2020年3月正式發佈的VMware vSphere 7內建了Kubernetes叢集環境,堪稱一大壯舉,隨後在2020年10月又釋出了vSphere 7 Update 1。此次的版本更新除了進一步擴大原有的運作規模外,又增強及新增了許多功能,本文將詳細介紹這些新穎功能的特色。
全新的VMware vSphere 7解決方案在2020年3月正式發佈,同時內建了Kubernetes叢集環境,並在2020年10月正式推出vSphere 7 Update 1更新版本。雖然vSphere 7 Update 1看似小版本更新,然而在這個Update 1版本中,除了原有運作規模大幅成長之外,也增強和新增許多特色功能。
首先,在vSphere叢集運作規模方面,vSphere 7版本中「單台」ESXi虛擬化平台,實體記憶體空間最大支援至16TB,而新版vSphere 7 Update 1則一舉拉升至24TB。
除此之外,在vSphere叢集支援ESXi成員主機數量部分,也從原有的64台提升為96台,至於vSphere叢集運作VM虛擬主機的數量,也從原有6,400台大幅提升為10,000台。

同時,在VM虛擬主機運作規模方面,在vSphere 7版本中,「單台」VM虛擬主機的vCPU數量最多支援至256 vCPU,在vSphere 7 Update 1版本中提升至768 vCPU,在vRAM虛擬記憶體方面,也從原有最大支援從6TB大幅提升為24TB,如圖1所示。
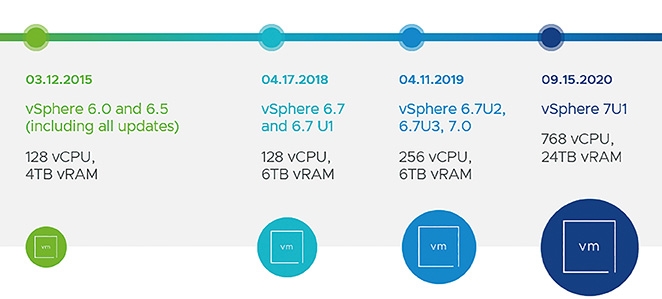 圖1 vSphere 7 Update 1 Monster VM運作規模示意圖。 (圖片來源:VMware vSphere Blog - What's New with VMware vSphere 7 Update 1)
圖1 vSphere 7 Update 1 Monster VM運作規模示意圖。 (圖片來源:VMware vSphere Blog - What's New with VMware vSphere 7 Update 1)
vSphere 7 Update 1亮眼特色功能
關於vSphere 7 Update 1亮眼特色功能,以下分成四部分加以介紹。
vSphere with Tanzu
在新版vSphere 7發佈的時候,企業組織可以採用VCF(VMware Cloud Foundation),因為包含vSphere、NSX、vSAN、vRealize、SDDC Manager等私有雲管理工具組合,讓企業可以同時輕鬆打造傳統VM虛擬主機,以及新世代工作負載的容器和應用程式。
現在最新發佈的vSphere 7.0 Update 1,讓TKG(Tanzu Kubernetes Clusters)可以直接與企業資料中心內已經建構好的vDS(vSphere Distributed Switch)分佈式虛擬交換器連接,並且在搭配由HAProxy所提供的負載平衡機制後,便可無須導入NSX軟體定義網路解決方案,也能夠建構vSphere with Tanzu容器管理平台。

由於「K8s控制平面」(Kubernetes Control Plane)已經嵌入vSphere核心當中,並且每台ESXi虛擬化管理平台內皆已部署K8s代理程式(稱之為Spherelets),由眾多ESXi成員主機建構的Kuberntes叢集稱之為「Supervisor Cluster」,並且每台ESXi成員主機便是擔任Kubernetes Worker Nodes的角色。所以,在vDS分佈式虛擬交換器組態設定的部分,只要確保vCenter Server管理平台和K8s控制平面之間能夠通訊即可,如圖2所示。然而,因為環境中沒有導入NSX軟體定義網路的話,表示沒有NSX內建負載平衡機制幫忙引導容器和相關流量,此時可以導入TKG正式支援的第一個負載平衡器「HAProxy」,如圖3所示,部署的方式也非常容易,只要導入OVF即可。
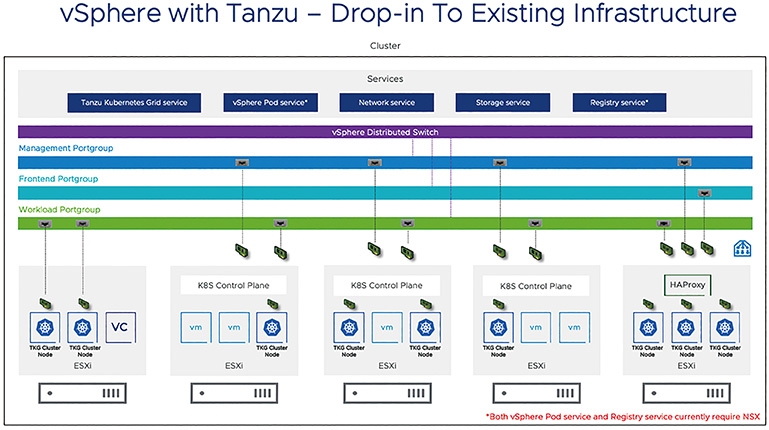 圖2 vSphere with Tanzu正式支援vDS分佈式虛擬交換器。 (圖片來源:VMware vSphere Blog - vSphere With Tanzu - Getting Started with vDS Networking Setup)
圖2 vSphere with Tanzu正式支援vDS分佈式虛擬交換器。 (圖片來源:VMware vSphere Blog - vSphere With Tanzu - Getting Started with vDS Networking Setup)
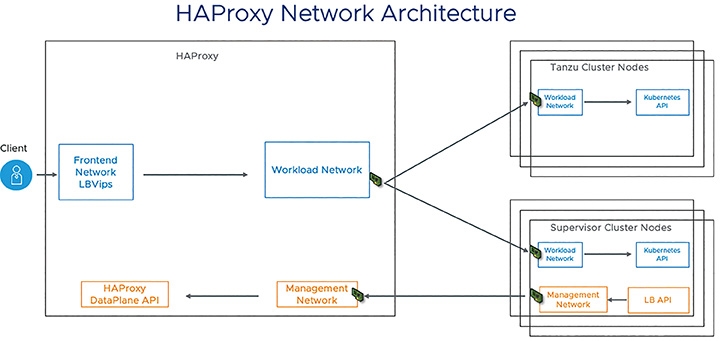 圖3 部署HAProxy流量負載平衡器。 (圖片來源:VMware vSphere Blog - vSphere With Tanzu - Getting Started with vDS Networking Setup)
圖3 部署HAProxy流量負載平衡器。 (圖片來源:VMware vSphere Blog - vSphere With Tanzu - Getting Started with vDS Networking Setup)

當管理人員規劃完成,並且組態設定HAProxy使用的負載平衡VIPs位址,以及TKG叢集節點所需的IP位址之後,便能啟用vSphere with Tanzu特色功能,在啟用頁面中可以看到環境中並沒有導入NSX-T軟體定義網路解決方案,而是選擇vCenter Server Network,如圖4所示,也就是採用vDS分佈式虛擬交換器搭配HAProxy負載平衡器。
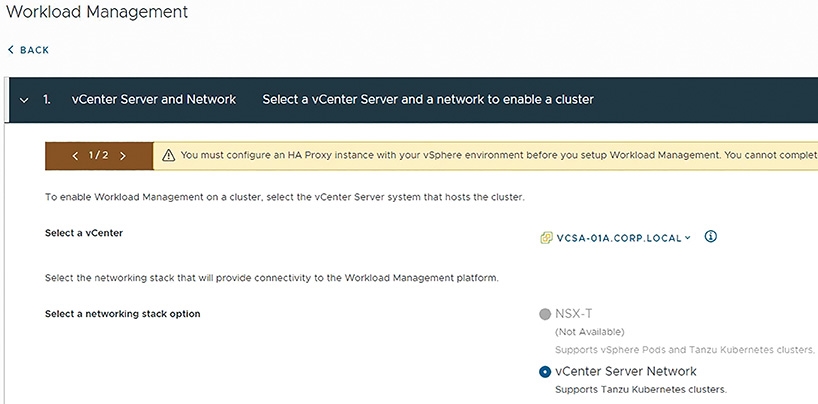 圖4 採用vDS分佈式虛擬交換器搭配HAProxy負載平衡器搭建TKG容器執行環境。 (圖片來源:vSphere With Tanzu - Networking with vSphere Distributed Switch)
圖4 採用vDS分佈式虛擬交換器搭配HAProxy負載平衡器搭建TKG容器執行環境。 (圖片來源:vSphere With Tanzu - Networking with vSphere Distributed Switch)
vLCM生命週期管理員再升級
vLCM(vSphere LifeCycle Manager)為vSphere 7版本新增特色功能,但是僅針對vSphere和vSAN提供基本支援,其他VMware產品如NSX-T便無法支援。
而全新推出的vSphere 7.0 Update 1版本中,增強vLCM生命週期管理員功能,除了全面支援原有的vSphere和vSAN外,包括安全性更新、版本升級、整合韌體等等,現在連NSX-T也同樣支援。舉例來說,部署的NSX Manager可以透過vLCM API應用程式開發介面來管理NSX-T運作環境生命週期,包括安裝、組態設定、運作、升級等等維護項目,如圖5所示。
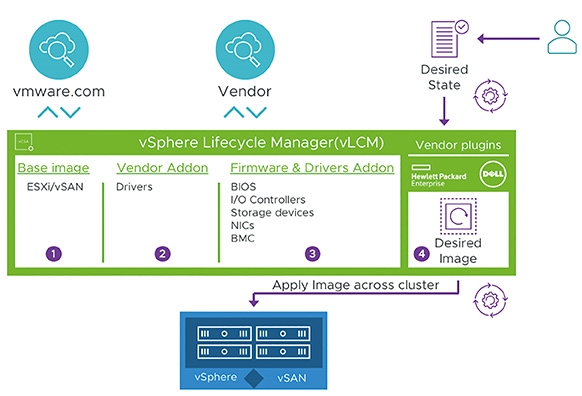 圖5 vLCM生命週期管理員功能全面升級並支援NSX-T運作環境。 (圖片來源:VMware vSphere Blog - vSphere 7 Update 1 - vSphere Lifecycle Manager Improvements)
圖5 vLCM生命週期管理員功能全面升級並支援NSX-T運作環境。 (圖片來源:VMware vSphere Blog - vSphere 7 Update 1 - vSphere Lifecycle Manager Improvements)
AMD SEV-ES安全加密虛擬化
在2019年8月時,VMware官方正式宣佈vSphere支援AMD EPYC處理器。同時,在新版vSphere 7.0 Update 1中,全面支援「安全加密虛擬化-加密狀態」(Secure Encrypted Virtualization – Encrypted State,SEV-ES)機制,幫助企業組織從底層硬體直接防堵Spectre和Meltdown等令人困擾的硬體底層漏洞。
或許,管理人員會有這樣的疑惑,為何ESXi和VM虛擬主機已經具備隔離的特性,舉例來說,VM Runtime和Guest OS客體作業系統,其實是運作在由ESXi虛擬化平台所建構的「沙箱」(Sandbox)隔離環境中,如圖6所示,為何還需要底層硬體伺服器的安全性保護機制呢?
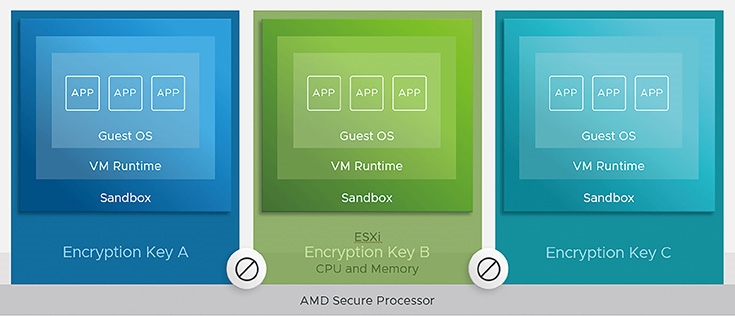 圖6 VM Runtime和Guest OS客體作業系統運作在ESXi提供的沙箱隔離環境。 (圖片來源:VMware vSphere Blog - vSphere 7 Update 1 - AMD SEV-ES)
圖6 VM Runtime和Guest OS客體作業系統運作在ESXi提供的沙箱隔離環境。 (圖片來源:VMware vSphere Blog - vSphere 7 Update 1 - AMD SEV-ES)
簡單來說,VM Runtime和Guest OS運作的沙箱隔離環境其實是軟體式的,然而當Guest OS客體作業系統需要硬體資源時,其實還是會透過ESXi虛擬化平台向底層發出使用硬體資源的請求。倘若底層硬體未進行加密保護機制,那麼受到侵入感染的Hypervisor,便能夠讀取或修改底層硬體資源中,VM虛擬主機存放於底層硬體處理器或記憶體內的機敏資料。
因此,透過SEV-ES安全加密虛擬化保護機制搭配加密金鑰,即便Hypervisor受到侵入感染,也將因為沒有加密金鑰,而無法讀取或修改底層硬體資源中VM虛擬主機的機敏資料,搭配原有的VM Runtime和Guest OS沙箱隔離環境保護機制,幫助企業達到雙重保護效果機敏資料不外洩。

針對大型工作負載最佳化的vSphere vMotion
事實上,在新版vSphere 7版本中,已經重構vSphere vMotion即時遷移機制,並在vSphere 7 Update 1再度增強,以便企業組織運作大型工作負載,例如SAP HANA、Epic Operational Databases、InterSystems Cache、IRIS等等大型規模怪獸等級的VM虛擬主機時,能夠有效縮短即時遷移的作業時間,並避免「切換時間」(Switch-Over Time)或稱「擊暈時間」(Stun-Time),對大型規模應用程式造成的影響。
舊版的vSphere 6.7採用「Stop-Based Trace」機制,針對執行即時遷移的VM虛擬主機,停止「所有」vCPU執行任何客體作業系統發出的請求指令,執行追蹤作業完成後再讓VM虛擬主機恢復運行。雖然這樣的即時遷移機制對於中小型規模的VM虛擬主機效果很好,造成的停止時間也僅僅幾百「微秒」(microseconds),然而對於大型規模的VM虛擬主機則不然,因為在vCPU數量越多的情況下,停止和恢復作業所需花費的時間越長,有可能導致VM虛擬主機內的應用程式發生中斷事件。
新版的vSphere 7 Update 1改採「Loose Trace」機制,如圖7所示,針對執行即時遷移的VM虛擬主機,僅會停止「單一」vCPU執行任何客體作業系統發出的請求指令,其他vCPU則繼續執行客體作業系統發出的請求指令,所以在即時遷移期間對於VM虛擬主機的效能影響最小,同時不會造成應用程式發生中斷事件。
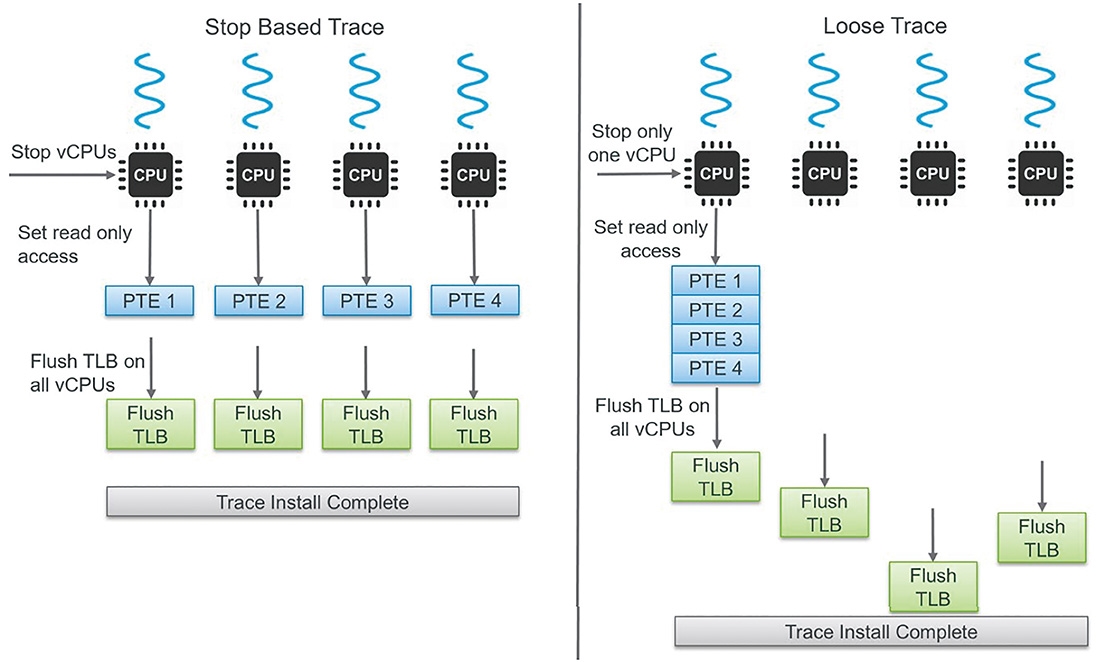 圖7 新舊版本vSphere vMotion即時遷移頁面追蹤技術示意圖。 (圖片來源:Performance Study – vMotion Innovations in VMware vSphere 7.0 U1)
圖7 新舊版本vSphere vMotion即時遷移頁面追蹤技術示意圖。 (圖片來源:Performance Study – vMotion Innovations in VMware vSphere 7.0 U1)
在「頁面追蹤」(Page Tracing)資料區塊大小的部分,舊版的vSphere 6.7採用「4KB」小型資料區塊,傳輸即時遷移的VM虛擬主機vRAM虛擬記憶體空間,同樣地對於中小型規模的VM虛擬主機效果很好,然而對於大型規模的VM虛擬主機而言,除了容易造成vMotion即時遷移時間過長之外,也會影響大型應用程式的運作。
新版的vSphere 7 Update 1採用「Large Trace」機制,如圖8所示,並且改用「1GB」資料區塊,傳輸即時遷移的VM虛擬主機vRAM虛擬記憶體空間,同時搭配其他最佳化機制,例如Bitmap、Switch-Over、Large Page Handling等等。 首先,在VMware官方測試環境中,為VM虛擬主機配置72 vCPU和1TB vRAM虛擬硬體資源,應用程式工作負載的部分則是採用Oracle資料庫,並且搭配Hammer DB模擬工作負載,可以看到舊版vSphere vMotion的即時遷移機制,與重構及最佳化後的新版vSphere vMotion相較之下,新版vSphere vMotion除了更快遷移完成外,在即時遷移和切換恢復期間的Oracle資料庫、整體的Commits數量,都優於舊版的vSphere vMotion,如圖9所示。
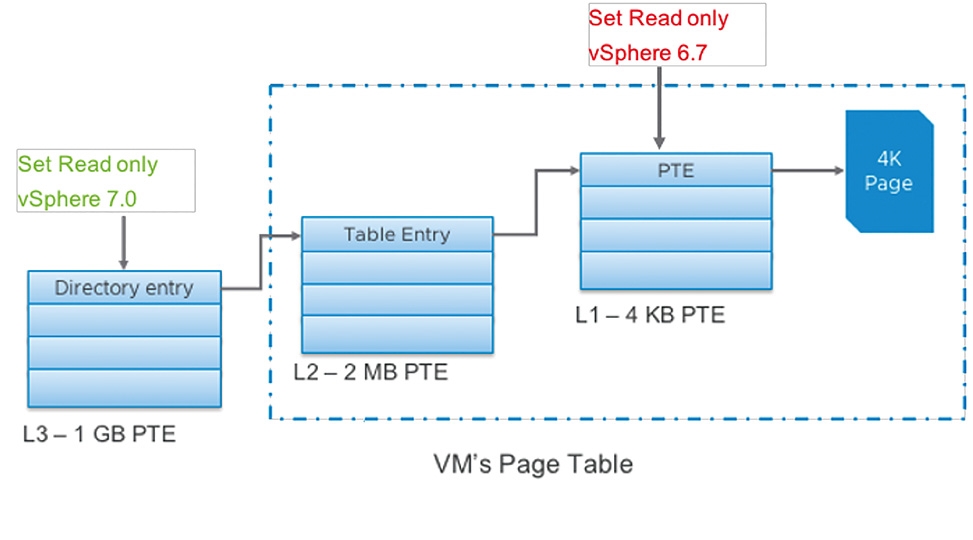 圖8 新舊版本頁面追蹤資料區塊大小示意圖。 (圖片來源:Performance Study – vMotion Innovations in VMware vSphere 7.0 U1)
圖8 新舊版本頁面追蹤資料區塊大小示意圖。 (圖片來源:Performance Study – vMotion Innovations in VMware vSphere 7.0 U1)
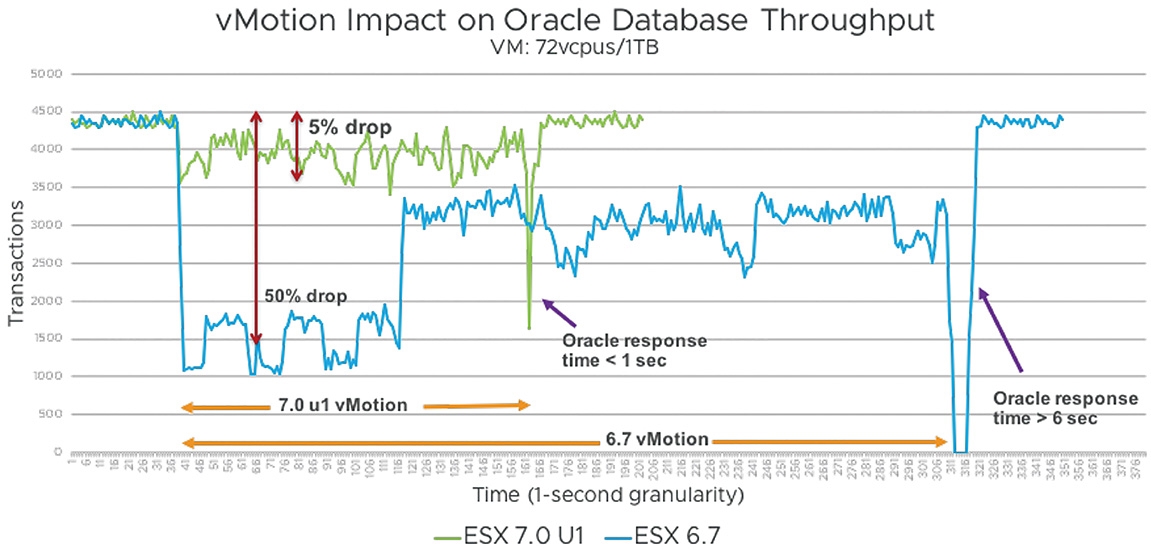 圖9 舊版和重構及最佳化的新版vSphere vMotion即時遷移測試結果。 (圖片來源:Performance Study – vMotion Innovations in VMware vSphere 7.0 U1)
圖9 舊版和重構及最佳化的新版vSphere vMotion即時遷移測試結果。 (圖片來源:Performance Study – vMotion Innovations in VMware vSphere 7.0 U1)
事實上,VMware官方除了針對剛才大型VM虛擬主機進行測試之外,也針對一般企業和組織中典型的VM虛擬主機,例如12 vCPU和64 GB vRAM,甚至測試超大型的Monster VM虛擬主機,配置192 vCPU和4TB vRAM硬體資源,同樣也採用Oracle資料庫和Hammer DB模擬工作負載。如圖10所示,可以看到不管哪種規格的VM虛擬主機,重構及最佳化的新版vSphere vMotion即時遷移機制,都有2~11倍的提升,甚至超大型的Monster VM虛擬主機更達到19倍的效能提升。
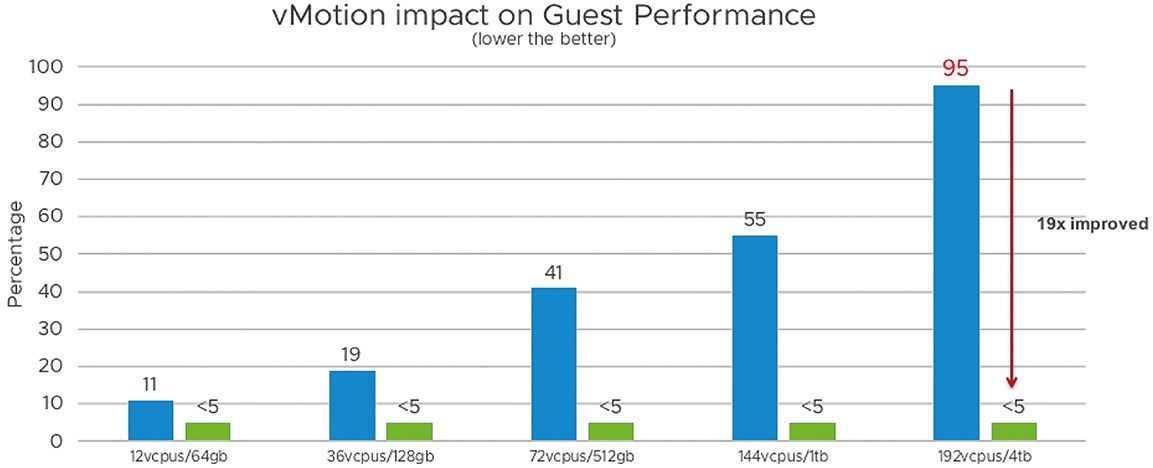 圖10 重構及最佳化的新版vSphere vMotion即時遷移提升數倍效能。 (圖片來源:Performance Study – vMotion Innovations in VMware vSphere 7.0 U1)
圖10 重構及最佳化的新版vSphere vMotion即時遷移提升數倍效能。 (圖片來源:Performance Study – vMotion Innovations in VMware vSphere 7.0 U1)
實戰vCLS(vSphere Clustering Services)
vCLS(vSphere Clustering Services)為最新vSphere 7 Update 1的新增特色功能,這是VMware官方嘗試將vSphere叢集服務和vCenter Server進行脫勾,為vSphere叢集服務建立「分佈式控制平面」(Distributed Control Plane)的第一個版本。
熟悉vSphere基礎架構的管理人員便知,當vSphere基礎架構中vCenter Server發生故障損壞事件時,其上運作的VM虛擬主機和容器等相關工作負載,並不會受到影響且能夠持續運作,然而管理人員也將因為vCenter Server損壞,而無法針對VM虛擬主機和容器等工作負載進行管理作業。
此外,在vCenter Server故障損壞期間,ESXi虛擬化平台中的vSpehre HA Agent仍然能夠正常運作,確保ESXi虛擬化平台若不幸同時發生故障損壞事件時,能夠透過vSphere HA高可用性機制,自動將VM虛擬主機和容器等工作負載,重新啟動在vSphere叢集內其他仍然存活的ESXi虛擬化平台中繼續運作。
對於小型vSphere基礎架構來說,這樣的高可用性機制已經足夠,但是對於中大型的vSphere基礎架構來說就顯得不足。舉例來說,因為vCenter Server發生故障損壞事件時,原本能夠將VM虛擬主機和容器等工作負載自動進行遷移的vSphere DRS(Distributed Resource Scheduler)機制便無法運作。
雖然管理人員可以整合vSphere HA(High Availability)或vCHA(vCenter Server High Availability)高可用性機制,確保vCenter Server管理平台能夠在最短時間內復原上線,繼續擔任vSphere基礎架構管理平台的重任。然而,諸如vSphere DRS、Storage DRS等vSphere叢集服務,仍然圍繞在vCenter Server管理平台身上。
因此,VMware官方打造出vCLS叢集服務,讓vSphere叢集服務和vCenter Server管理平台能夠脫勾。簡單來說,在新版vSphere 7 U1建構的vSphere叢集環境中,當vCenter Server管理平台發生故障損壞事件時,透過vCLS叢集服務能夠讓vSphere DRS等vSphere叢集服務,不因vCenter Server管理平台故障而停擺並且持續運作。
vCLS運作架構
在vCLS叢集服務的運作架構中,如圖11所示,將會在vSphere叢集中建立1~3台vCLS VM虛擬主機,這個特殊的VM虛擬主機,稱為「System VMs」或「Agent VMs」。
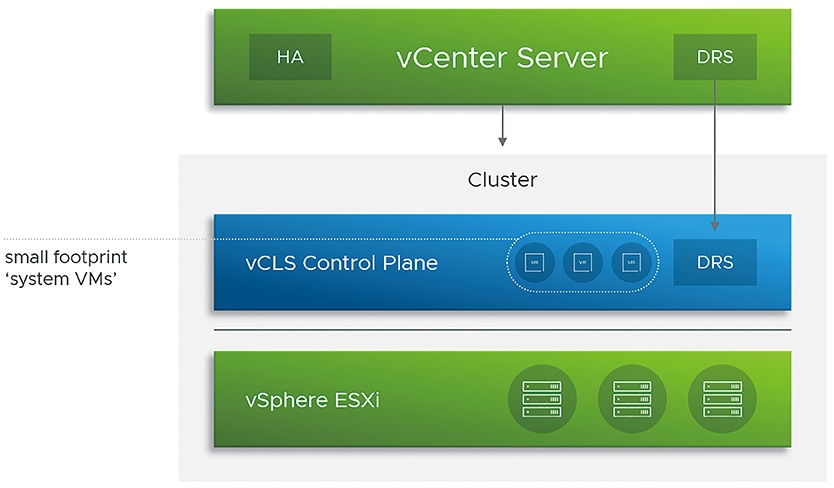 圖11 vCLS叢集服務運作架構示意圖。 (圖片來源:VMware vSphere Blog - vSphere 7 Update 1 - vSphere Clustering Service (vCLS))
圖11 vCLS叢集服務運作架構示意圖。 (圖片來源:VMware vSphere Blog - vSphere 7 Update 1 - vSphere Clustering Service (vCLS))

值得注意的是,vCLS VM虛擬主機並非一般典型的vSphere VM虛擬主機,而是VMware官方透過Photon OS運作的客製化VM虛擬主機,使用非常少的硬體資源,並且必須採用或升級至vCenter Server 7 Update 1版本,系統才會在vSphere叢集中自動部署vCLS VM虛擬主機。
下列為vCLS VM虛擬主機所使用的硬體資源列表:
‧1 vCPU(Reservation 100MHz)
‧128 vRAM(Reservation 100MB)
‧2GB vDisk(Thin Provision)
‧No Ethernet Adapter

倘若vSphere叢集建立時尚未建構共享儲存資源,系統會將vCLS VM虛擬主機部署在ESXi成員主機的本地端儲存資源中,後續管理人員也可透過Storage vMotion將vCLS VM虛擬主機的儲存資源,線上儲存遷移至支援高可用性機制的共享儲存資源中。
部署vCLS VM虛擬主機
當vSphere基礎架構運作環境時,只要採用或升級至vCenter Server 7 Update 1版本,就會發現只要建立vSphere叢集,系統便會依序自動執行「Deploy OVF template > Reconfigure virtual machine > Initialize powering on > Power On virtual machine」等工作任務,如圖12所示,也就是執行自動化部署vCLS VM虛擬主機的動作。
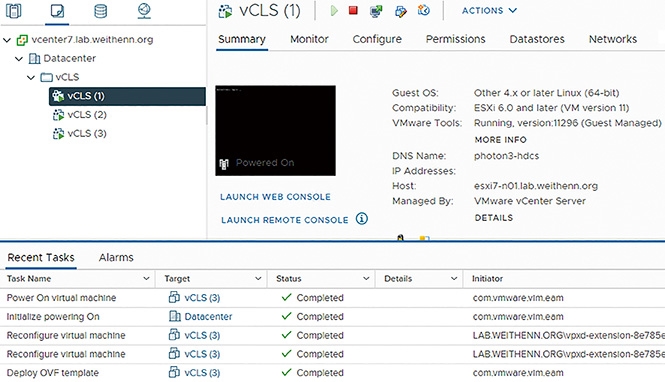 圖12 系統自動部署vCLS VM虛擬主機。
圖12 系統自動部署vCLS VM虛擬主機。

管理人員可以在Cluster層級中,隨時查看vCLS運作的健康狀態。登入vCenter Server管理介面後,依序點選「vCenter Server > Datacenter > Cluster > Summary」項目,展示「Cluster Services」項目後,即可從「Cluster Service health」欄位查看目前的vCLS健康狀態,如圖13所示。以下是vCLS的三種健康狀態和說明:
 圖13 管理人員可隨時查看vCLS健康狀態。
圖13 管理人員可隨時查看vCLS健康狀態。
‧Healthy:健康情況良好。在vSphere叢集中,至少有一台vCLS VM虛擬主機正常運作中,並且為了確保vCLS VM虛擬主機的高可用性,系統將會依據vSphere叢集中ESXi成員主機數量,最多部署3台vCLS VM虛擬主機。
‧Degraded:已降級。在vSphere叢集中,發生至少一台vCLS VM虛擬主機未正常運作,當系統重新部署vCLS VM虛擬主機,或是重新啟動vCLS VM虛擬主機時,vCLS叢集健康情況便會處於此狀態。
‧Unhealthy:不健康。當vCLS控制平台無法使用,並且導致DRS自動化負載平衡機制被跳過時,vCLS叢集健康情況便會處於此狀態。

由於vCLS VM虛擬主機的特殊性,所以當管理介面切換至管理人員常用的「Hosts and Clusters」模式時,將無法看到部署的vCLS VM虛擬主機,必須切換至「VMs and Templates」模式,才會在「vCLS」資料夾下找到已經部署並運作中的vCLS VM虛擬主機。
同時,vCLS VM虛擬主機的部署和維運管理作業,是由系統中的vSphere Cluster Services自動化進行,完全無須管理人員介入。因此,當管理人員切換到任意一台vCLS VM虛擬主機時,即可看到提示訊息,說明vCLS VM虛擬主機的「資源使用、電力狀態、健康狀態」是由vSphere Cluster Services進行維護管理,如圖14所示,並且在Notes中說明vCLS VM虛擬主機的詳細資訊。
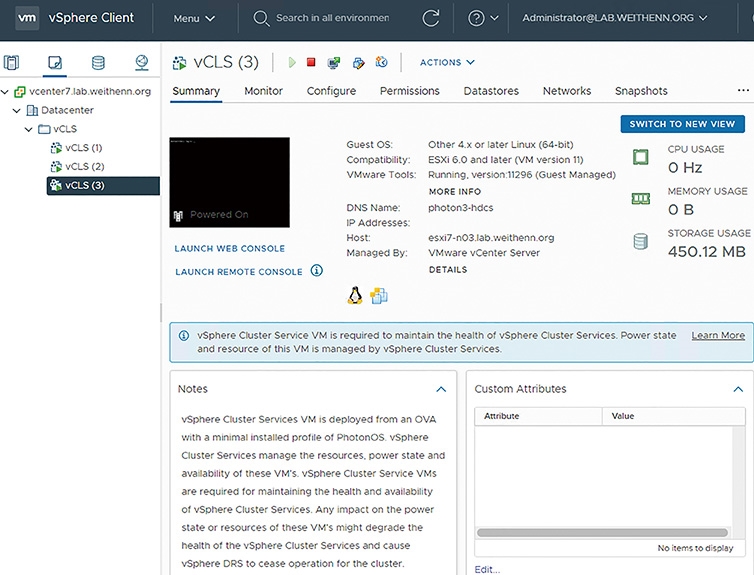 圖14 查看vCLS VM虛擬主機相關資訊。
圖14 查看vCLS VM虛擬主機相關資訊。
因此,如果管理人員嘗試編輯vCLS VM虛擬主機時,系統便會跳出警告訊息,提示管理人員無須人為介入,如圖15所示,因為vCLS VM虛擬主機將由vSphere Cluster Services進行維運管理作業。
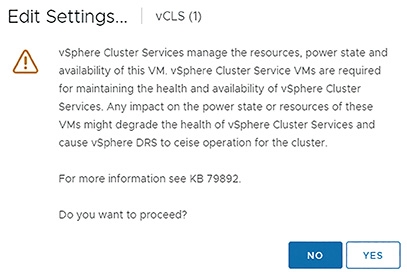 圖15 系統提示管理人員無須人為介入vCLS VM虛擬主機的維運管理作業。
圖15 系統提示管理人員無須人為介入vCLS VM虛擬主機的維運管理作業。
在vCLS VM虛擬主機生命週期管理的部分,由vSphere EAM(ESX Agent Manager)維護管理,如圖16所示。因此,當使用者嘗試刪除或關閉vCLS VM虛擬主機電源時,vSphere EAM將會執行自動「開機」(Power On)或「重新建立」(Re-Create)的動作。
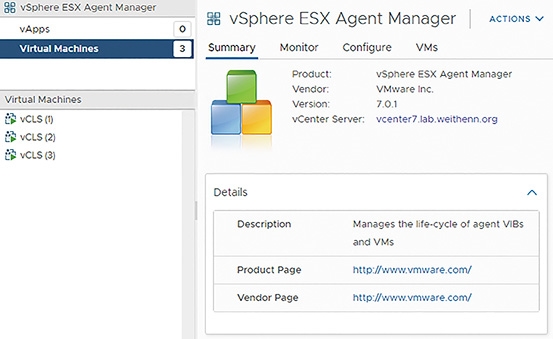 圖16 vCLS VM虛擬主機生命週期由vSphere EAM負責維護管理。
圖16 vCLS VM虛擬主機生命週期由vSphere EAM負責維護管理。
vCLS高可用性測試
如前所述,vCLS VM虛擬主機由vSphere Cluster Services進行維運管理作業,所以管理人員可以手動測試vCLS VM虛擬主機的高可用性。首先,測試強制關閉vCLS VM虛擬主機電源,查看將會發生什麼情況。先點選vCLS VM虛擬主機,再依序點選「Power > Power Off」項目,強制關閉vCLS VM虛擬主機電源,同樣地,當管理人員嘗試強制關閉vCLS VM虛擬主機電源時,系統也會出現警告資訊,並建議管理人員參考VMware KB 79892文件內容(https://kb.vmware.com/s/article/79892)。
管理人員將會發現,手動強制關閉vCLS VM虛擬主機電源後,系統偵測到vCLS VM虛擬主機電源狀態的異動,在10秒鐘之後自動執行「Power On」將vCLS VM虛擬主機自動開機,如圖17所示。
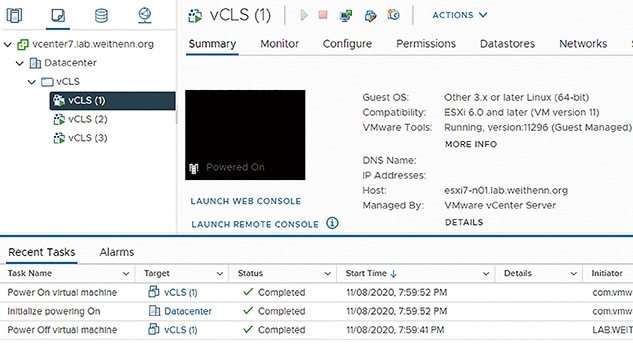 圖17 手動強制關閉vCLS VM虛擬主機電源10秒後系統自動開機。
圖17 手動強制關閉vCLS VM虛擬主機電源10秒後系統自動開機。
在本文實作環境中,vSphere叢集中共有三台ESXi成員主機,因此系統分別在每台ESXi成員主機中部署一台vCLS VM虛擬主機。管理人員可以測試,當vCLS VM虛擬主機所在的ESXi成員主機進入「維護模式」(Maintenance Mode)時,vCLS VM虛擬主機將會如何運作。
在目前vSphere叢集運作環境中,名稱為「vCLS (3)」的vCLS VM虛擬主機,運作在名稱為「esxi7-n03.lab.weithenn.org」的ESXi成員主機中,當ESXi成員主機進入維護模式後,可以看到系統自動將「vCLS (3)」vCLS VM虛擬主機,遷移至「esxi7-n02.lab.weithenn.org」ESXi成員主機上繼續運作,如圖18所示。
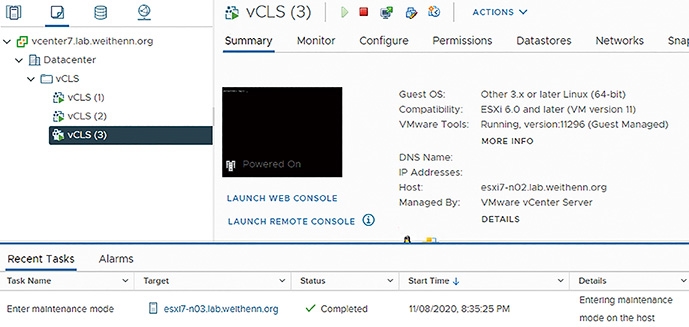 圖18 ESXi成員主機進入維護模式後,vCLS VM虛擬主機自動遷移後繼續運作。
圖18 ESXi成員主機進入維護模式後,vCLS VM虛擬主機自動遷移後繼續運作。

值得注意的是,若vCLS VM虛擬主機採用的儲存資源為ESXi成員主機的「本地儲存資源」時,當ESXi成員主機進入維護模式,則vCLS VM虛擬主機將會執行「Power Off」關機作業,並且在ESXi成員主機離開維護模式時,自動執行「Power On」開機作業。

最後,測試當管理人員強制刪除vCLS VM虛擬主機後,系統是否會執行生命週期維護管理作業,執行重新部署和開機運作等工作任務。先針對名稱為「vCLS (1)」的vCLS VM虛擬主機,強制執行關閉電源的動作,緊接著執行「Delete from Disk」的刪除作業。

從系統工作任務清單中可以看到,當管理人員手動刪除vCLS VM虛擬主機後,在「30秒鐘」之後執行vCLS VM虛擬主機生命週期維護管理作業,自動執行重新部署、組態設定、開機等工作任務,如圖19所示,而重新部署vCLS VM虛擬主機的新名稱為「vCLS (4)」,並且運作在原本「esxi7-n01.lab.weithenn.org」的ESXi成員主機中。
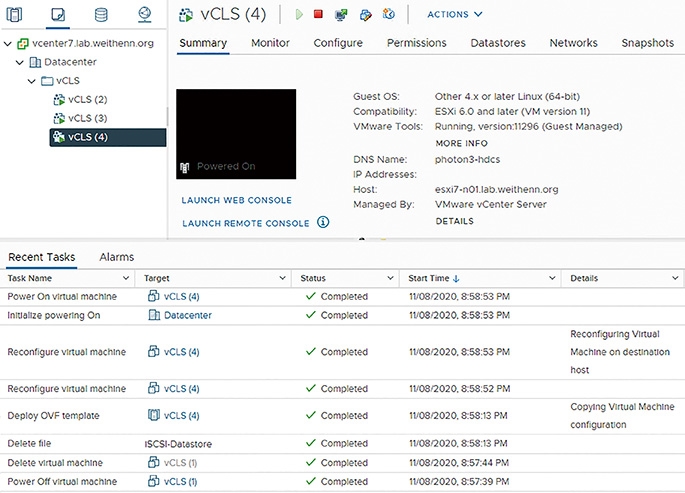 圖19 系統自動執行vCLS VM虛擬主機生命週期維護管理作業。
圖19 系統自動執行vCLS VM虛擬主機生命週期維護管理作業。
結語
透過本文的深入剖析和實作演練後,相信管理人員已經了解到重磅更新的vSphere 7.0 Update 1版本,除了增強原有特色功能之外,更推出同時滿足企業內Dev和Ops人員需要的功能,例如Ops維運人員無須費心導入NSX-T軟體定義網路,採用原有的vDS分佈式交換器,即可打造出滿足Dev開發人員的容器執行環境。
<本文作者:王偉任,Microsoft MVP及VMware vExpert。早期主要研究Linux/FreeBSD各項整合應用,目前則專注於Microsoft及VMware虛擬化技術及混合雲運作架構,部落格weithenn.org。>