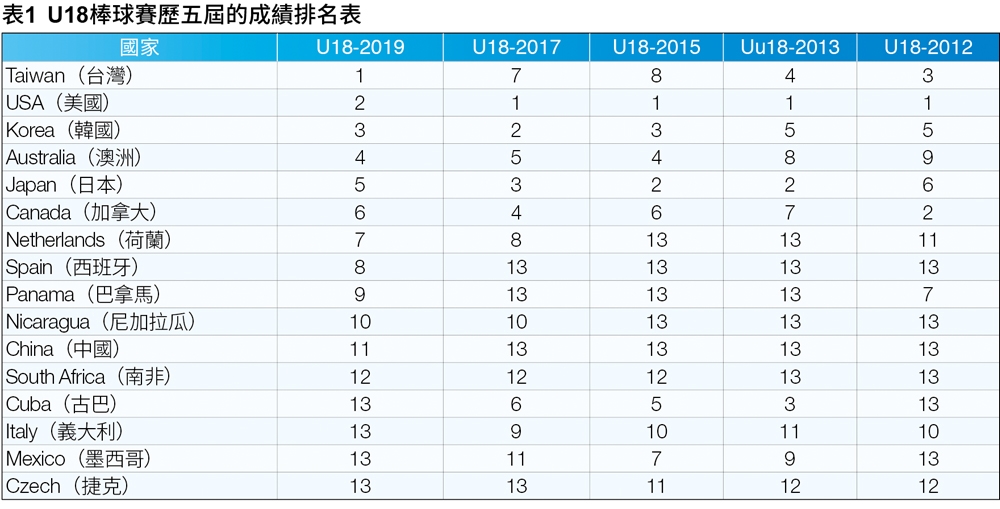
棒球為台灣人的國球,是關注度最高的球類,若想要了解目前台灣18歲以下的棒球水平在國際上的地位排名並分析在國際上賽場的表現,以及分析當被分配到與哪些國家一組時,戰術和心態上的做法要怎麼做調整,首先蒐集了過去五屆的U18棒球世界盃的總排名。
表1為依照歷屆的排名製成的表格,例如台灣在2019年的時候奪得了第一名,因此該表格就填寫為1,以此類推。然而,因為U18世界盃只有採到前12名,因此如果該年度該國並未參賽或是早已在預賽慘遭淘汰未取得前12強的排名,則該表格填寫為13。先預期將這些國家分為四群,再來分析每個群組中的國家棒球實力,得出的結果就能夠得知當國際比賽時與哪些國家抽在同一組時可能會對我國造成較大的壓力。
資料操作流程
STEP 1:打開Weka,按下〔Explorer〕選項按鈕,如圖2所示。
 圖2 啟動Weka後,選按〔Explorer〕按鈕。
圖2 啟動Weka後,選按〔Explorer〕按鈕。
STEP 2:在Preprocess標籤頁中點選〔Open file〕,然後選取所要分析的資料,如圖3的步驟1所示。在此也能對要分析的資料預先處理,如Country屬性內的資料並非數值,無法計算,所以可先選取這個欄位,如步驟2所示,再點選〔Remove〕移除,如步驟3所示。而這次的實作要採用的是分群(Cluster),因此接下來就必須選擇Cluster標籤頁,步驟4所示。
 圖3 在Weka操作介面中依序操作步驟1至步驟4。
圖3 在Weka操作介面中依序操作步驟1至步驟4。
STEP 3:在Choose欄位中預設使用EM,此次將選用「K-means」演算法,所以改用SimpleKMeans,如圖4所示。之後再點擊SimpleKMeans欄位,可以選擇要把資料分成幾群(NumClusters),在此設定為4,如圖5所示。
 圖4 在Choose欄位中選用「K-means」演算法。
圖4 在Choose欄位中選用「K-means」演算法。
 圖5 在NumClusters欄位內將資料分成4群。
圖5 在NumClusters欄位內將資料分成4群。
STEP 4:最後點選〔Start〕來執行,結果顯示在右邊的output方框內,將得到如圖6的結果所示。
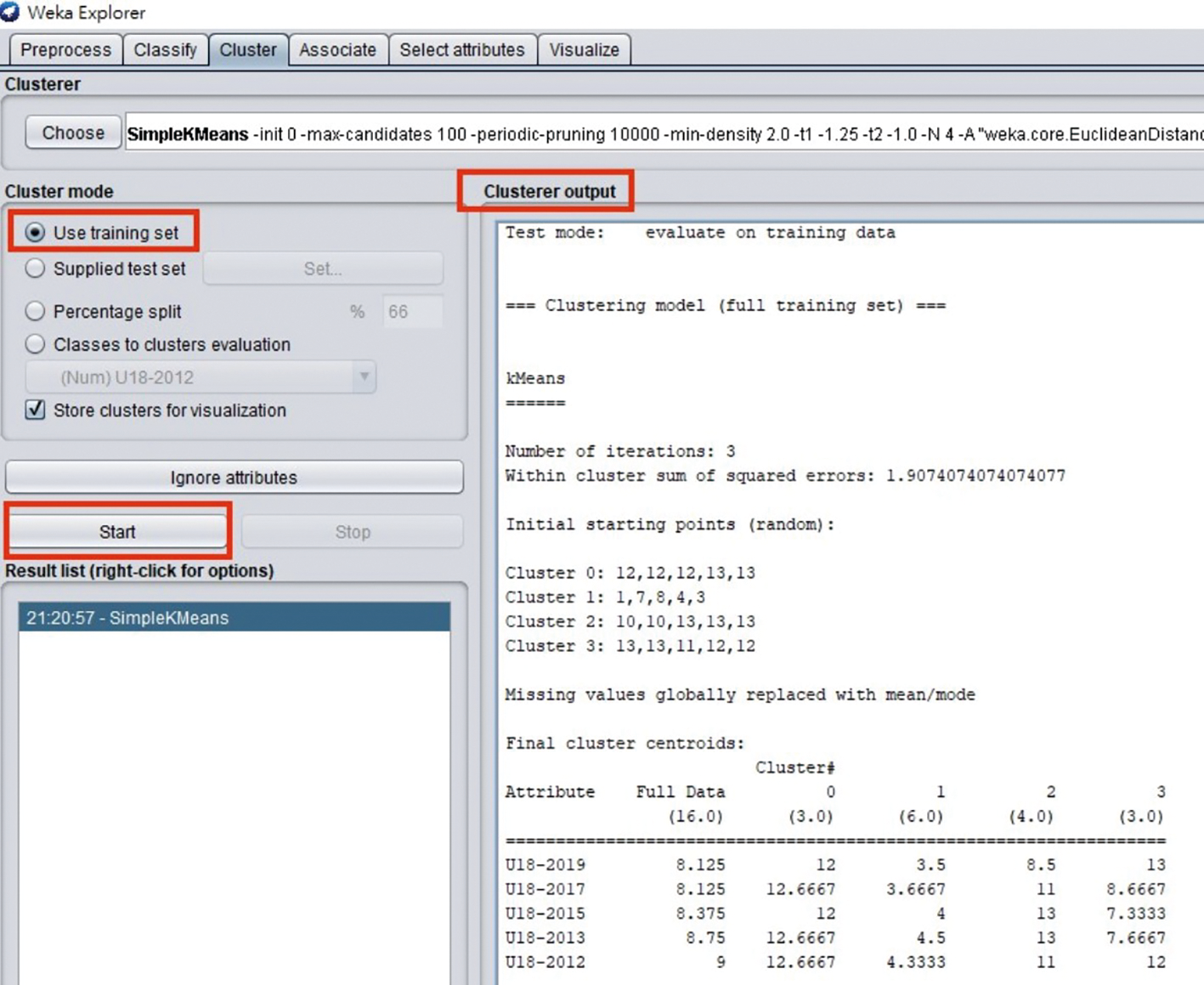 圖6 按下〔Start〕後的執行結果畫面。
圖6 按下〔Start〕後的執行結果畫面。
透過Weka,可以在「Result list」按下滑鼠右鍵,然後點選快速選單中的【Visualize cluster assignments】,來查看分群的視覺化顯示,如圖7所示;並可將分群的結果儲存成輸出成arff檔,如圖8所示。藉以查看分群的結果是否符合預期,並透過採用不同的設定與演算法來尋找更好的分群方法。
 圖7 將結果以視覺化方式顯示。
圖7 將結果以視覺化方式顯示。
 圖8 將分群結果儲存。
圖8 將分群結果儲存。
大數據資料解析
為清楚表達分析方式,這裡以圖表的方式做說明。表2為「K-means」將各個國家分群的結果,該表格將Cluster 0到Cluster 3分群排列,例如Taiwan(台灣)被分在Cluster 1,或是如Czech(捷克),該國被分在Cluster 0,其餘的國家以此規則類推,並將分群出來的國家棒球實力排名由上到下依序為由強到較弱。
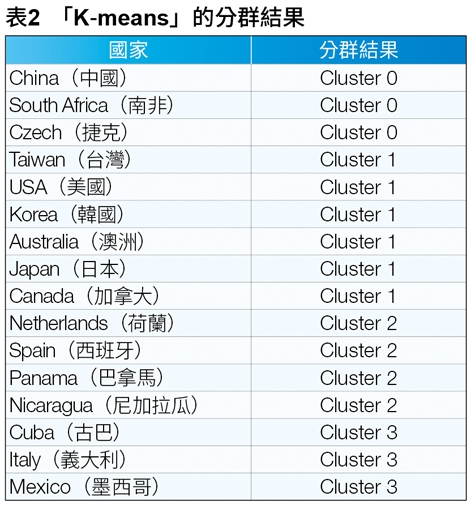
圖9(a)為分群出來的結果,有Attribute(屬性)、Full Data(全部的值)以及Cluster(群)0、1、2、3。從Attribute "U18-2019" 一列一列地往下看,總計會看到五列,並且比較直行的Cluster 0、1、2、3中的數值,當每一群內的整體數值越低,即代表該群內的國家在18歲的棒球實力是較為完整且堅強,是國際賽場上的奪冠熱門國家,因此在國際賽場上遇到的時候就要格外注意。以下依序講解圖9(b)到圖9(e)中所分出來的每一群所想要傳達的訊息:
 圖9(a) 「K-means」分群分析。
圖9(a) 「K-means」分群分析。
首先,在圖9(b)中,注意到的是Cluster 0這一行的數值資料,可以看出該群的數值與其他群(1、2、3)有明顯落差,每一屆的世界盃在數值上全部都是12以上,由此可見,該群在棒球上的實力並沒有比其他群來得堅強,經常都是沒有進到12強之內或是有晉級12強但是最後排名都位於吊車尾的第12名,因此當台灣隊碰上該群中的隊伍時,對戰壓力相對起來比其他群中的國家要來得小。
 圖9(b) 「K-means」分群分析Cluster 0。
圖9(b) 「K-means」分群分析Cluster 0。
緊接著,在圖9(c)中可以看到Cluster 1這一行的整體數值明顯小於另外三群(0、2、3),表示該群中的國家在國際賽場上的排名往往都是前段班,同時也都是奪冠的熱門人選,因此當台灣隊在比賽的時候被分到與該群中的國家同一組的時候,實力較為相當,需要特別提防且研擬戰術來想辦法贏得比賽勝利。
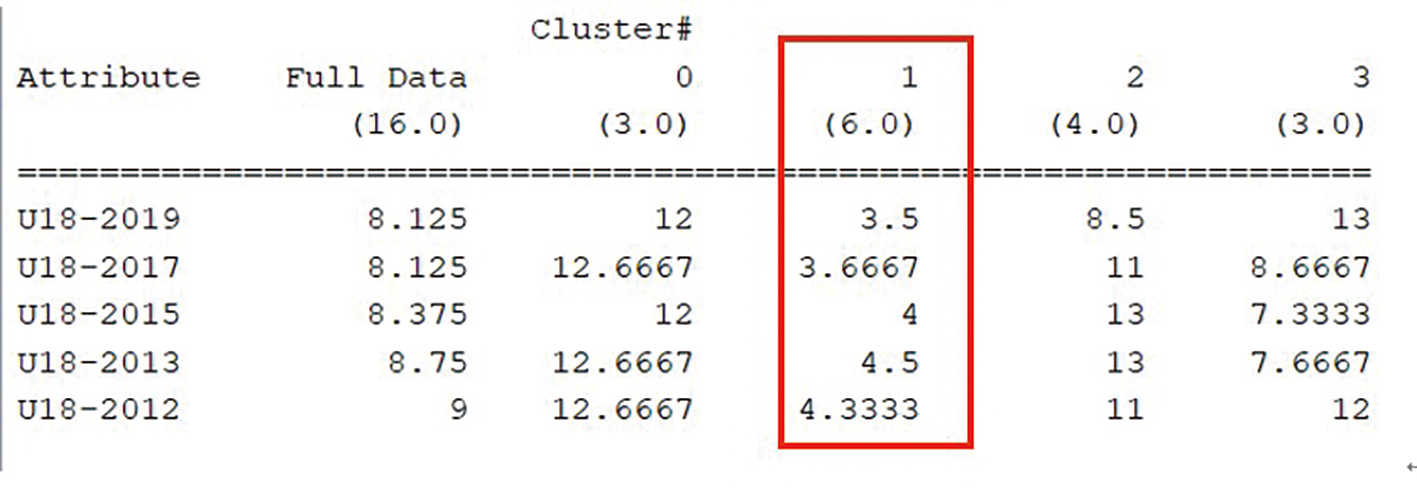 圖9(c) 「K-means」分群分析Cluster 1。
圖9(c) 「K-means」分群分析Cluster 1。
如圖9(d)所示,U18-2015及U18-2013這兩列中高於Cluster 0的數值,但是在其餘的三屆都是明顯優於Cluster 0,從過去的成績來看,Cluster 2中的國家有些好幾年沒能晉級到12強,但是與Cluster 0不同的點在於,Cluster 2中的國家在2019年都有相當的進步,未來將有機會更上層樓。
 圖9(d) 「K-means」分群分析Cluster 2。
圖9(d) 「K-means」分群分析Cluster 2。
最後看到圖9(e),Cluster 3的數值資料,數值中看出雖然沒有比Cluster 1的數值來得優異,但是相比起Cluster 0和Cluster 2仍舊是略勝一籌,被分配在該群中的國家也都是晉級前12的熱門國家,甚至像是Cuba(古巴)在2013年時還取得了第3名的佳績,在群內的其他國家也都是能夠連續三年晉級前12強的隊伍。由此可見,該群內的國家雖然比賽起來較不會像Cluster 1中的國家的威脅這麼大,但是整體實力還是不可小覷。
 圖9(e) 「K-means」分群分析Cluster 3。
圖9(e) 「K-means」分群分析Cluster 3。
運動賽事的排名經常會有出乎意料的結果,從原始資料來看,古巴隊即使在2013年時取得了第3名相當優異的成績,但是在2019年及2012年也都有排名不盡理想的時候。其實不管是哪一種運動賽事,都可透過數據來事先分析與預測可能的結果。但也會有部分國家或球員有令人驚奇的表現,導致原本的預測出現變化而導致預測結果得以些微差異,偶有「跌破眼鏡」情事,而這也是體育運動賽事迷人的地方。
結語
在現今巨量資料的時代裡,資料探勘這項技術能夠協助從資料中挖掘出需要用到的資訊。本文介紹了資料探勘的基本技術原理,並透過實作分群分析的案例來模擬資料探勘如何找出潛藏在大量資料中的資訊,同時也加上簡單扼要的操作流程,讓沒有相關背景的人也可以立即上手試做。在該實驗中,蒐集了過去五屆18歲組棒球賽的比賽成績,整理好數據,透過Weka軟體執行「K-means」演算法,就能夠得知在18歲組的棒球世界哪個國家是實力完整且是奪冠大熱門。時至今日,已經有許多產業和學術領域透過資料探勘技術來分析大量資料,找出關鍵部分來因應處理,而得以提升整體競爭力。因此,資料探勘在目前已是不可忽視的存在。
<本文作者:社團法人台灣E化資安分析管理協會(ESAM, https://www.esam.io/ ), 元智大學資訊管理系決策支援系統實驗室 ,由詹前隆教授領軍的研究團隊,詹前隆教授目前亦是元智大學資訊管理系教授兼大數據與數位匯流創新研究中心主任。>